C Primer Plus--- Chapter 16---The C Preprocessor and the C Library ---1. 预处理器
C Primer Plus--- Chapter 16---The C Preprocessor and the C Library ---1. 预处理器
- 1. 翻译程序的第一步
- 2. 明示常量: #define
- 2.1 define 与 const
- 2.2 记号(token)
- 2.3 重定义常量
- 3. 在#define中使用参数
- 3.1 用宏参数创建字符串: #运算符
- 3.2 预处理器黏合剂: ##运算符
- 3.3 变参宏: ... 和 _ _VA_ARGS_ _
- 4. 宏和函数的选择
预处理器(preprocessor)在编译之前执行,它识别带 # 字符的语句,根据内容修改程序。
如遇到 #include
遇到 #define len 4 时将程序中的 len 用 4 代替。
预处理器并不知道c语句,因此这些语句没有分号结尾。
1. 翻译程序的第一步
在预处理之前, 编译器必须对该程序进行一些翻译处理。
首先, 编译器把源代码中出现的字符映射到源字符集。 该过程处理多字节字符和三字符序列——字符扩展让C更加国际化。
第二, 编译器定位每个反斜杠后面跟着换行符的实例, 并删除它们。 也
就是说, 把下面两个物理行(physical line) :
printf("That's wond\
erful!\n");
转换为:
printf("That's wonderful\n!");
注意, 在这种场合中, “换行符”的意思是通过按下Enter键在源代码文件
中换行所生成的字符, 而不是指符号表征\n。
由于预处理表达式的长度必须是一个逻辑行, 所以这一步为预处理器做
好了准备工作。 一个逻辑行可以是多个物理行。
第三, 编译器把文本划分成预处理记号序列、 空白序列和注释序列(记
号是由空格、 制表符或换行符分隔的项) 。 这里要注意的是,编译器将用一个空格字符替换每一条注释。
而且, 实现可以用一个空格替换所有的空白字符序列(不包括换行符) 。
最后, 程序已经准备好进入预处理阶段, 预处理器查找一行中以#号
开始的预处理指令。
2. 明示常量: #define
#define预处理器指令和其他预处理器指令一样, 以#号作为一行的开
始。
指令可以出现在源文件的任何地方, 其定义从指令出现的地方到该文件末尾有效。
预处理器指令从#开始运行, 到后面的第1个换行符为止。 也就是说, 指
令的长度仅限于一行。 然而, 前面提到过, 在预处理开始前, 编译器会把多行物理行处理为一行逻辑行。
每行#define(逻辑行) 都由3部分组成。 第1部分是#define指令本身。 第2部分是选定的缩写, 也称为宏。 有些宏代表值 ,如:
#defene LEN 4
这些宏被称为类对象宏(object-like macro) 。
语言还有类函数宏(function-like macro)。
宏的名称中不允许有空格, 而且必须遵循C变量的命名规则: 只能使用字符、 数字和下划线(_) 字符, 而且首字符不能是数字。
第3部分(指令行的其余部分) 称为替换列表或替换体。
一旦预处理器在程序中找到宏的示实例后, 就会用替换体代替该宏(也有例外, 稍后解释) 。
从宏变成最终替换文本的过程称为宏展开(macro expansion) 。
注意, 可以在#define行使用标准C注释。 如前所述, 每条注释都会被一个空格代替。
2.1 define 与 const
C语言现在也支持const关键字, 提供了更灵活的方法。 用const可以创建
在程序运行过程中不能改变的变量, 可具有文件作用域或块作用域。
另一方面, 宏常量可用于指定标准数组的大小和const变量的初始值。
#define LIMIT 20
const int LIM = 50;
static int data1[LIMIT]; // valid
static int data2[LIM]; // not required to be valid无效
const int LIM2 = 2 * LIMIT; // valid
const int LIM3 = 2 * LIM; // not required to be valid
关于上面代码中的“无效”注释。 在C中, 非自动数组的大小应该是整型常量表达式, 这意味着表示数组大小的必须是整型常量的组合(如5) 、 枚举常量和sizeof表达式, 不包括const声明的值(这也是C++和C的区别之一, 在C++中可以把const值作为常量表达式的一部分) 。
2.2 记号(token)
从技术角度来看, 可以把宏的替换体看作是记号(token) 型字符串,
而不是字符型字符串。
C预处理器记号是宏定义的替换体中单独的“词”。 用空白把这些词分开。 例如:
#define FOUR 2*2
有一个记号:2*2
#define SIX 2 * 3
有三个记号,2,*, 2
替换体中有多个空格时, 字符型字符串和记号型字符串的处理方式不
同。
#define EIGHT 4 * 8
如果预处理器把该替换体解释为字符型字符串, 将用4 * 8替EIGHT。
即, 额外的空格是替换体的一部分。
如果预处理器把该替换体解释为记号型字符串, 则用3个的记号4 * 8(分别由单个空格分隔) 来替换EIGHT。
即, 解释为字符型字符串, 把空格视为替换体的一部分;
解释为记号型字符串, 把空格视为替换体中各记号的分隔符。
在实际应用中, 一些C编译器把宏替换体视为字符串而不是记号。
2.3 重定义常量
假设先把LIMIT定义为20, 稍后在该文件中又把它定义为25。 这个过程
称为重定义常量。 不同的实现采用不同的重定义方案。 除非新定义与旧定义相同, 否则有些实现会将其视为错误。
具有相同的定义意味着替换体中的记号必须相同, 且顺序也相同。 因
此, 下面两个定义相同:
#define SIX 2 * 3
#define SIX 2 * 3
这两条定义都有 3 个相同的记号, 额外的空格不算替换体的一部分。 而
下面的定义则与上面两条宏定义不同:
#define SIX 2*3
这条宏定义中只有一个记号, 因此与前两条定义不同。 如果需要重定义
宏, 使用#undef 指令。
3. 在#define中使用参数
在#define中使用参数可以创建外形和作用与函数类似的类函数宏。 带有
参数的宏看上去很像函数, 因为这样的宏也使用圆括号。 类函数宏定义的圆
括号中可以有一个或多个参数, 随后这些参数出现在替换体中, 见下图:
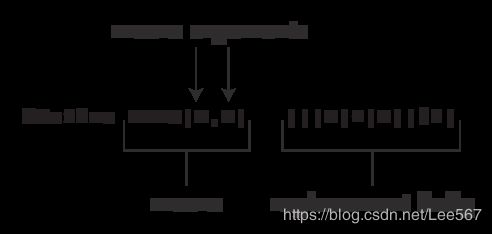
例子:
#define SQUARE(X) X*X
这里, SQUARE 是宏标识符, SQUARE(X)中的 X 是宏参数, X*X 是替
换列表。
如果 x 为 2,则 SQUARE(2) 为 2 * 2 = 4;
如果 x 为 2,则 SQUARE(X+2) 为 x + 2 * x + 2 = 8,并非为 4 * 4,因为预处理器不做计算、 不求值, 只替换字符序列。
3.1 用宏参数创建字符串: #运算符
下面是一个类函数宏:
#define PSQR(X) printf("The square of X is %d.\n", ((X)*(X)));
假设这样使用函数宏:
PSQR(8);
输出:
The square of X is 64.
注意双引号字符串中的X被视为普通文本, 而不是一个可被替换的记
号。
C允许在字符串中包含宏参数。 在类函数宏的替换体中, # 号作为一个预处理运算符, 可以把记号转换成字符串。 例如, 如果x是一个宏形参, 那么 #x 就是转换为字符串"x"的形参名。 这个过程称为字符串化(stringizing) 。
将上述定义改为:
#define PSQR(x) printf("The square of " #x " is %d.\n",((x)*(x)))
则如下使用:
PSQR(y);
PSQR(2 + 4);
输出:
The square of y is 25.
The square of 2 + 4 is 36.
在第一个宏调用中, #x 被转换为字符串 “y”,第二个被转换为 “2 + 4”,因此原语句变为:
printf("The square of " "y" " is %d.\n",((y)*(y)));
printf("The square of " "2 + 4" " is %d.\n",((y)*(y)));
因为,如果一对双引号中间只有空白字符,会被忽略,因此语句变为:
printf("The square of y is %d.\n",((y)*(y)));
printf("The square of 2 + 4 is %d.\n",((y)*(y)));
3.2 预处理器黏合剂: ##运算符
与#运算符类似, ##运算符可用于类函数宏的替换部分。 而且, ##还可
用于对象宏的替换部分。
##运算符把两个记号组合成一个记号。因此:
#define XNAME(n) x ## n
调用:XNAME(4)
得到:x4
见以下程序:
// glue.c -- use the ## operator
#include
#define XNAME(n) x ## n
#define PRINT_XN(n) printf("x" #n " = %d\n", x ## n);
int main(void)
{
int XNAME(1) = 14; // becomes int x1 = 14;
int XNAME(2) = 20; // becomes int x2 = 20;
int x3 = 30;
PRINT_XN(1); // becomes printf("x1 = %d\n", x1);
PRINT_XN(2); // becomes printf("x2 = %d\n", x2);
PRINT_XN(3); // becomes printf("x3 = %d\n", x3);
return 0;
}
注意, PRINT_XN()宏用#运算符组合字符串, ##运算符把记号组合为一
个新的标识符。
3.3 变参宏: … 和 _ VA_ARGS _
一些函数(如 printf()) 接受数量可变的参数。
通过把宏参数列表中最后的参数写成省略号(即, 3个点…) 来实现这
一功能。 这样, 预定义宏_ VA_ARGS _可用在替换部分中, 表明省略号代表什么。如:
#define PR(...) printf(_ _VA_ARGS_ _)
调用:
PR("Howdy");
PR("weight = %d, shipping = $%.2f\n", wt, sp);
对于第一次调用, _ VA_ARGS _ 扩展为参数:“Howdy”;
对第二次调用, _ VA_ARGS _ 扩展为参数:
“weight = %d, shipping = $%.2f\n”, wt, sp
因此,代码的结果为:
printf("Howdy");
printf("weight = %d, shipping = $%.2f\n", wt, sp);
见如下程序:
// variadic.c -- variadic macros
#include
#include
#define PR(X, ...) printf("Message " #X ": " _ _VA_ARGS_ _)
int main(void)
{
double x = 48;
double y;
y = sqrt(x);
PR(1, "x = %g\n", x);
PR(2, "x = %.2f, y = %.4f\n", x, y);
return 0;
}
在第一次宏调用中, x 值为1,因此 #x 变为 “1”,表达式变为:
print("Message " "1" ": " "x = %g\n", x);
然后将空双引号去掉变为;
print("Message 1: x = %g\n", x);
注意:省略号只能代表最后的宏参数:
#define WRONG(X, ..., Y) #X #_ _VA_ARGS_ _ #y // 错误
4. 宏和函数的选择
有些编程任务既可以用带参数的宏完成, 也可以用函数完成。 应该使用
宏还是函数?
宏和函数的选择实际上是时间和空间的权衡。
宏生成内联代码, 即在程序中生成语句。 如果调用20次宏, 即在程序中插入20行代码。 如果调用函数20次, 程序中只有一份函数语句的副本, 所以节省了空间。
然而另一方面,程序的控制必须跳转至函数内, 随后再返回主调程序, 这显然比内联代码花费更多的时间。
宏的一个优点是, 不用担心变量类型(这是因为宏处理的是字符串, 而
不是实际的值) 。 因此, 只要能用int或float类型都可以使用SQUARE(x)宏。
注意以下几点:
- 宏名中不允许有空格, 但是在替换字符串中可以有空格。
- 用圆括号把宏的参数和整个替换体括起来。 这样能确保被括起来的部分
能正确展开。 - 如果打算使用宏来加快程序的运行速度, 那么首先要确定使用宏和使用
函数是否会导致较大差异。 在程序中只使用一次的宏无法明显减少程序的运行时间。 在嵌套循环中使用宏更有助于提高效率。