Python selenium库爬取淘宝网商品信息
像淘宝这类有着强大的反爬机制的网站来说,其网页内容大多是用Ajax,JavaScript技术动态渲染出来的。如果用request库,即便可以爬取到网页的代码,也不是网页真正的代码。
而使用selenium不仅可以爬取到网页此时呈现的源代码,还可以驱动浏览器进行指定的,模仿人类行为的操作,从而做到了可见即可爬。
一、准备工作
1、确保装备有两个第三方库:selenium和pyquery
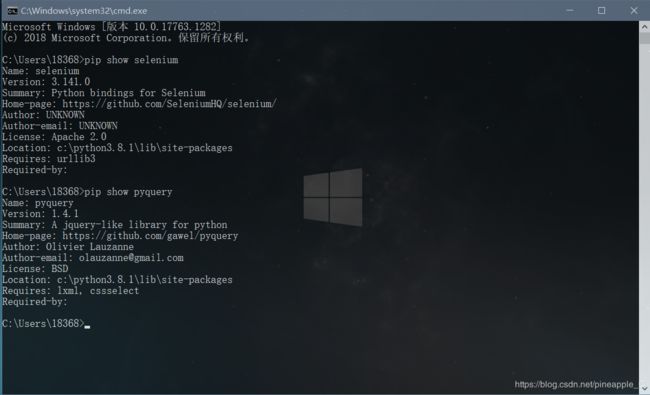
2、
(1)使用Firefox需要下载geckodriver
下载链接:https://github.com/mozilla/geckodriver
如果网速不好,可以选择镜像下载:https://npm.taobao.org/mirrors/geckodriver
如果浏览器是最新版本,选择v0.26.0版本下载

(2)使用Chrome需要下载chromedriver
下载链接:https://chromedriver.storage.googleapis.com/index.html
如果浏览器是最新版本,选择84.0.4147.30版本下载
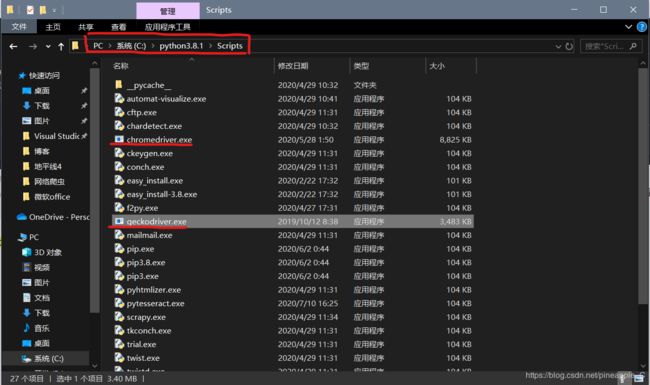
(3)最好放在python/Script文件夹下,这样就不需要配置环境变量。
二、初步分析
(1)了解爬取对象
查看淘宝网的robots协议:https://www.taobao.com/robots.txt
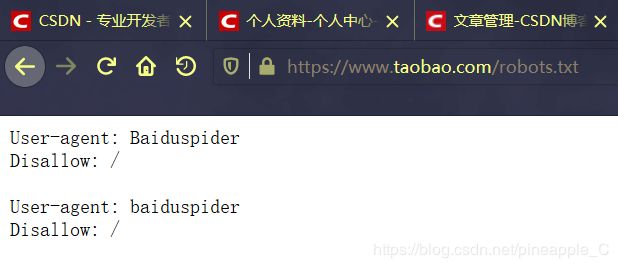
很好,他只针对百度爬虫,我们是可以爬取的,当然这一步可以用程序判断,后面再说。
(2)用户登录
如果单纯的驱动浏览器访问淘宝,是需要用户登陆的。如果不登录,就只能浏览主页,不能购物
例如:
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from urllib.parse import quote
url='https://s.taobao.com/search?q='
# 初始化Firefox浏览器对象
browser=webdriver.Firefox()
# browser=webdriver.Chrome() # Chrome浏览器
browser.get(url+quote('python书')) # 在搜索栏输入商品后的url
WebDriverWait(browser,10)
出现的页面是这样的
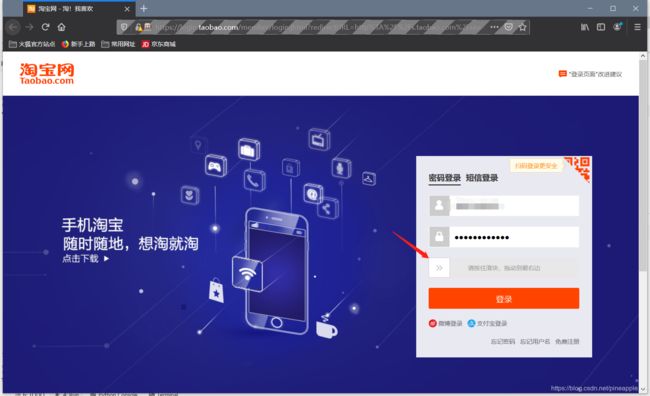 需要输入用户名和密码,还需要滑块验证。除了这些,其它的验证码,文字识别,拼图等高端操作都是可以用selenium库搞定的。但是我还没有研究到那里。
需要输入用户名和密码,还需要滑块验证。除了这些,其它的验证码,文字识别,拼图等高端操作都是可以用selenium库搞定的。但是我还没有研究到那里。
思考一下,有没有其他的方法呢?单纯的驱动浏览器是没有任何用户配置的,插件,浏览记录,书签都没有,就是一个全新的浏览器。如果我之前就打开过淘宝并且登陆,淘宝网便会保存我的使用记录,那何不直接驱动带有用户配置的浏览器呢?这样就不需要再考虑伪装头部,cookies等问题。
例如:(Firefox浏览器)
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
from urllib.parse import quote
# 配置文件地址
profile_directory = r'C:\Users\18368\AppData\Roaming\Mozilla\Firefox\Profiles\x9hlgi1i.dev-edition-default'
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
browser = webdriver.Firefox(profile)
url='https://s.taobao.com/search?q='
browser.get(url+quote('python书'))
WebDriverWait(browser,10)
每个人的配置文件地址是不同的,在搜索框中输入about:support即可看到自己的相关配置
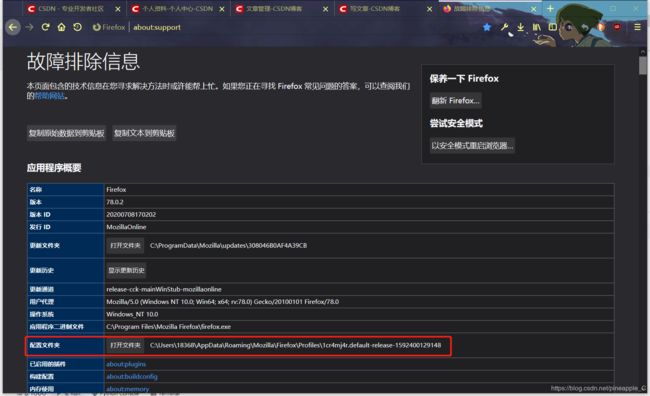
运行后出现的页面是这样的:
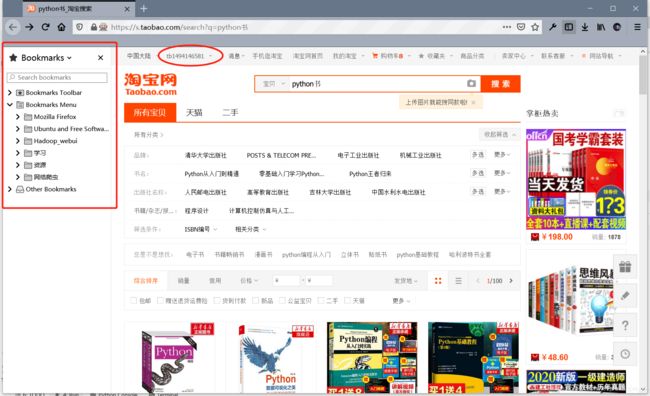 可以发现书签,用户信息等都在
可以发现书签,用户信息等都在
如果使用Chrome浏览器的话,有两种方式
方式1):控制已经打开的Chrome
cmd输入以下命令:
C:\Program Files (x86)\Google\Chrome\Application>chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\selenum\AutomationProfile"
打开一个远程调试端口(端口自己定),在本地创建一个Chrome配置目录,这样就不会影响源目录。
在上述命令打开的浏览器里访问淘宝,登陆并搜索python书
然后运行如下代码
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
# 初始化浏览器选项对象
chrome_options = Options()
# 添加拓展选项,指定调试端口
chrome_options.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
# driver = webdriver.Chrome(chrome_options=chrome_options)
# selenium3.141.0 python3.8.1出现弃用警告
# DeprecationWarning: use options instead of chrome_options
# 将chrome_options换成options
driver = webdriver.Chrome(options=chrome_options)
print(driver.find_element_by_id('J_Itemlist_TLink_564162841422').text)
输出结果:下单优惠正版 python基础教程 零基础学Python编程从入门到实践计算机程序设计pathon3核心技术网络爬虫书籍数据分析实战教程教材(第一本书的书名)
验证通过,可以使用这种方法。
方式2):加载所有Chrome浏览器配置
from selenium.webdriver.support.ui import WebDriverWait
from selenium import webdriver
option = webdriver.ChromeOptions()
p = r'C:\Users\18368\AppData\Local\Google\Chrome\User Data'
option.add_argument('--user-data-dir=' + p) # 设置成用户自己的数据目录
driver = webdriver.Chrome(options=option) # chrome_options已弃用
driver.get('https://www.taobao.com')
WebDriverWait(driver,10)
运行前如果Chrome浏览器已开启,会出现invalid argument: user data directory is already in use, please specify a unique value for --user-data-dir argument, or don't use --user-data-dir的错误,原因是配置目录已经在使用,所以运行前要关闭Chrome。
运行结果:下单优惠正版 python基础教程 零基础学Python编程从入门到实践计算机程序设计pathon3核心技术网络爬虫书籍数据分析实战教程教材(第一本书的书名)
Firefox和Chrome一共三种方法。本文选择用Firefox。(使用Chrome浏览器的话,可以使用上文的两种方法)
三、编写程序
1、相关依赖
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from pyquery.pyquery import PyQuery as pq
from urllib.parse import quote
from selenium import webdriver
import json
| inport | 作用 |
|---|---|
| EC | 等待条件 |
| WebDriverWait | 设置最长等待时间 |
| TimeoutException | 超时异常 |
| By | 查找结点的条件 |
| pq | 适合使用CSS选择器的一个网页解析库 |
| quote | 将参数转化为URL编码格式,解决中文参数乱码问题 |
| webdriver | 初始化浏览器对象 |
| json | 以json的形式保存文件 |
2、全局变量
# 配置文件地址
profile_directory = r'C:\Users\18368\AppData\Roaming\Mozilla\Firefox\Profiles\x9hlgi1i.dev-edition-default'
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
browser = webdriver.Firefox(profile)
# 设置等待时间,10s
wait = WebDriverWait(browser, 10)
KEYWORD = 'Python书' # 爬取对象
RESULT = [] # 爬取结果
MAX_PAGE = 10 # 爬取页数
3、翻页函数
def index_page(page):
"""
执行翻页的操作,如果出错,则重新执行
:param page: 页码
:return: 无
"""
print('正在爬取第{}页'.format(page))
try:
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
# 保存爬取到的网页源代码,以对比验证是否正确
# html=browser.page_source
# with open('taobao.html','w',encoding='utf-8')as file:
# file.write(html)
if page > 1:
# 等待class属性值为 'J_Input'的结点加载出来
input = wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'J_Input'))
)
# 等待class属性值为'J_Submit'的结点可以被点击
submit = wait.until(
EC.element_to_be_clickable((By.CLASS_NAME, 'J_Submit'))
)
# 通过JavaScript修改结点的属性值
browser.execute_script("arguments[0].setAttribute('value','{}');".format(str(page)), input)
submit.click()
# 等待网页全部加载完成,使用CSS选择器查找
wait.until(EC.text_to_be_present_in_element((
By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)
))
wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, '.m-itemlist .items'
)))
get_products()
except TimeoutException:
index_page(page)
首次运行可以去掉注释部分的代码,设置页码page为1,用以检验爬取结果是否正确。
if条件语句用来判断当页码大于1时,进行翻页操作。
首先设定最大等待时间,input:找到 “跳转” 结点;submit:等待“确定”结点可以被点击。
我们可以在爬取结果中搜索 “跳转” 结点的class属性 ‘J_Input’,顺便还可以检验爬取结果的正确性
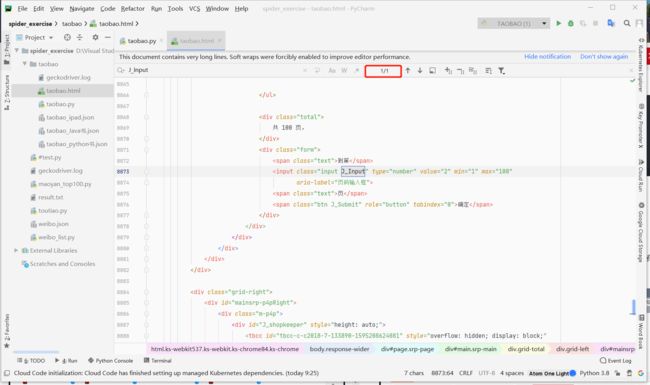 发现只有 “跳转” 结点有这个属性值,所以我们可以根据class属性来查找,同理 “确定” 结点也是如此。
发现只有 “跳转” 结点有这个属性值,所以我们可以根据class属性来查找,同理 “确定” 结点也是如此。
接着找到跳转的输入框,只发现了到第和页,就是没有中间的页码
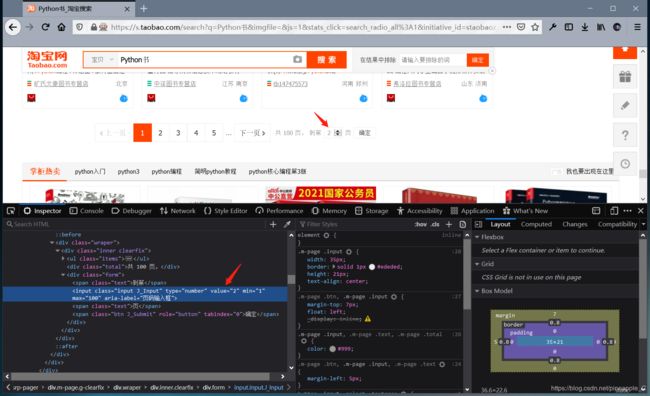 多翻几页可以找到规律,页码是夹在结点的value属性里的,是通过JavaScript修改的。需要利用execute_script()方法模拟执行JavaScript操作。
多翻几页可以找到规律,页码是夹在结点的value属性里的,是通过JavaScript修改的。需要利用execute_script()方法模拟执行JavaScript操作。
这里没有采用点击下一页的操作,这样翻页虽然简单,但是如果出现异常,上一页和下一页的按钮都没有加载出来,就无法重新开始这一页和继续下一页,程序也会因此退出。而且在翻页的同时还要记录页数,这就有点不方便了。所以采用跳转页面的方式,这样即使出现异常也可以快速的重新开始。
最后根据当前页码变色和商品信息加载完毕来判断网页加载完成。因为结点的属性并不唯一且位置结构比较复杂,所以用CSS选择器来查找结点。确定无误后,进入下一个函数get_products()进行信息筛选。
4、筛选信息
def get_products():
"""
使用puquery筛选商品的图片、价格、成交人数等信息
:return: 无
"""
html = browser.page_source
doc = pq(html)
# 找到本页商品列表的结点
items = doc('#mainsrp-itemlist .item').items()
for item in items:
product = {
'image': 'https:' + item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
RESULT.append(product)
5、信息保存
def save_to_json():
"""
将爬取下来的信息以json的形式保存
:return: 无
"""
print('\n爬取工作完成,一共{}个商品'.format(len(RESULT)))
print('开始写入文件taobao_{}.json......'.format(KEYWORD))
with open('taobao_{}.json'.format(KEYWORD), 'w', encoding='utf-8')as file:
file.write(json.dumps(RESULT, ensure_ascii=False))
6、遍历每一页
def main():
"""
遍历每一页
:return: 无
"""
for i in range(1, MAX_PAGE + 1):
index_page(i)
save_to_json()
四、完整代码
基于PyCarm、python3.8.1、selenium3.141.0、pyquery1.4.1
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:[email protected]
@time:2020/7/19 17:05
@file:taobao.py
@desc:Use python web crawler to get product information on Taobao,
learn from https://github.com/Python3WebSpider/TaobaoProduct.
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from pyquery.pyquery import PyQuery as pq
from urllib.parse import quote
from selenium import webdriver
import json
# 配置文件地址
profile_directory = r'C:\Users\18368\AppData\Roaming\Mozilla\Firefox\Profiles\x9hlgi1i.dev-edition-default'
# 加载配置
profile = webdriver.FirefoxProfile(profile_directory)
# 启动浏览器配置
browser = webdriver.Firefox(profile)
# 设置等待时间,10s
wait = WebDriverWait(browser, 10)
KEYWORD = 'Python书' # 爬取对象
RESULT = [] # 爬取结果
MAX_PAGE = 10 # 爬取页数
def index_page(page):
"""
执行翻页的操作,如果出错,则重新执行
:param page: 页码
:return: 无
"""
print('正在爬取第{}页'.format(page))
try:
url = 'https://s.taobao.com/search?q=' + quote(KEYWORD)
browser.get(url)
# 保存爬取到的网页源代码,以对比验证是否正确
# html=browser.page_source
# with open('taobao.html','w',encoding='utf-8')as file:
# file.write(html)
if page > 1:
# 等待class属性为'J_Input'的结点加载出来
input = wait.until(
EC.presence_of_element_located((By.CLASS_NAME, 'J_Input'))
)
# 等待class属性值为'J_Submit'的结点可以被点击
submit = wait.until(
EC.element_to_be_clickable((By.CLASS_NAME, 'J_Submit'))
)
# 通过JavaScript修改结点的属性值
browser.execute_script("arguments[0].setAttribute('value','{}');".format(str(page)), input)
submit.click()
# 等待网页全部加载完成,使用CSS选择器查找
wait.until(EC.text_to_be_present_in_element((
By.CSS_SELECTOR, '#mainsrp-pager li.item.active > span'), str(page)
))
wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, '.m-itemlist .items'
)))
get_products()
except TimeoutException:
index_page(page)
def get_products():
"""
筛选商品的图片、价格、成交人数等信息
:return: 无
"""
html = browser.page_source
doc = pq(html)
# 找到本页商品列表的结点
items = doc('#mainsrp-itemlist .item').items()
for item in items:
product = {
'image': 'https:' + item.find('.pic .img').attr('data-src'),
'price': item.find('.price').text(),
'deal': item.find('.deal-cnt').text()[:-3],
'title': item.find('.title').text(),
'shop': item.find('.shop').text(),
'location': item.find('.location').text()
}
RESULT.append(product)
def save_to_json():
"""
将爬取下来的信息以json的形式保存
:return: 无
"""
print('\n爬取工作完成,一共{}个商品'.format(len(RESULT)))
print('开始写入文件taobao_{}.json......'.format(KEYWORD))
with open('taobao_{}.json'.format(KEYWORD), 'w', encoding='utf-8')as file:
file.write(json.dumps(RESULT, ensure_ascii=False))
def main():
"""
遍历每一页
:return: 无
"""
for i in range(1, MAX_PAGE + 1):
index_page(i)
save_to_json()
if __name__ == '__main__':
main()
结果展示(以python书为例)
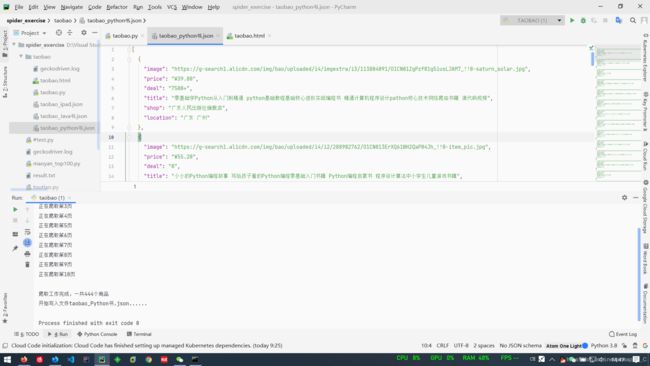 我们可以计算一下数目来验证是不是爬取了10页,除了第一页是12行+4列外,其他都是11行加4列,11 * 4 * 9 + 12 * 4 = 444。正好!
我们可以计算一下数目来验证是不是爬取了10页,除了第一页是12行+4列外,其他都是11行加4列,11 * 4 * 9 + 12 * 4 = 444。正好!
刚打开文件时会有一点乱,按下CTRL+ALT+L代码对齐即可。
五、结语
这几天看崔庆才老师的书《Python3网络爬虫开发实战》,受益颇深。
这本书已经出版三年了,当时的网页源码与现在有些不同,淘宝的反爬机制也是越来越强大。于是为了还是能爬取到相关信息,我在结合了已学知识的同时,又拓展一些selenium库的其他操作,对源代码进行了修改。
当然,也有一些大神对源码做了修改,并且放到了issue里。甚至还有用微博登陆的奇葩思路。
github链接:https://github.com/Python3WebSpider/TaobaoProduct
分享一下崔老师的博客:https://cuiqingcai.com/
一起互相学习,共同进步吧!
如有错误,欢迎私信纠正
技术永无止境,谢谢支持