《推荐系统开发实战》之基于用户行为特征的推荐算法介绍和案例实战开发
转载请注明出处:http://blog.csdn.net/gamer_gyt
博主微博:http://weibo.com/234654758
Github:https://github.com/thinkgamer
公众号:搜索与推荐Wiki
个人网站:http://thinkgamer.github.io
推荐系统的受众对象为用户,只有明白用户的意图,才能给用户推荐更好的内容。基于用户行为特征的推荐,其实在真正的“个性化推荐系统”诞生之前就已经存在了。最简单的就是各种排行榜,它们基于简单的用户统计,又对其他选择提供一定的指引。
用户行为分类
用户行为分为两种——显性反馈行为和隐性反馈行为。
- 显性反馈行为
显性反馈行为是指,用户很明显地表达出自己的喜好,如对内容评分、表示喜欢/不喜欢等。例如,豆瓣电影中的评分机制和YouTube中的“点赞”功能都是典型的显性反馈。
- 隐性反馈行为
隐性反馈行为是指,用户不明确表达出自己的喜好信息。例如,用户在京东APP中的商品浏览日志、在网易云上听歌的日志等,实际上京东和网易已经得到了一定的用户行为数据,但没有以显性方式直接反馈,而是在其他地方间接地反馈出来。
疑问:显性反馈行为 和 隐性反馈行为的区别是什么?
基于内容的推荐算法
基于内容的推荐算法,根据用户过去一段时间内喜欢的物品,以及由此推算出来用户偏好,为用户推荐相似物品。其中的“内容”指的便是:用户过去一段时间内喜欢的物品,以及由此推算出来的用户偏好。
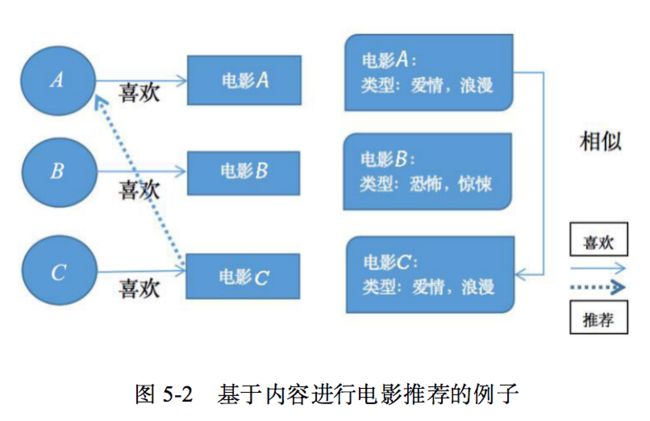
图5-2所示是一个基于内容推荐的例子,用户A和用户C喜欢爱情、浪漫类型的电影,用户B喜欢恐怖、惊悚的电影,因此将类型为爱情、浪漫且用户A没有行为的电影C推荐给用户A。
原理分析
基于内容(Content Based,CB)的推荐原理非常简单:向用户推荐所喜欢的Item的相似Item。其中包含了三步:
(1)构造Item的特征;
在真实应用场景中,往往会用一些属性描述Item的特征,这些属性通常分为以下两种:
- 结构化属性:意义比较明确,其取值固定在某个范围内。
- 非结构化属性:特性意义相对不太明确,取值没有什么限制,不可以直接使用
(2)计算Item之间的相似度;
在确定好Item的特征和用户的偏好模型后,需要计算两个Item间的相似度。根据具体场景,往往需要使用不同的相似度计算方法。
疑问:相似度计算方法有哪些?
(3)评判用户是否喜欢某个Item。
在推荐算法中评判用户是否喜欢某个Item就是:利用监督学习或非监督学习的方法,来评判用户喜欢哪些Item,不喜欢哪些Item,从而根据用户的喜好,为他生成一个偏好模型,进而对未知的Item进行喜好评判。
在基于内容的推荐算法中,使用的则是监督学习,利用用户对Item的已知评分和Item所属的类别,学习得到用户对每种类型的偏好程度,然后结合Item的类别特征计算用户对Item的偏好程度。
疑问:监督学习和非监督学习的区别?
实际案例
利用基于内容的推荐算法编写一个电影推荐系统,当用户在浏览某部电影时,为其推荐所浏览电影的相似电影。其实现步骤如下:
- 构建电影的特征信息矩阵
- 构建用户的偏好信息
- 计算用户与每部电影的距离
介于篇幅原理这里的具体实现步骤和代码不再赘述,欢迎关注《推荐系统开发实战》一书。
基于近邻的推荐算法
基于近邻的推荐算法是比较基础的推荐算法,在学术界和工业界应用十分广泛。这里讨论的基于近邻的推荐算法指的是协同过滤(Collaborative Filtering)算法。
基于近邻的协同过滤推荐算法分为:
- 基于用户的协同过滤(User-CF-Based)算法
- 基于物品的协同过滤(Item-CF-Based)算法
关于协同过滤,一个最经典的例子就是看电影:有时不知道哪一部电影是我们喜欢的或评分比较高的,通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在询问时,都习惯于问与自己品味差不多的朋友,这就是协同过滤的核心思想。
UserCF算法
原理分析
基于用户的协同过滤通过用户的历史行为数据发现用户喜欢的物品,并对这些偏好进行度量和打分,然后根据不同用户对相同物品的评分或偏好程度来评测用户之间的相似性,对有相同偏好的用户进行物品推荐。
简单地讲,基于用户的协同过滤就是给用户推荐“和他兴趣相投的其他用户”喜欢的物品。
图5-5所示是一个基于用户的协同过滤推荐的例子,用户A和用户C同时喜欢电影A和电影C,用户C还喜欢电影D,因此将用户A没有表达喜好的电影D推荐给用户A。
又如,现在有A、B、C、D四个用户,分别对a、b、c、d、e五个物品表达了自己喜好程度(通过评分的高低来表现自己的偏好程度高低),现在要为C用户推荐物品:
(1)计算得到C用户的相似用户;
(2)找到这些相似用户喜欢的但C没有进行过评分的物品并推荐给C。

实际案例
利用UserCF编写一个电影推荐系统,根据被推荐用户的相似用户的喜好,为被推荐用户推荐电影。
介于篇幅原理这里的具体实现步骤和代码不再赘述,欢迎关注《推荐系统开发实战》一书。
ItemCF算法
原理分析
基于物品的协同过滤推荐则通过不同对item的评分来评测item之间的相似性,从而基于item的相似性做推荐。
简单地讲就是,给用户推荐他之前喜欢物品的相似物品。
从原理上理解可以得知:基于item的协同过滤推荐和被推荐用户的偏好没有直接关系。例如,用户A买了一本书a,那么会给用户A推荐一些和书a相似的书。这里要考虑的是如何衡量两本书的相似度。
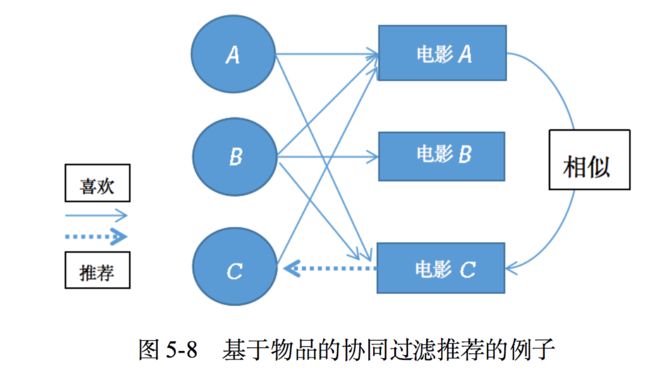
图5-8所示是一个基于物品的协同过滤推荐的例子,用户C喜欢电影A,电影C和电影A相似,那么便把用户C没有表达喜好的电影C推荐给用户C。
实际案例
利用ItemCF算法编写一个推荐系统,当用户进行电影浏览时,向用户推荐和该部电影相似的电影。
介于篇幅原理这里的具体实现步骤和代码不再赘述,欢迎关注《推荐系统开发实战》一书。
对比分析
UserCF与ItemCF
从用适用场景、推荐系统多样性、用户特点对推荐的影响三方面来分析下两者的对比。
在适用场景上的比较
ItemCF算法利用物品间的相似性来推荐,所以当用户数量远远超过物品数量时,可以考虑使用ItemCF算法。例如,购物网站和技术博客网站的商品或文章数据相对稳定,因此计算物品相似度时不但计算量小,而且不必频繁进行更新。
UserCF算法利用用户间的相似性来推荐,所以当物品数量远远超过用户数量时,可以考虑UserCF算法。UserCF算法更适合新闻类和短视频类等快消素材网站。例如,在社交网站中,UserCF是一个不错的选择,而且可解释性也更强。因为这类网站的内容更新比较频繁,且用户更加注重社会化热点。
举例:略~
在推荐系统多样性上的比较
单用户的多样性方面:ItemCF算法不如UserCF算法多样性丰富。因为,ItemCF算法推荐的是和之前有行为物品的相似物品,物品覆盖面比较小,丰富度低。
系统的多样性方面:ItemCF算法的多样性要远远好于UserCF算法。因为,UserCF算法更加注重推荐热门物品。
ItemCF算法的推荐有很好的新颖性,容易发现并推荐长尾里的物品。所以大多数情况下,ItemCF算法的精度稍微小于UserCF算法。如果考虑多样性,ItemCF算法比UserCF算法好很多。而ItemCF算法只推荐A领域给用户,这样有限的推荐列表中就可能包含了一定数量的不热门的长尾物品。
由于UserCF算法经常推荐热门的物品,所以它在推荐长尾里的物品方面能力不足。
在用户特点上的比较
(1)UserCF算法推荐的原则是“假设用户喜欢那些和他有相同喜好的用户喜欢的东西”。但是,如果用户暂时找不到兴趣相同的邻居,那么基于用户的推荐效果就打了大打折扣了。
因此,用户是否适应UserCF,与“他有多少邻居”是成正比的。
(2) 基于物品的协同过滤算法的前提是“用户喜欢和他以前购买过的物品类型相同的物品”,可以计算一个用户喜欢的物品的自相似度。
- 一个用户喜欢物品的自相似度大,即用户喜欢的物品的相关度大,则说明他喜欢的东西是比较相似的。即,这个用户比较符合ItemCF算法的基本假设,他对ItemCF算法的适应度比较好。
- 反之,如果自相似度小,即用户喜欢物品的相关度小,就说明这个用户的喜好习惯并不满足ItemCF算法的基本假设,那么用ItemCF算法所做出的推荐对于这种用户来说效果可能不是很好。
基于内容与基于近邻
基于内容(Content-Based,CB)的推荐算法和基于物品(Item-Based,IB)的协同过滤算法十分相似,因为两种算法都在Item的基础上进行相似度计算。
但是两者基于的Item特征是不一样的:
- 基于内容的推荐算法中,计算用户相似度用的是Item本身的特征。
- 基于物品的协同过滤算法中,则用“用户对Item的行为”来构造Item的特征。
举例:略~
基于隐语义模型的推荐算法
原理分析
从矩阵的角度来理解,LFM原理矩阵表示图如图5-12所示。
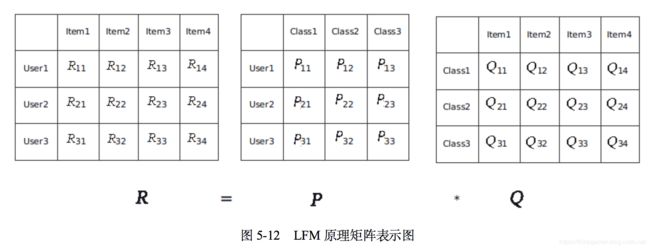
- R矩阵表示用户对物品的偏好信息。其中,R_ij代表User i对Item j的兴趣度。
- P矩阵表示用户对各物品类别的一个偏好信息。其中,P_ij代表User i对Class j的兴趣度。
- Q矩阵表示各个物品归属到各个类别的信息。其中,Q_ij代表Item j在Class i中的权重或概率。
隐语义模型就是要将矩阵R分解为P和Q的乘积,即通过矩阵中的物品类别(Class)将用户User和物品Item联系起来。实际上需要根据用户当前的物品偏好信息R进行计算,从而得到对应的矩阵P和矩阵Q。
从上述矩阵转换关系中可以得到隐语义模型计算用户对物品兴趣度的公式:
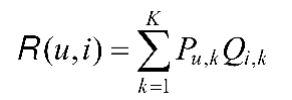
其中参数说明如下。 - Pu,k:用户u兴趣和第k个隐类的关系。
- Qi,k:第k个隐类和物品i的关系。
- k:隐类的数量。
- R:用户对物品的兴趣度。
疑问:LFM解决的问题是什么?LFM的样本集问题?LFM的推导?LFM的优缺点?请持续关注《推荐系统开发实战》
实际案例
编写一个基于隐语义模型的电影推荐系统。当用户在浏览电影并表达自己的兴趣后,系统向用户推荐用户可能喜欢的电影。
其实现思路如下:
(1)初始化用户对每个隐分类的兴趣度矩阵P,以及每个物品与每个隐分类的匹配程度矩阵Q;
(2)根据训练数据集指定损失函数,迭代更新矩阵P和Q;
(3)使用测试机对模型结果进行测试。
由于篇幅原因,具体的代码实现和过程,这里不过多介绍,请参考《推荐系统开发实战》
注:《推荐系统开发实战》是小编近期要上的一本图书,预计本月(7月末)可在京东,当当上线,感兴趣的朋友可以进行关注!

