与其道听途说,不如少走点弯路,轻松跟我来全面剖析 darknet 官网!
仔细研读官网,你绝对不会失望!很多人以为 darknet 就是一个实现 yolo 算法的私人代码。事实上, darknet 官网全面介绍了darknet 在更多领域的优秀表现,包括图像检测、图像分类、图像生成、RNN自然语言处理算法、AlphaGo下棋、模型压缩精简。官网提供了大量训练好的模型资源,可以为我们节省不少训练时间。最后,官网还对个人GPU工作站配置等提供了很好的参考建议。
官网地址:https://pjreddie.com/darknet/

官网链接:Darknet: 用C语言编写的开源神经网络
Darknet是一个用C和CUDA编写的开源神经网络框架。它速度快,易于安装,支持CPU和GPU计算。您可以在GitHub上找到源代码,也可以在这里阅读更多关于Darknet可以做什么的信息:
一、安装 Darknet
Darknet易于安装,只有两个可选依赖项:
- OpenCV:提供更广泛的图像类型支持。
- CUDA:提供 GPU 算力支持。
两者都是可选的,所以让我们从安装基本系统开始。我只在Linux和Mac电脑上测试过。如果对你不起作用,可以给我发邮件。
1、安装基本系统
首先在这里克隆Darknet git存储库。这可以通过以下方式实现:
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
如果这有效,你会看到一大堆编译信息飞驰而过:
mkdir -p obj
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast....
.....
gcc -I/usr/local/cuda/include/ -Wall -Wfatal-errors -Ofast -lm....
如果你有任何错误,试着去修正它们?如果一切看起来都编译正确,请尝试运行它!
./darknet
你应该得到输出:
usage: ./darknet
太好了!现在来看看你能用 darknet 做些什么。
2、使用 CUDA 编译
CPU上的Darknet速度很快,但是GPU上的速度快了500倍!你必须有一个Nvidia的GPU,你必须安装CUDA。我不会详细介绍CUDA的安装,因为它很可怕。
安装CUDA后,将基本目录中Makefile的第一行更改为:
GPU=1
现在你可以做这个项目,CUDA将被启用。默认情况下,它将在系统的第0个图形卡上运行网络(如果正确安装了CUDA,则可以使用nvidia smi列出图形卡)。如果您想更改 Darknet 使用的卡,可以给它一个可选的命令行标志-i,比如
./darknet -i 1 imagenet test cfg/alexnet.cfg alexnet.weights
如果您使用CUDA编译,但出于任何原因希望进行CPU计算,则可以使用-nogpu来代替CPU:
./darknet -nogpu imagenet test cfg/alexnet.cfg alexnet.weights
好了,现在你可以享受新的、超快速的神经网络了!
3、用OpenCV编译
默认情况下,Darknet使用stb_image.h加载图像。如果你想更多的支持奇怪的格式(像CMYK jpeg,谢谢奥巴马),你可以使用OpenCV代替!OpenCV还允许您查看图像和检测,而无需将它们保存到磁盘。
首先安装OpenCV。如果从源代码处执行此操作,则会很长且很复杂,因此请尝试让包管理器为您执行此操作。
接下来,将 Makefile 的第2行更改为:
OPENCV=1
完成后,要试用它,首先要重新制作项目,然后使用imtest例程测试图像加载和显示:
./darknet imtest data/eagle.jpg
如果你看到有着一只老鹰的图形窗户,你就成功了!它们可能看起来像:

二、YOLO:实时目标检测
官网链接:YOLO:实时目标检测
“You Only Look Once(YOLO)” 是一个最先进的实时物体检测系统。在帕斯卡泰坦X上,它以每秒30帧的速度处理图像,在COCO test-dev上有57.9%的平均精度。
1、与其他探测器的比较
YOLOv3非常快速和准确。在0.5 IOU 处测得的mAP中,YOLOv3 与 Focal Loss 相当,但速度快了约 4 倍。此外,您可以轻松地权衡速度和准确性之间的简单改变模型的大小,无需再训练!

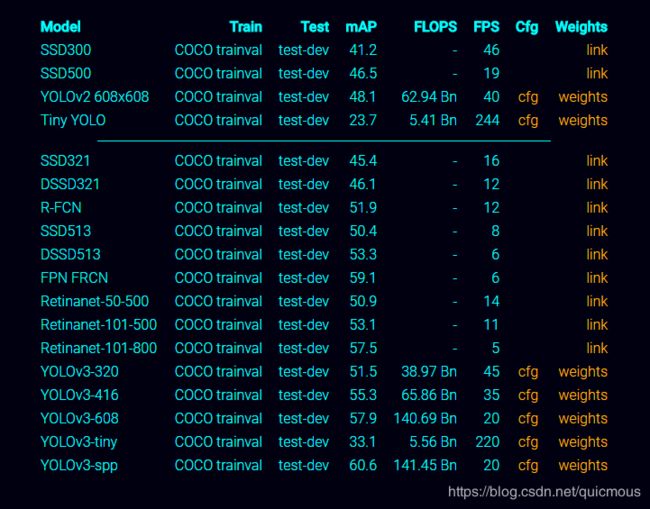
2、COCO数据集的性能
各种算法模型在 COCO 数据集上测试结果如下。注意,可以在原文里表格中直接下载 cfg、weights 等模型,这个非常有价值哦。
3、工作原理
先前的检测系统重新利用分类器或定位器来执行检测。他们将模型应用于多个位置和比例的图像。图像的高分区域被认为是检测。
我们使用完全不同的方法。我们将单一的神经网络应用于完整的图像。该网络将图像分为多个区域,并预测每个区域的包围盒和概率。这些边界框由预测的概率加权。

与基于分类器的系统相比,我们的模型有几个优点。它在测试时查看整个图像,因此它的预测由图像中的全局上下文通知。它也用单一的网络评估来预测,不像 R-CNN 这样的系统需要数千张单一的图像。这使得它非常快,比 R-CNN 快 1000 倍,比 R-CNN 快 100 倍。有关完整系统的更多详细信息,请参阅我们的论文。
版本3有什么新功能?
YOLOv3使用了一些技巧来改进训练和提高性能,包括:多尺度预测、更好的主干分类器等等。全部细节都在我们的论文上!
4、使用预先训练的模型进行检测
这篇文章将指导你通过使用一个预先训练好的模型用YOLO系统检测物体。如果你还没有安装Darknet,你应该先安装。或者不去阅读所有的东西:
git clone https://github.com/pjreddie/darknet
cd darknet
make
安装很容易,对吧!
在 cfg/ 子目录中已经有 YOLO 的配置文件。你必须在这里下载预先训练的权重文件(237MB)。或者运行这个:
wget https://pjreddie.com/media/files/yolov3.weights
然后运行检测器!
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
您将看到如下输出:
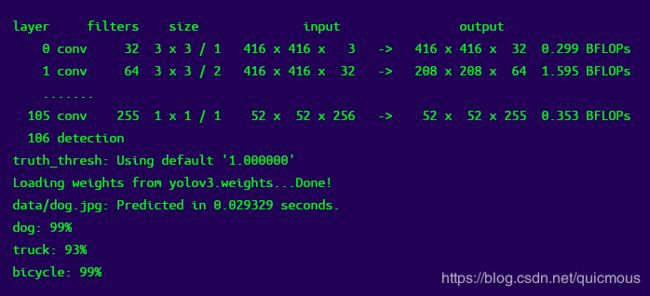
Darknet打印出它检测到的物体,它的可信度,以及找到它们所花的时间。我们没有用OpenCV编译Darknet,因此它不能直接显示检测结果。相反,它把它们保存在预测.png. 您可以打开它来查看检测到的对象。因为我们在CPU上使用Darknet,所以每张图像大约需要6-12秒。如果我们使用GPU版本,速度会快得多。
我还提供了一些示例图片,以防您需要灵感。尝试 data/eagle.jpg, data/dog.jpg, data/person.jpg, or data/horses.jpg!
detect命令是命令的更通用版本的简写。它相当于命令:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
多幅图像
不必在命令行上提供图像,您可以将其留空以尝试一行中的多个图像。相反,当配置和权重完成加载时,您将看到一个提示:

输入图像路径 data/horses.jpg,我们可以看到预测盒子。
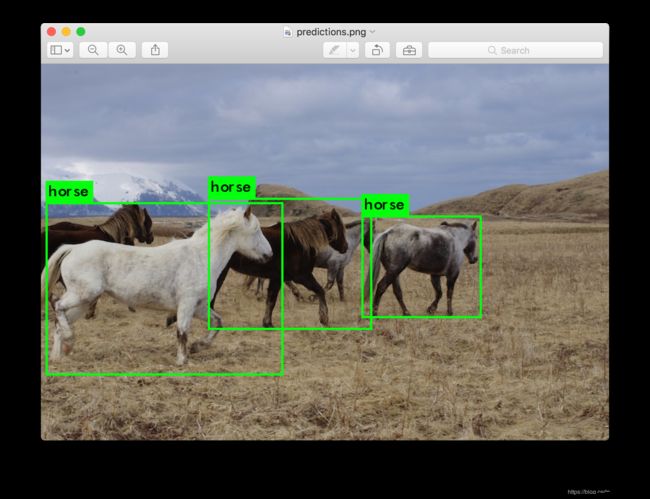
完成后,它将提示您输入更多路径以尝试不同的图像。完成后,使用Ctrl-C退出程序。
更改检测阈值
默认情况下,YOLO只显示置信度为.25或更高的对象。可以通过将-thresh标志传递给yolo命令来更改此值。例如,要显示所有检测,可以将阈值设置为0:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
产生:
![][all]
所以这显然不是非常有用,但是可以将其设置为不同的值来控制模型设置的阈值。
Tiny YOLOv3(微型 YOLOv3)
我们有一个非常小的模型,也适用于约束环境,yolov3 tiny。要使用此模型,请首先下载权重:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
YOLO将显示当前FPS和预测类,以及在其上绘制边界框的图像。
你需要一个网络摄像头连接到 OpenCV 可以连接到的计算机,否则它将无法工作。如果您连接了多个网络摄像头,并且希望选择要使用的摄像头,则可以通过 -c 标志进行选择(OpenCV默认使用网络摄像头0)。
如果OpenCV可以读取视频,也可以在视频文件上运行它:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 5、网络摄像头的实时检测
如果看不到结果,在测试数据上运行YOLO就不是很有趣了。与其在一堆图片上运行,不如在网络摄像头的输入上运行!
要运行这个演示,您需要使用 CUDA 和 OpenCV 编译 Darknet。然后运行命令:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
YOLO将显示当前FPS和预测类,以及在其上绘制边界框的图像。
你需要一个网络摄像头连接到OpenCV可以连接到的计算机,否则它将无法工作。如果您连接了多个网络摄像头,并且希望选择要使用的摄像头,则可以通过-c标志进行选择(OpenCV默认使用网络摄像头0)。
如果OpenCV可以读取视频,也可以在视频文件上运行它:
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights 这就是我们制作上述YouTube视频的方式。
6、用 VOC 数据集训练 YOLO
如果你想使用不同的训练模式、超参数或数据集,你可以从头开始训练YOLO。下面是如何让它在Pascal VOC数据集上工作。
获取Pascal VOC数据
要训练YOLO,您需要2007年至2012年的所有VOC数据。你可以在这里找到数据的链接。要获取所有数据,请创建一个目录来存储所有数据,然后从该目录运行:
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
现在将有一个 VOCdevkit/ 子目录,其中包含所有VOC培训数据。
为VOC生成标签
现在我们需要生成Darknet使用的标签文件。Darknet希望为每个图像创建一个.txt文件,并为图像中的每个地面真实对象创建一条线,如下所示:
其中x、y、宽度和高度与图像的宽度和高度相关。为了生成这些文件,我们将运行 voc_label.py 标签在 Darknet 的 script s/ 目录中编写脚本。我们再下载一次吧,因为我们很懒。
wget https://pjreddie.com/media/files/voc_label.py
python voc_label.py
几分钟后,此脚本将生成所有必需的文件。它主要在VOCdevkit/VOC2007/labels/和VOCdevkit/VOC2012/labels/中生成大量标签文件。在您的目录中,您应该看到:
ls
2007_test.txt VOCdevkit
2007_train.txt voc_label.py
2007_val.txt VOCtest_06-Nov-2007.tar
2012_train.txt VOCtrainval_06-Nov-2007.tar
2012_val.txt VOCtrainval_11-May-2012.tar
像2007这样的文本文件_train.txt文件列出当年的图像文件和图像集。Darknet需要一个文本文件,其中包含所有要训练的图像。在这个例子中,让我们训练除了2007测试集之外的所有东西,以便我们可以测试我们的模型。运行:
cat 2007_train.txt 2007_val.txt 2012_*.txt > train.txt
现在我们把2007年的trainval和2012年的trainval都列在一个大名单上。这就是我们要做的数据设置!
修改Pascal数据的Cfg
现在去你的 Darknet 目录,我们必须修改 cfg/voc.data 指向数据的配置文件:
1 classes= 20
2 train = /train.txt
3 valid = 2007_test.txt
4 names = data/voc.names
5 backup = backup
您应该将 替换为放置voc数据的目录。
下载预训练卷积权重
对于训练,我们使用在Imagenet上预先训练的卷积权重。我们使用darknet53模型的权重。你可以在这里下载卷积层的权重(76MB)。
wget https://pjreddie.com/media/files/darknet53.conv.74
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74
7、用 COCO 数据集训练 YOLO
如果你想使用不同的训练模式、超参数或数据集,你可以从头开始训练YOLO。下面是如何让它在COCO数据集上工作。
获取COCO数据
为了训练YOLO,你需要所有的COCO数据和标签。脚本/得到可可_数据集.sh会帮你的。找出要将COCO数据放在哪里并下载它,例如:
cp scripts/get_coco_dataset.sh data
cd data
bash get_coco_dataset.sh
现在您应该拥有为Darknet生成的所有数据和标签。
修改COCO的cfg
现在去你的 Darknet 目录,我们必须修改 cfg/coco.data 指向数据的配置文件:
1 classes= 80
2 train = /trainvalno5k.txt
3 valid = /5k.txt
4 names = data/coco.names
5 backup = backup
您应该用放置coco数据的目录替换
您还应该修改模型cfg以进行培训,而不是测试。cfg公司/约罗.cfg应该是这样的:
[net]
# Testing
# batch=1
# subdivisions=1
# Training
batch=64
subdivisions=8
....
训练模型
现在我们可以训练了!运行命令:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74
如果要使用多个GPU运行:
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3
如果要从检查点停止并重新开始培训:
./darknet detector train cfg/coco.data cfg/yolov3.cfg backup/yolov3.backup -gpus 0,1,2,3
8、基于 Open Images 数据集的 YOLOv3
wget https://pjreddie.com/media/files/yolov3-openimages.weights
./darknet detector test cfg/openimages.data cfg/yolov3-openimages.cfg yolov3-openimages.weights
yolo 网站怎么了?
如果您使用的是YOLO版本2,您仍然可以在此处找到该网站:https://pjreddie.com/darknet/yolov2/
引用
如果你在工作中使用YOLOv3,请引用我们的论文!
@article{yolov3,
title={YOLOv3: An Incremental Improvement},
author={Redmon, Joseph and Farhadi, Ali},
journal = {arXiv},
year={2018}
}
三、ImageNet 分类
官网:https://pjreddie.com/darknet/imagenet/
注意,官网提供了各种对比算法模型的配置和权重下载链接,有兴趣的可以前往下载。
您可以使用 Darknet 为 1000 类的 ImageNet挑战赛分类图像。如果你还没有安装Darknet,你应该先安装。
1、使用预先训练的模型分类
下面是安装Darknet、下载分类权重文件和在图像上运行分类器的命令:
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
wget https://pjreddie.com/media/files/darknet19.weights
./darknet classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights data/dog.jpg
本例使用Darknet19模型,您可以在下面阅读更多有关它的信息。运行此命令后,您将看到以下输出:
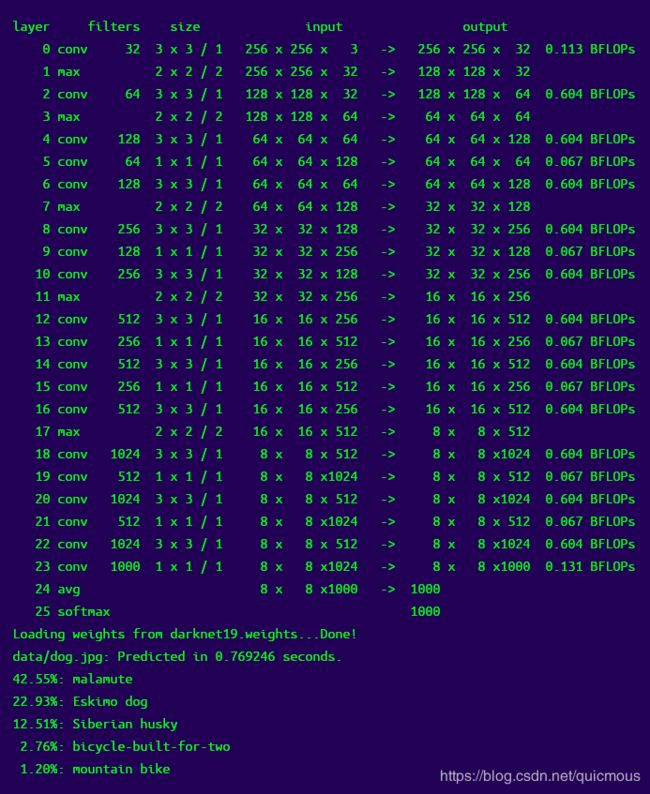
Darknet在加载配置文件和权重时显示信息,然后对图像进行分类并打印图像的前10个类。海带是一种混合品种的狗,但她有很多软弱无力,所以我们认为这是一个成功的!
您也可以尝试使用其他图像,如秃鹰图像:
./darknet classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights data/eagle.jpg
产生:
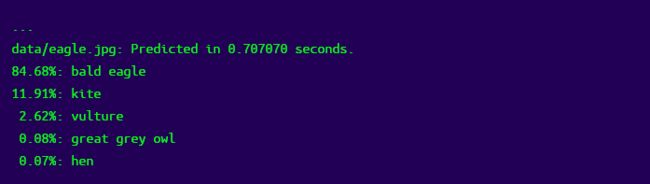
不错!
如果未指定图像文件,则在运行时将提示您输入图像。这样,您就可以在一行中对多个对象进行分类,而无需重新加载整个模型。使用命令:
./darknet classifier predict cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights
然后您将得到一个提示,如下所示:

每当你厌倦了分类图像,你可以使用 Ctrl-C 退出程序。
2、在 ImageNet 上验证
到处都可以看到这些验证集编号。也许你想再检查一下这些模型的实际工作情况。我们来吧!
首先需要下载验证图像和cls loc注释。你可以把它们弄到这里,但你得记帐!下载完所有内容后,您应该有一个包含ILSVRC2012_bbox_val_v3.tgz和ILSVRC2012_img的目录_瓦尔塔尔. 首先我们打开包装:
tar -xzf ILSVRC2012_bbox_val_v3.tgz
mkdir -p imgs && tar xf ILSVRC2012_img_val.tar -C imgs
现在我们有了图像和注释,但我们需要标记图像,以便Darknet能够评估其预测。我们使用这个bash脚本来实现这一点。它已经在脚本/子目录中了。我们只需再次获取并运行它:
wget https://pjreddie.com/media/files/imagenet_label.sh
bash imagenet_label.sh
这将生成两个内容:一个名为labeled/的目录,其中包含指向图像的重命名符号链接,另一个名为inet.val.列表其中包含标记图像的路径列表。我们需要将此文件移动到Darknet中的data/子目录:
mv inet.val.list /darknet/data
现在你终于可以验证你的模型了!先把黑暗重新制造出来。然后运行验证例程,如下所示:
./darknet classifier valid cfg/imagenet1k.data cfg/darknet19.cfg darknet19.weights
注意:如果您不使用 OpenCV 编译 Darknet,那么您将无法加载所有 ImageNet 图像,因为其中一些图像是 stb_image.h 不支持的奇怪格式。
如果不使用 CUDA 编译,仍然可以在 ImageNet 上进行验证,但这需要相当长的时间。不推荐这样做。
3、预先训练的模型
这里有各种用于ImageNet分类的预训练模型。准确度在ImageNet上测量为单作物验证准确度。GPU计时是在Titan X上测量的,CPU计时是在单核Intel i7-4790K(4 GHz)上运行的。在OPENMP中使用多线程应该与cpu的比例成线性关系。
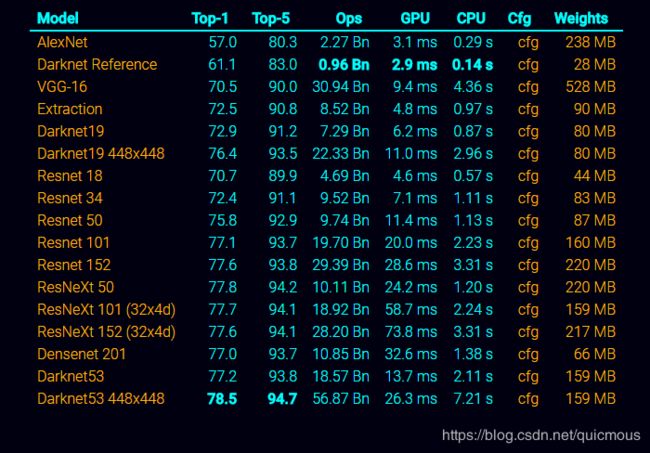
AlexNet
开始革命的模式!最初的模型是疯狂的分裂GPU的事情,所以这是一些后续工作的模型。
- Top-1 Accuracy: 57.0%
- Top-5 Accuracy: 80.3%
- Forward Timing: 3.1 ms/img
- CPU Forward Timing: 0.29 s/img
- cfg file
- weight file (238 MB)
Darknet Reference Model
这个模型设计得很小但是很强大。它获得了与AlexNet相同的前1名和前5名的性能,但参数只有1/10。它主要使用卷积层,而没有在末端的大型完全连接层。它的速度大约是AlexNet在CPU上的两倍,这使得它更适合一些视觉应用。
- Top-1 Accuracy: 61.1%
- Top-5 Accuracy: 83.0%
- Forward Timing: 2.9 ms/img
- CPU Forward Timing: 0.14 s/img
- cfg file
- weight file (28 MB)
VGG-16
牛津大学的视觉几何小组为ILSVRC-2014比赛开发了VGG-16模型。它具有很高的分类精度和广泛的应用前景。我根据Caffe预先训练的模型改编了这个版本。它被训练为另外6个阶段,以适应特定于暗度的图像预处理(而不是平均减影暗度调整图像介于-1和1之间)。
- Top-1 Accuracy: 70.5%
- Top-5 Accuracy: 90.0%
- Forward Timing: 9.4 ms/img
- CPU Forward Timing: 4.36 s/img
- cfg file
- weight file (528 MB)
Extraction
我开发了这个模型作为GoogleNet模型的一个分支。它不使用“初始”模块,只使用1x1和3x3卷积层。
- Top-1 Accuracy: 72.5%
- Top-5 Accuracy: 90.8%
- Forward Timing: 4.8 ms/img
- CPU Forward Timing: 0.97 s/img
- cfg file
- weight file (90 MB)
Darknet19
我修改了提取网络,使之更快更准确。这个网络是一种融合了黑暗参考网络和摘录以及众多出版物(如网络中的网络、初始和批量规范化)的思想。
- Top-1 Accuracy: 72.9%
- Top-5 Accuracy: 91.2%
- Forward Timing: 6.2 ms/img
- CPU Forward Timing: 0.87 s/img
- cfg file
- weight file (80 MB)
Darknet19 448x448
我用一个更大的输入图像大小448x448,为10多个时代训练了Darknet19。该模型性能明显更好,但速度较慢,因为整个图像更大。
- Top-1 Accuracy: 76.4%
- Top-5 Accuracy: 93.5%
- Forward Timing: 11.0 ms/img
- CPU Forward Timing: 2.96 s/img
- cfg file
- weight file (80 MB)
Resnet 50
出于某种原因,人们喜欢这些网络,即使他们是如此缓慢。
- Top-1 Accuracy: 75.8%
- Top-5 Accuracy: 92.9%
- Forward Timing: 11.4 ms/img
- CPU Forward Timing: 1.13 s/img
- cfg file
- weight file (87 MB)
Resnet 152
出于某种原因,人们喜欢这些网络,即使他们是如此缓慢。
- Top-1 Accuracy: 77.6%
- Top-5 Accuracy: 93.8%
- Forward Timing: 28.6 ms/img
- CPU Forward Timing: 3.31 s/img
- cfg file
- weight file (220 MB)
Densenet 201
我爱DenseNets!他们是如此深沉,如此疯狂,工作如此出色。像Resnet一样,仍然很慢,因为它们有很多层,但至少它们工作得很好!
- Top-1 Accuracy: 77.0%
- Top-5 Accuracy: 93.7%
- Forward Timing: 32.6 ms/img
- CPU Forward Timing: 1.38 s/img
- cfg file
- weight file (67 MB)
四、噩梦
从前,在一所大学的大楼里,西蒙尼亚、维达第和齐瑟曼有一个很好的主意,几乎和你现在坐的大楼完全不同。他们想,嘿,我们一直在向前运行这些神经网络,它们工作得很好,为什么不也向后运行呢?这样我们就能知道电脑在想什么。。。
由此产生的图像是如此恐怖,如此怪异,以至于他们的尖叫声可以听到一路坦普顿。

许多研究人员已经扩大了他们的工作范围,包括谷歌一篇广为人知的博客文章。
这是我抄袭那些抄袭那些有好主意的人。
1、与黑暗做恶梦
如果没有安装Darknet,请先安装!我们将使用VGG-16预训练模型来做噩梦。但是,我们不需要整个模型,只需要卷积层,所以我们可以使用vgg-转换cfg文件(应该已经在cfg/子目录中)。你需要在这里下载预训练重量(57MB)。
现在我们可以生成您在第一段中看到的尖叫图像:
./darknet nightmare cfg/vgg-conv.cfg vgg-conv.weights data/scream.jpg 10
命令分解如下:首先是可执行的和子例程,./darknet nermary,然后是配置文件和权重文件cfg/vgg-转换cfgvgg公司-换算重量. 最后我们得到了我们想要修改的图像和我们想要目标的配置文件的层,数据/尖叫.jpg10个。
这可能需要一段时间,特别是如果您只使用CPU。在我的机器上大约需要15分钟。我强烈建议让CUDA更快地产生噩梦。启用CUDA后,在泰坦X上大约需要7秒。
你可以尝试较低的层次,以获得更艺术的感觉:
./darknet nightmare cfg/vgg-conv.cfg vgg-conv.weights data/dog.jpg 7

或者用更高的层次来获得更复杂的紧急行为:
./darknet nightmare cfg/vgg-conv.cfg vgg-conv.weights data/eagle.jpg 13

2、特殊选项
你可能会注意到你的尖叫家伙看起来和我的不太一样。那是因为我有一些特别的选择!我实际使用的命令是:
./darknet nightmare cfg/vgg-conv.cfg vgg-conv.weights \
data/scream.jpg 10 -range 3 -iters 20 -rate .01 -rounds 4
Darknet在连续的回合中生成图像,上一轮的输出将进入下一轮。每一轮的图像也被写入磁盘。每一轮由若干次迭代组成。在每次迭代中,Darknet都会对图像进行修改,以在一定比例上增强选定的层。音阶是从一组八度音阶中随机选取的。该层是从一系列可能的层中随机选择的。修改此过程的命令包括:
- 轮数n:更改轮数(默认为1)。多轮意味着生成的图像越多,通常对原始图像的更改也越多。
- iters n:更改每轮的迭代次数(默认为10)。更多的迭代意味着每轮图像的更多更改。
- 范围n:更改可能图层的范围(默认值1)。如果设置为1,则每次迭代时仅选择给定层。否则,一个层将在比范围内随机选择(例如10-范围3将在层9-11之间选择)。
- 八度音阶n:更改可能的音阶数(默认为4)。在一个倍频程下,只检查全尺寸图像。每增加一个八度音阶,图像就会增加一个更小的版本(前一个八度音阶的3/4大小)。
- rate x:更改图像的学习速率(默认值为.05)。越高意味着每次迭代对图像的更改越多,但也有一些不稳定性和不精确性。
- thresh x:更改要放大的特征的阈值(默认值为1.0)。在目标层中,仅放大偏离平均值超过x个标准差的特征。较高的阈值意味着放大的特征较少。
- 缩放x:更改每一轮后应用于图像的缩放(默认为1.0)。您可以选择添加放大(x<1)或缩小(x>1)以在每一轮后应用于图像。
- 旋转x:更改每一轮后应用的旋转(默认为0.0)。每轮后可选旋转。
这里有很多东西可以玩!下面是一个多轮和稳定放大的示例:
3、较小的模型
VGG-16是一个非常大的模型,如果内存不足,请尝试使用这个模型!
cfg文件在cfg/子目录中(或者这里),您可以在这里下载权重(72mb)。
./darknet nightmare cfg/jnet-conv.cfg jnet-conv.weights \
data/yo.jpg 11 -rounds 4 -range 3
4、DeepDream 和 GoogleNet 的比较
这些例子使用VGG-16网络。虽然古格伦似乎专注于狗和蛞蝓,但VGG喜欢生产獾,一种啮齿动物和猴子之间的奇怪杂交:

VGG也没有GoogleNet所拥有的本地响应规范化层。因此,它的梦魇经常被彩色的星光暴过度饱和。

欣赏吧!
五、Darknet 实现 RNN
递归神经网络是表示随时间变化的数据的强大模型。为了更好地介绍RNNs,我强烈推荐Andrej Karpathy去年的博客文章,这是一个伟大的资源,同时实施他们!
所有这些模型都使用相同的网络架构,一个包含3个递归模块的普通RNN。
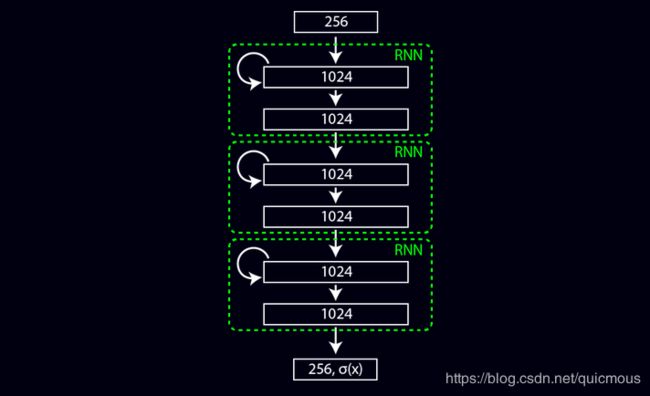
每个模块由3个完全连接的层组成。输入层将信息从输入传播到当前状态。递归层通过时间将信息从上一个状态传播到当前状态。因为我们希望输入层和递归层都影响当前状态,所以我们将它们的输出相加得到当前状态。最后,输出层将当前状态映射到RNN模块的输出。
网络的输入是一个1-hot编码的ASCII字符。我们训练网络预测字符流中的下一个字符。输出被限制为使用softmax层的概率分布。
由于每个递归层都包含有关当前字符和过去字符的信息,因此它可以使用此上下文来预测单词或短语中的未来字符。随着时间的推移,训练像这样展开:
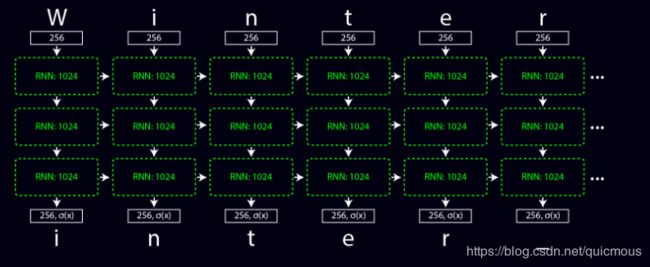
尽管一次只能预测一个字符,但这些网络可以非常强大。在测试时,我们可以评估给定句子的可能性,也可以让网络自己生成文本!
要生成文本,首先我们通过输入某些字符(如换行符“\n”)或一组字符(如句子)来建立网络。然后,我们将网络输出的最后一个字符作为输入反馈到网络中。由于网络的输出是下一个字符的概率分布,我们可以从给定的分布中提取最可能的字符或样本,但采样往往会产生更有趣的结果。
1、用黑色生成文本
首先你应该安装Darknet。因为您不需要CUDA或OpenCV,所以只需克隆GitHub存储库:
git clone https://github.com/pjreddie/darknet
cd darknet
make
选择要使用的权重文件后,可以使用以下命令生成文本:
./darknet rnn generate cfg/rnn.cfg
也可以将各种标志传递给此命令:
- len:更改生成文本的长度,默认为1000
- seed:用给定的字符串为RNN设定种子,默认为“\n”
- srand:为可重复运行的随机数生成器设置种子
- temp:设置采样温度,默认为0.7
闲聊够了,让我们冒充一些人!!
2、George R.R. Martin

乔恩
他靠得很近,头上还沾着洋葱,光着脚站在肩膀上。”“我不是一个紫色的女孩,”他站在他旁边说一看到你就把你父亲卖给你一个小小的选择。”
泰温勋爵说:“我要起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起誓,起我爱你的话,也爱她。”
“泰温大人会穿上它们,看看我的命令。”他拿着龙布,让哥哥把乌鸦带到走廊的另一边,哀号帮助她成为死去的人中唯一一个在他们安息时所爱的躯干的处女。红衣牧师很高兴地微笑着,向他们展示了从一开始的土地,红色和强大,她曾在水上做国王的马厩,孩子将在他父亲的儿子前夜迷路。连他的弟兄们也为他和王让路,叫他们乘王的快。“第一次是我来指挥,”内德说光明之王的子孙们,在客栈前,我们必须留好胡子。”
一天之后她告诉自己。那女孩是个妓院,当你可能来找我的时候,首先不要做你这么大胆的儿子。但他最追求的是不会背叛我的傻瓜。我不单是一个,他要用剑杀她,我的儿子也要软弱扬帆。”
“国王死了,”希兹达尔说我是一个让你失望的人。”
“我知道你答应过什么,陛下。我们见过骑士们放过士兵的松树。所以他就死了,”艾利泽爵士说。
“你把她一点金子给他,乌鸦就会给我。”
我就看见我打发你们被掳的人去,你们要把头从境内挪开
一些大破坏者!例如,乔恩不是一个“紫色女孩”,所以我想这很好?
要生成此文本,必须下载此权重文件:总重量(36 MB)。然后运行以下命令:
./darknet rnn generate cfg/rnn.cfg grrm.weights -srand 0 -seed JON
您可以更改srand或seed以生成不同的文本,所以请使用wild!我真的希望我不会因此被起诉。。。
OS X上的随机数生成器与Linux上的不同,因此如果运行相同的命令,则会得到不同的输出:
乔恩
每过几天,树林都跟着他的国王走。”我明白。”
“我不是你的妹妹罗伯特勋爵?”
“这扇门总有一个地窖,用来做他的女儿和巴拉森的大首领,每咬一口就有上千块半块,好像他不是一个伟大的骑士似的,不该看那红云两千人似的。”
“凯万爵士应该在下边的帮助下,用小人做一把剑,所以阿林勋爵不喜欢和我做这种事。他从来没有抱过一个人,好像城堡正在用碎金子做一些乌鸦,伸到了一只膝盖。”布兰说:“自由的城市和妇女的手被温柔地放在墙上,结束了他的指控。”我表弟兰尼斯特就是那个男孩。有几个小时的礼拜。“一个女人,”约拉爵士说。
“詹姆爵士肯定是把木剑。她是我的锁链中唯一一个让你这么做的人,夫人。”
“大人,您满意吗?”
“你是我的旅程,”他说我们应该杀了七国。内斯特勋爵不应该读她的书,如果你告诉她你认为像你这样的人也死了,还有男人,已经到码头很远了。她不知道如何去拜访国王。他姐姐看到阿莎被杀了。”你要说,你必不惹你到外边的城墙那里去,你就更有理由把你境内一切有智慧的人的金子带到海里去。”
“这是你妈妈,”他告诉他们我不知道没有你哥哥我是什么样的人,但那是光明之主想要站在那里的。”
“如果我有一个儿子,大人?”
阿利瑟爵士起初并不安全,但大厅里更容易看到下一次。我的父亲大人已经站起来要戴上他们的王冠了,这时塞普顿人把龙的孩子们和他的剑,以及野人和他的话都放在台阶上歌唱。”如果你不让她真的去偷东西或是剑呢?”
“随你所愿,”乔恩说。
3、William Shakespeare


要生成此文本,请运行:
./darknet rnn generate cfg/rnn.cfg shakespeare.weights -srand 0
此示例使用换行符的默认种子(“\n”)。更改文本种子或随机数种子将更改生成的文本。
这个模型是在一个单独的文件中对莎士比亚的全部作品进行培训的:莎士比亚.txt,最初来自古腾堡计划。
4、训练自己的模型
你也可以在新的文本数据上训练自己的模型!训练配置文件是 cfg/rnn.train.cfg. 培训所需的只是一个文本文件,其中包含所有ASCII格式的数据。然后运行以下命令:
./darknet rnn train cfg/rnn.train.cfg -file data.txt
模型会将定期备份保存到函数train_char_rnn中src/rnn.c中指定的目录,您可能希望将此目录更改为计算机的一个好位置。要从备份重新开始训练,您可以运行:
./darknet rnn train cfg/rnn.train.cfg backup/rnn.train.backup -file data.txt
如果你想在大量数据上训练大型模型,你可能需要在一个快速的GPU上运行它。你可以在CPU上训练它,但可能需要一段时间,你已经被警告了!
六、DarkGo: Go in Darknet(用 Darknet 写一个 AlphaGo!)
AlphaGo让我对玩游戏的神经网络感兴趣。
我还没有真正读过他们的论文,但我已经实现了我所想象的类似于他们的策略网络的东西。它是一个神经网络,可以预测围棋游戏中最有可能的下一步动作。你可以和专业游戏一起玩,看看接下来可能会发生什么动作,让它自己玩,或者试着和它对抗!
目前达克戈的水平是1丹。这对于一个没有前瞻性的网络来说是非常好的,但是它只评估当前的板状态。
来在线围棋服务器上玩我吧!https://online-go.com/user/view/434218
1、玩一个训练好的模型
首先安装Darknet,可以通过以下方法完成:
git clone https://github.com/pjreddie/darknet
cd darknet
make
同时下载权重文件:
wget pjreddie.com/media/files/go.weights
然后在测试模式下运行 Go 引擎:
./darknet go test cfg/go.test.cfg go.weights
这将产生一个交互式围棋板。你可以:
按回车键,只需从计算机中播放第一个建议的移动
- 输入一个类似于3的数字来播放该数字建议
- 输入一个像15这样的位置来执行这个动作
- 输入c A 15以在A 15清除任何碎片
- 输入b 15在a15处放置黑色块
- 输入w A 15在15处放置一个白色块
- 输入p通过转弯
好好玩吧!
如果希望网络更强大,请将flag-multi添加到testing命令中。这将在多次旋转和翻转时评估板,以获得更好的概率估计。它可以在CPU上很慢,但如果你有CUDA的话,它会很快。
2、数据
我使用休·珀金斯的 Github 的 Go 数据集。我给 Darknet 提供的数据是一个单通道图像,它对当前游戏状态进行编码。1 代表你的棋子,-1 代表你对手的棋子,0 代表空白。该网络预测了当前玩家下一步可能的游戏地点。
我在后处理后使用的完整数据集可以在此处找到(3.0 GB),仅用于培训:
开始训练吧!
七、Tiny Darknet
我听过很多人谈论 SqueezeNet。
SqueezeNet很酷,但它只是优化参数计数。当大多数高质量的图像是10MB或更大时,为什么我们要关心我们的型号是5MB还是50MB?如果你想要一个小模型,实际上很快,为什么不看看Darknet reference network?它只有28MB,但更重要的是,它只有8亿个浮点运算。最初的Alexnet是23亿。Darknet是速度的2.9倍,而且它很小,准确度提高了4%。
那么SqueezeNet呢?当然,重量只有4.8mb,但向前传球仍然是22亿次。Alexnet是一个伟大的分类第一关,但我们不应该被困在时代时,网络这么坏也这么慢!
但不管怎样,人们都很喜欢SqueezeNet,所以如果你真的坚持使用小型网络,请使用:
1、Tiny Darknet
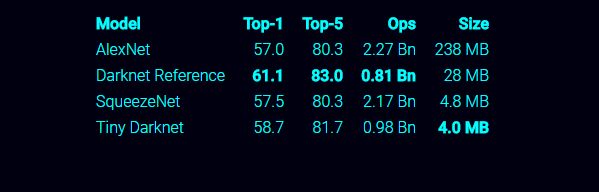
真正的赢家显然是Darknet参考模型,但如果你坚持想要一个小模型,请使用Tiny Darknet。或者自己训练,应该很容易!
下面是如何在Darknet中使用它(以及如何安装Darknet):
git clone https://github.com/pjreddie/darknet
cd darknet
make
wget https://pjreddie.com/media/files/tiny.weights
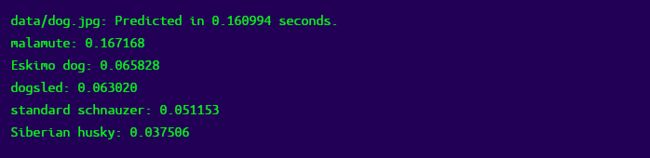
./darknet classify cfg/tiny.cfg tiny.weights data/dog.jpg
希望你能看到这样的东西:
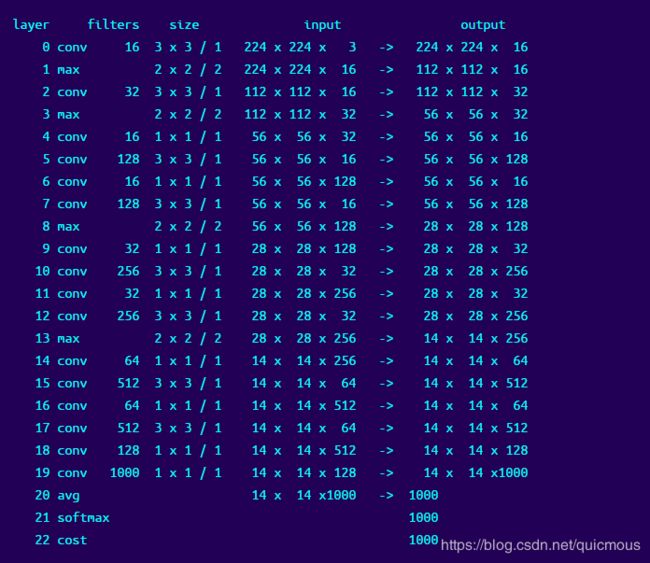
下面是配置文件:tiny.cfg
模型只是一些3x3和1x1卷积层:
八、CIFAR-10上训练分类器
这篇文章将教你如何在黑暗中从零开始训练分类器。我们将使用CIFAR-10数据集,一个10类的小图像数据集。我们开始吧!
1、安装Darknet
如果尚未安装,请执行以下操作:
git clone https://github.com/pjreddie/darknet
cd darknet
make
现在让我们看看我们有什么:
ls cifar
2、获取数据
我们将使用CIFAR数据的镜像,因为我们希望图片采用图像格式。原始的数据集是二进制格式的,但是我希望本教程能够推广到您想要使用的任何数据集,因此我们将用图像来代替。
让我们把数据放在数据/文件夹中。要执行此操作:
cd data
wget https://pjreddie.com/media/files/cifar.tgz
tar xzf cifar.tgz
现在让我们看看我们有什么:
ls cifar
列出两个包含我们的数据的目录,train和test,以及一个带有标签的文件,labels.txt文件. 你可以看看labels.txt文件如果您想了解我们将学习的课程类型:
cat cifar/labels.txt
我们还需要生成路径文件。这些文件将保存培训和验证(或在本例中是测试)数据的所有路径。为此,我们将cd到cifar目录中,找到所有图像,并将其写入文件,然后返回到基本darknet目录。
cd cifar
find `pwd`/train -name \*.png > train.list
find `pwd`/test -name \*.png > test.list
cd ../..
3、生成数据集配置文件
我们必须给Darknet一些关于CIFAR-10的元数据。使用您喜欢的编辑器,在cfg/目录中打开一个名为cfg的新文件/cifar.数据. 里面应该有这样的东西:
classes=10
train = data/cifar/train.list
valid = data/cifar/test.list
labels = data/cifar/labels.txt
backup = backup/
top=2
- classes=10: the dataset has 10 different classes
- train = …: where to find the list of training files
- valid = …: where to find the list of validation files
- labels = …: where to find the list of possible classes
- backup = …: where to save backup weight files during training
- top = 2: calculate top-n accuracy at test time (in addition to top-1)
4、制作网络配置文件
我们必须给Darknet一些关于CIFAR-10的元数据。使用您喜欢的编辑器,在cfg/目录中打开一个名为cfg的新文件/cifar.数据. 里面应该有这样的东西:
[net]
batch=128
subdivisions=1
height=28
width=28
channels=3
max_crop=32
min_crop=32
hue=.1
saturation=.75
exposure=.75
learning_rate=0.1
policy=poly
power=4
max_batches = 5000
momentum=0.9
decay=0.0005
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=16
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[convolutional]
filters=10
size=1
stride=1
pad=1
activation=leaky
[avgpool]
[softmax]
这是一个非常小的网络,所以它不会很好地工作,但对于这个例子来说,它是很好的。网络只有4个卷积层和2个最大池层。
最后一个卷积层有10个滤波器,因为我们有10个类。它输出一个7 x 7 x 10的图像。我们只需要总共10个预测,所以我们使用一个平均池层来获取每个通道图像的平均值。这将给我们10个预测。我们使用 softmax 将预测转换为概率分布。这一层还将我们的误差计算为交叉熵损失。
5、训练模型
现在我们只需要运行训练代码!
./darknet classifier train cfg/cifar.data cfg/cifar_small.cfg
看着它走!
您只是告诉Darknet您想要使用以下数据和网络cfg文件来训练分类器。CPU上的培训可能需要一个小时或更长时间,甚至对于这个小型网络也是如此。如果你有一个GPU,你应该按照这些说明启用GPU培训。
重新开始训练
如果停止培训,您可以始终使用它沿途保存的模型检查点之一重新启动它:
./darknet classifier train cfg/cifar.data cfg/cifar_small.cfg backup/cifar_small.backup
6、验证模型
现在我们要看看我们的模型有多好。我们可以使用valid命令计算top-1和top-2验证精度。我们可以对备份、最终权重文件或任何保存的epoch权重文件运行验证:
./darknet classifier valid cfg/cifar.data cfg/cifar_small.cfg backup/cifar_small.backup
你会看到一堆滚动的数字,告诉你你的准确性。
九、硬件指南:GPU上的神经网络(更新于2016-1-30)
卷积神经网络目前在计算机视觉领域非常流行。然而,由于它们是相对较新的,而且这个领域在它们周围发展的如此之快,许多人对如何最好地训练它们感到困惑。我有一些研究生和行业研究员问我,他们应该为个人机器或服务器购买什么样的硬件。
英伟达希望您购买他们的新数字 Devbox,但价格为15000美元,有8-10周的延迟时间,我不知道为什么会有人想要它。大约6000美元税后,你可以建立自己的 4 GPU 盒子,在短短几天内从 Newegg 船运。
1、全套装备
你可以在这里找到我的全部家当。这只是为了盒子,你还需要一些GPU。我从亚马逊买了4块 EVGA Titan X。
基本的电脑是1400美元,再加上4千美元的GPU,你就准备好了!不到15000美元。
2、GPU
可能最重要和最昂贵的部分,你的建设将是GPU,并有充分的理由。gpu在训练和测试神经网络方面比CPU快100倍以上。我们的大部分计算都是将大矩阵相乘在一起,所以我们需要一张具有高单精度性能的卡。

泰坦X(Titan X)
这可能是你想要的。这款游戏机被设计成英伟达(NVIDIA)最高端的游戏GPU,其处理能力高达7 TFLOPS,售价仅为1000美元,您可以将其中的4台设备安装在一台机器上。有了12GB的VRAM,他们可以运行所有的大模型,并有足够的空间。
网上的人似乎认为EVGA和华硕在质量上是平等的,但EVGA有更好的客户服务,所以我会得到那个。我在亚马逊买的,因为它们比其他选择便宜一点,而且发货很快。
其他 GPU 板卡:Tesla K40、K80、其他 GeForce 900
K40和K80更倾向于高双精度的性能,我们并不真正关心。他们的单精度性能与泰坦X不相上下,但有着显著的提高。
其他高端GTX卡,如980和980 Ti,与Titan X相比,可获得良好的单精度性能,但如果您需要大量的处理能力,则使用4 Titan X生产一台机器要比使用8 980生产两台机器简单得多。下面是比较:
- Titan X: 1 , 000 , 6.9 T F L O P S , 6.9 G F L O P S / 1,000, 6.9 TFLOPS, 6.9 GFLOPS/ 1,000,6.9TFLOPS,6.9GFLOPS/
- GTX 980 Ti: 670 , 5.6 T F L O P S , 8.4 G F L O P S / 670, 5.6 TFLOPS, 8.4 GFLOPS/ 670,5.6TFLOPS,8.4GFLOPS/
- GTX 980: 500 , 4.1 T F L O P S , 8.2 G F L O P S / 500, 4.1 TFLOPS, 8.2 GFLOPS/ 500,4.1TFLOPS,8.2GFLOPS/
- Tesla K40: 3 , 000 , 4.3 T F L O P S , 1.4 G F L O P S / 3,000, 4.3 TFLOPS, 1.4 GFLOPS/ 3,000,4.3TFLOPS,1.4GFLOPS/
- Tesla K80: 5 , 000 , 8.7 T F L O P S , 1.7 G F L O P S / 5,000, 8.7 TFLOPS, 1.7 GFLOPS/ 5,000,8.7TFLOPS,1.7GFLOPS/
从效率的角度来看,980Ti 是领先的。不过,您确实做出了一些牺牲:只有6gb的VRAM,总体性能也比较慢。如果你手头拮据,我想980Ti是个不错的选择。主要的建议是,无论如何,不要得到特斯拉斯,这东西实在太贵了。如果你想在一个盒子比泰坦X的有更好的整体处理能力这可能是最好的选择。(From an efficiency standpoint the 980 Ti comes out ahead. However, you do make some sacrifices: only 6 GB of VRAM and slower overall performance. If you are strapped for cash I’d say the 980 Ti is a good option. The main takeaway is do not, for any reason, get Teslas. They are crazy expensive for what you get out. If you want overall processing power in one box than Titan X’s are the best option.)
主板: GIGABYTE GA-X99-UD3P

主板最重要的方面是,它可以容纳所有的卡,你想进入它。不管你选什么,确保它能支持4块GPU卡。一般来说,寻找高端游戏主板。有足够的空间放4张双宽的GPU卡。
CPU: Intel Core i7-5820K

你不需要一个很好的CPU,但你还是买一个吧!有12个有效的核心,这是一个很好的选择。
电源: Rosewill Hercules

我们的每一张卡都会消耗250瓦的电能,而我们的其他电脑可能也需要一些电能。这意味着我们需要超过1千瓦的电力!为了安全起见,我会用一个真正的怪物电源,比如1600W的罗斯威尔大力神,它有一吨的电力,唯一的问题是它很大!我得从箱子里拿出一个风扇支架才能装进去。
内存: G.SKILL Ripjaws 4 Series 32GB

大量廉价内存。32GB应该足够了,尽管这意味着我们的RAM比VRAM少!
SSD硬盘: Mushkin Enhanced Reactor 2.5" 1TB

机箱: Rosewill Thor V2

这可能是最不重要的,但看起来确实很酷!你真的只需要一个足够大的箱子来舒适地安装你所有的部件。4 GPU占用了很多空间!你也想要酷的东西。罗斯威尔雷神包4风扇预先安装和足够的空间,你不必担心良好的电缆管理,这是很好的,因为我很恐惧电缆。它的评价也很高,而且很便宜。