pytorch学习(五)利用pytorch训练CycleGAN-------的句句讲解
1.cycleGAN论文
https://arxiv.org/abs/1406.2661
2.cycleGAN简单介绍
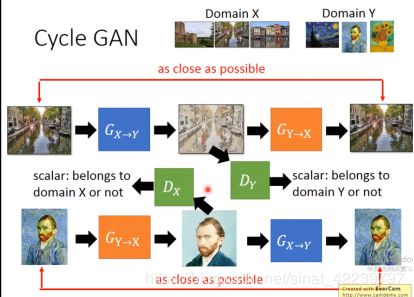
首先:

这个过程呢和GAN是一样的。
但是,最终学习后的结果,很有可能G (X-Y)输出的图像的ID并不是源域X的ID,而是目标域Y中的另一个ID的相似度极高的图片,那么如何解决这一问题呢,这篇文章就引入了一个循环一致性损失(a cycle consistency loss)来使得F(G(X))≈X(反之亦然),含义就是把源域的生成的图片再映射回源域,其分布依然是趋于相同的。
这个引入的过程如下:
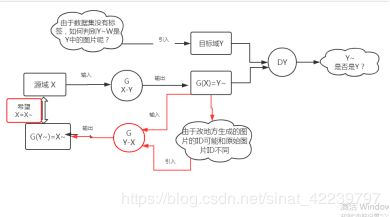
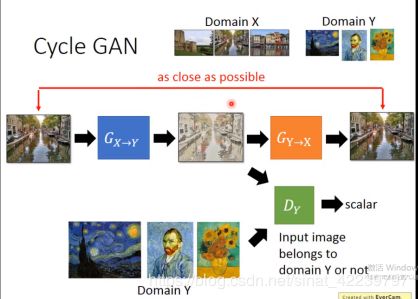
但是由于G(Y-X)并没有真正见到过目标域Y中的图像,它的输入都是G(X-Y)生成的,但是有可能生成的不一定正确,于是我们将Y作为输入,输入到G(Y-X)中,让它生成一个真实的源域X中的图片X ~ ~ 。
然后再将G(X-Y)拿过来,希望前面生成的X~~转成目标域中的图片。
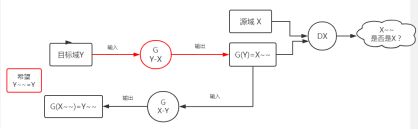
这里面其实是一个循环的过程,共两个生成器,其实图中两个红色的G(Y-X)是一个,两个黑色的G(X-Y)也是一个,两个判别器D(X),D(Y).。
3.cycleGAN代码讲解
https://github.com/aitorzip/PyTorch-CycleGAN
train.py
#!/usr/bin/python3
import argparse
import itertools
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
from PIL import Image
import torch
from models import Generator
from models import Discriminator
from utils import ReplayBuffer
from utils import LambdaLR
from utils import Logger
from utils import weights_init_normal
from datasets import ImageDataset
parser = argparse.ArgumentParser()
parser.add_argument('--epoch', type=int, default=0, help='starting epoch')
parser.add_argument('--n_epochs', type=int, default=200, help='number of epochs of training')
parser.add_argument('--batchSize', type=int, default=1, help='size of the batches')
parser.add_argument('--dataroot', type=str, default='datasets/horse2zebra/', help='root directory of the dataset')
parser.add_argument('--lr', type=float, default=0.0002, help='initial learning rate')
##学习率下降的epoch
parser.add_argument('--decay_epoch', type=int, default=100, help='epoch to start linearly decaying the learning rate to 0')
parser.add_argument('--size', type=int, default=256, help='size of the data crop (squared assumed)')
parser.add_argument('--input_nc', type=int, default=3, help='number of channels of input data')
parser.add_argument('--output_nc', type=int, default=3, help='number of channels of output data')
parser.add_argument('--cuda', action='store_true', help='use GPU computation')
parser.add_argument('--n_cpu', type=int, default=8, help='number of cpu threads to use during batch generation')
opt = parser.parse_args()
print(opt)
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
###### =============================================定义变量 ######
# 网络名称 # 初始化生成器和判别器
netG_A2B = Generator(opt.input_nc, opt.output_nc)
netG_B2A = Generator(opt.output_nc, opt.input_nc)
netD_A = Discriminator(opt.input_nc)
netD_B = Discriminator(opt.output_nc)
if opt.cuda:
netG_A2B.cuda()
netG_B2A.cuda()
netD_A.cuda()
netD_B.cuda()
# 初始化权重
netG_A2B.apply(weights_init_normal)
netG_B2A.apply(weights_init_normal)
netD_A.apply(weights_init_normal)
netD_B.apply(weights_init_normal)
# 定义损失函数
criterion_GAN = torch.nn.MSELoss()#均方损失函数
#L1 loss用来让生成的图片和训练的目标图片尽量相似,而图像中高频的细节部分则交由GAN来处理,
#图像中的低频部分有patchGAN处理
#创建一个标准来测量输入xx和目标yy中每个元素之间的平均绝对误差(MAE),源码中的解释。
criterion_cycle = torch.nn.L1Loss()
criterion_identity = torch.nn.L1Loss()
# Optimizers & LR schedulers
# ===========================================定义优化器
#优化器的设置保证了只更新生成器或判别器,不会互相影响
#1.Adm算法 torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)
#2itertools.chain 迭代器能够将多个可迭代对象合并成一个更长的可迭代对象
optimizer_G = torch.optim.Adam(itertools.chain(netG_A2B.parameters(), netG_B2A.parameters()),
lr=opt.lr, betas=(0.5, 0.999))
#computing running averages of gradient and its square (default: (0.9, 0.999))
optimizer_D_A = torch.optim.Adam(netD_A.parameters(), lr=opt.lr, betas=(0.5, 0.999))
optimizer_D_B = torch.optim.Adam(netD_B.parameters(), lr=opt.lr, betas=(0.5, 0.999))
# =========================================定义学习率更新方式
#torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1)
#将每个参数组的学习率设置为给定函数的初始lr倍。 当last_epoch = -1时,将初始lr设置为lr
#lr_lambda:在给定整数参数empoch或此类函数列表的情况下计算乘法因子的函数,针对optimizer中的每个组一个函数.param_groups
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=LambdaLR(opt.n_epochs, opt.epoch, opt.decay_epoch).step)
# Inputs & targets memory allocation
Tensor = torch.cuda.FloatTensor if opt.cuda else torch.Tensor
input_A = Tensor(opt.batchSize, opt.input_nc, opt.size, opt.size)
input_B = Tensor(opt.batchSize, opt.output_nc, opt.size, opt.size)
target_real = Variable(Tensor(opt.batchSize).fill_(1.0), requires_grad=False)
target_fake = Variable(Tensor(opt.batchSize).fill_(0.0), requires_grad=False)
#首先定义好buffer 来源于工具包13行
#是为了训练的稳定,采用历史生成的虚假样本来更新判别器,而不是当前生成的虚假样本
#定义了一个buffer对象,有一个数据存储表data,大小预设为50,
#它的运转流程是这样的:数据表未填满时,每次读取的都是当前生成的虚假图像,
#当数据表填满时,随机决定 1. 在数据表中随机抽取一批数据,返回,并且用当前数据补充进来 2. 采用当前数据
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
# =========================================Dataset loader
transforms_ = [ transforms.Resize(int(opt.size*1.12), Image.BICUBIC), #调整输入图片的大小
transforms.RandomCrop(opt.size), #随机裁剪
transforms.RandomHorizontalFlip(),#随机水平翻转图像
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5), (0.5,0.5,0.5))
#归一化,这两行不能颠倒顺序呢,归一化需要用到tensor型
]
# =========================================加载训练数据集的方式
dataloader = DataLoader(ImageDataset(opt.dataroot, transforms_=transforms_, unaligned=True),
batch_size=opt.batchSize, shuffle=True, num_workers=opt.n_cpu)#两个数据集均打乱
# =========================================损失图
logger = Logger(opt.n_epochs, len(dataloader))
###################################
# ==========================================================Training ######
for epoch in range(opt.epoch, opt.n_epochs):
for i, batch in enumerate(dataloader):
# 输入
real_A = Variable(input_A.copy_(batch['A']))
real_B = Variable(input_B.copy_(batch['B']))
#===================================Generators A2B and B2A ######
# 生成器损失函数:损失函数=身份损失+对抗损失+循环一致损失
optimizer_G.zero_grad()
# Identity loss
# 如果输入实数B,则G_A2B(B)应等于B
same_B = netG_A2B(real_B)
loss_identity_B = criterion_identity(same_B, real_B)*5.0
# 如果输入实数A,则G_B2A(A)应等于A
same_A = netG_B2A(real_A)
loss_identity_A = criterion_identity(same_A, real_A)*5.0
# GAN loss
fake_B = netG_A2B(real_A)
pred_fake = netD_B(fake_B)
loss_GAN_A2B = criterion_GAN(pred_fake, target_real)
fake_A = netG_B2A(real_B)
pred_fake = netD_A(fake_A)
loss_GAN_B2A = criterion_GAN(pred_fake, target_real)
# Cycle loss(cycle consistency loss 循环一致性损失)
recovered_A = netG_B2A(fake_B)
loss_cycle_ABA = criterion_cycle(recovered_A, real_A)*10.0
recovered_B = netG_A2B(fake_A)
loss_cycle_BAB = criterion_cycle(recovered_B, real_B)*10.0
# Total loss
loss_G = loss_identity_A + loss_identity_B + loss_GAN_A2B + loss_GAN_B2A + loss_cycle_ABA + loss_cycle_BAB
loss_G.backward()
optimizer_G.step()
###################################
#===================================Discriminator A ######
optimizer_D_A.zero_grad()
# Real loss
pred_real = netD_A(real_A)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_A = fake_A_buffer.push_and_pop(fake_A)
pred_fake = netD_A(fake_A.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_A = (loss_D_real + loss_D_fake)*0.5
loss_D_A.backward()
optimizer_D_A.step()
###################################
#===================================Discriminator B ######
optimizer_D_B.zero_grad()
# Real loss
pred_real = netD_B(real_B)
loss_D_real = criterion_GAN(pred_real, target_real)
# Fake loss
fake_B = fake_B_buffer.push_and_pop(fake_B)
pred_fake = netD_B(fake_B.detach())
loss_D_fake = criterion_GAN(pred_fake, target_fake)
# Total loss
loss_D_B = (loss_D_real + loss_D_fake)*0.5
loss_D_B.backward()
optimizer_D_B.step()
###################################
# Progress report (http://localhost:8097)
logger.log({'loss_G': loss_G, 'loss_G_identity': (loss_identity_A + loss_identity_B), 'loss_G_GAN': (loss_GAN_A2B + loss_GAN_B2A),
'loss_G_cycle': (loss_cycle_ABA + loss_cycle_BAB), 'loss_D': (loss_D_A + loss_D_B)},
images={'real_A': real_A, 'real_B': real_B, 'fake_A': fake_A, 'fake_B': fake_B})
# Update learning rates
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
# Save models checkpoints
torch.save(netG_A2B.state_dict(), 'output/netG_A2B.pth')
torch.save(netG_B2A.state_dict(), 'output/netG_B2A.pth')
torch.save(netD_A.state_dict(), 'output/netD_A.pth')
torch.save(netD_B.state_dict(), 'output/netD_B.pth')
###################################
models.py
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
conv_block = [ nn.ReflectionPad2d(1),#参数是padding,使用输入 tensor的反射来填充
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
#torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
#Applies Instance Normalization over a 4D input (a mini-batch of 2D inputs with additional channel dimension) as described in the paper Instance Normalization: The Missing Ingredient for Fast Stylization .
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features) ]
#torch.nn.Sequential(*args)
#A sequential container.模型将按照在构造函数中传递的顺序添加到模型中。 或者,也可以传递模型的有序字典。
self.conv_block = nn.Sequential(*conv_block)
def forward(self, x):
return x + self.conv_block(x)
#=======================================================================Generator
#生成器部分:网络整体上经过一个降采样然后上采样的过程,中间是一系列残差块,数目由实际情况确定,
#根据论文中所说,当输入分辨率为128x128,采用6个残差块,当输入分辨率为256x256甚至更高时,采用9个残差块
class Generator(nn.Module):
def __init__(self, input_nc, output_nc, n_residual_blocks=9):
super(Generator, self).__init__()
# 初始卷积块
model = [ nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True) ]
#ReflectionPad2d()搭配7x7卷积,先在特征图周围以反射的方式补长度,使得卷积后特征图尺寸不变
#InstanceNorm2d()是相比于batchNorm更加适合图像生成,风格迁移的归一化方法,相比于batchNorm跨样本,
#单通道统计,InstanceNorm采用单样本,单通道统计,括号中的参数代表通道数
# 下采样
in_features = 64
out_features = in_features*2
for _ in range(2):
model += [ nn.Conv2d(in_features, out_features, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features*2
#残差块
for _ in range(n_residual_blocks):
model += [ResidualBlock(in_features)]
# 上采样
out_features = in_features//2
for _ in range(2):
model += [ nn.ConvTranspose2d(in_features, out_features, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_features),
nn.ReLU(inplace=True) ]
in_features = out_features
out_features = in_features//2
# 输出层
model += [ nn.ReflectionPad2d(3),
nn.Conv2d(64, output_nc, 7),
nn.Tanh() ] #nn.Tanh():Applies the element-wise function:
self.model = nn.Sequential(*model)
def forward(self, x):
return self.model(x)
#=======================================================================Discriminator
#判别器部分:结构比生成器更加简单,经过5层卷积,通道数缩减为1,最后池化平均,尺寸也缩减为1x1,
#最最后reshape一下,变为(batchsize,1)
class Discriminator(nn.Module):
def __init__(self, input_nc):
super(Discriminator, self).__init__()
# 卷积层
model = [ nn.Conv2d(input_nc, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True) ]
model += [ nn.Conv2d(256, 512, 4, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True) ]
# FCN 分类层
model += [nn.Conv2d(512, 1, 4, padding=1)]
self.model = nn.Sequential(*model)
def forward(self, x):
x = self.model(x)
# 平均池化和展开(view)
return F.avg_pool2d(x, x.size()[2:]).view(x.size()[0], -1)
pytorch 源码地址https://pytorch.org/docs/stable/nn.html