python sklearn 机器学习库使用
此代码包括了机器学习常用的算法的Python使用方法,随机选取训练集和测试集,需要安装numpy、sklearn库。
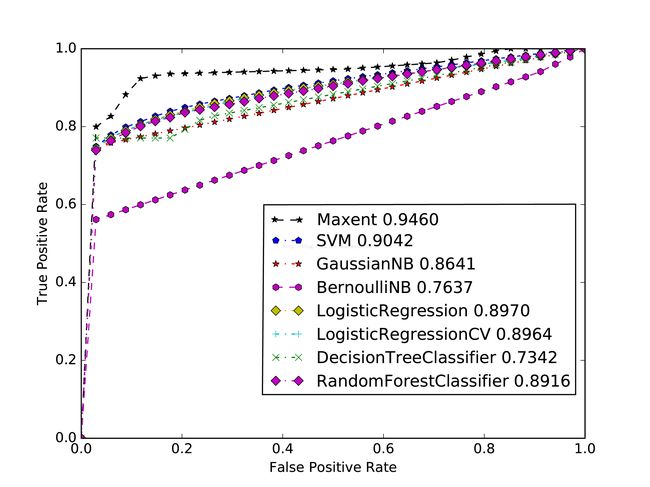
包括:'SVM ','GaussianNB ','BernoulliNB ','LogisticRegression ','LogisticRegressionCV ','DecisionTreeClassifier ','RandomForestClassifier '共7个模型。
#机器学习sklearn的简单用法:
#-*-coding:cp936 -*-
import numpy as np
np.__version__
import pandas as pd
from pandas import DataFrame
import matplotlib.pyplot as plt
from sklearn import neighbors,datasets
from sklearn.cross_validation import train_test_split
import sklearn
from sklearn import svm
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LogisticRegressionCV
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import BernoulliNB
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from matplotlib import pyplot as plt
from matplotlib import pylab
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
import pickle
import sys
import codecs
import traceback
def deal_data(filename):
print '开始打开文件,加载数据'
name2='pos_'+filename+'_value.txt'
name3='neg_'+filename+'_value.txt'
f=open(name2,'rt')
g=open(name3,'rt')
data1=np.loadtxt(f,delimiter=',')
try:
data2=np.loadtxt(g,delimiter=',')
except ValueError,e:
print "error",e,"on line",i#找出哪一行是空值或者无效的值
label1=np.ones(len(data1))
data1=np.c_[data1,label1]#np将两个矩阵合并,也就是在data1后面加上一列,在此之前将不同label分开放置了,且文件没有包含label,这里将label和数据合并
label2=np.zeros(len(data2))
data2=np.c_[data2,label2]
data=np.concatenate((data1,data2))
m,n=data.shape
print m,n
print '加载数据成功'
return data
def choose_model(modelnum,X_train, X_test, y_train, y_test):
print '开始选择模型'
if modelnum==1:
clf = svm.SVC(probability=True).fit(X_train, y_train)
if modelnum==2:#
clf = GaussianNB().fit(X_train, y_train)
if modelnum==3:#
clf = BernoulliNB().fit(X_train, y_train)
if modelnum==4:
clf = LogisticRegression().fit(X_train, y_train)
if modelnum==5:
clf = LogisticRegressionCV().fit(X_train, y_train)
if modelnum==6:#
clf = tree.DecisionTreeClassifier().fit(X_train, y_train)
if modelnum==7:#
clf = RandomForestClassifier(n_estimators=10).fit(X_train, y_train)
return clf
def train_data(filename,modelnum):
data=deal_data(filename)
data=np.nan_to_num(data)#Replace nan with zero and inf with finite numbers.
print '开始选择测试集,并训练'
X_train, X_test, y_train, y_test = train_test_split(data[:,0:10],data[:,-1],test_size=0.4,random_state=0)#随机选择训练集和测试集
try:
clf=choose_model(modelnum,X_train, X_test, y_train, y_test)
except:
print 'error!!!'
# print clf.score(X_test, y_test)
pre=clf.predict_proba(X_test)
real=y_test
return pre,real
def get_tpr_fpr(filename,modelnum):
pre,real=train_data(filename,modelnum)
print '生成tpr_fpr文件'
name1=filename+str(modelnum)+'_tpr_fpr.txt'
g=open(name1,'wt')
g=open(name1,'at')
th=0.0 #为阈值
for i in range(0,100,10):
th=i*1.0/100
tp=0
fp=0
tn=0
fn=0
for j in range(0,len(pre)):
# print pre[:,1][j],th,'tp:',tp,'fp',fp,'tn',tn,'fn',fn
if pre[:,1][j]>=th :
if real[j]==1:
tp=tp+1
else:
fp=fp+1
else:
if real[j]==0:
tn=tn+1
else:
fn=fn+1
tpr=tp*1.0/(tp+fn)
fpr=fp*1.0/(tn+fp)
# print i,tpr,'!',fpr,'!!!'
# print th,tp,fp,tp+fp,tn,fn,tn+fn,len(pre)
# print tp+fn,fp+tn
tpr=round(tpr,4)
fpr=round(fpr,4)
g.write(str(tpr)+'%'+str(fpr)+'\n')
g.close()
name=['name1','name2','name3']#设置训练的文件名字
for i in range(0,3):
for j in range(1,8):
get_tpr_fpr(str(name[i]),j) 输入数据:各个属性的值及其标签
输出数据:tpr_fpr文件,从而画ROC图
如果不需要画roc图,可以直接调用下面函数获得所要数据:
accuracy_score(y_test,y_pre)
roc_auc_score(y_test,y_pre)
average_precision_score(y_test,y_pre)
f1_score(y_test,y_pre)
recall_score(y_test,y_pre)精确率、正确率、召回率、f1等看这个博客不错点击打开链接
画图部分函数:
plt.legend(loc=4)#设置图例位置
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext, fontsize=18)
plt.xlabel('False Positive Rate',fontsize=20,labelpad = 5)
plt.ylabel('True Positive Rate',fontsize=20)
#plt.title('The ROC curve on '+str(picture_name[j])+' dataset ')
plt.savefig(picture_name[j]+'.png')
plt.savefig(picture_name[j]+'.eps')#保存为矢量图
plt.show()图片示例: