数据库学习笔记(1)
数据库学习笔记(1)
文章目录
- 数据库学习笔记(1)
- @[toc]
- redis
- 是什么
- 存储的数据类型
- redis关键技术
- 事件循环
- 逐出
- 过期
- 持久化
- 主从复制(异步操作:写入成功即成功)
- pipeline
- mget
- redis集群:一致性hash&redis cluster
- redis 客户端: 服务发现
- 什么是服务发现
- 数据库删除
- 逻辑删除
- 物理删除
- 后记
- mongoDB
- __v字段
- 数据库事务
- 概念
- 性质
- 关系型数据库 vs 非关系型数据库
- 聚合函数 DB
- 聚合函数是什么
- 常见的聚合函数
- 注意点
- 数据库查询mongodb
- 模糊查询
- 条件查询
文章目录
- 数据库学习笔记(1)
- @[toc]
- redis
- 是什么
- 存储的数据类型
- redis关键技术
- 事件循环
- 逐出
- 过期
- 持久化
- 主从复制(异步操作:写入成功即成功)
- pipeline
- mget
- redis集群:一致性hash&redis cluster
- redis 客户端: 服务发现
- 什么是服务发现
- 数据库删除
- 逻辑删除
- 物理删除
- 后记
- mongoDB
- __v字段
- 数据库事务
- 概念
- 性质
- 关系型数据库 vs 非关系型数据库
- 聚合函数 DB
- 聚合函数是什么
- 常见的聚合函数
- 注意点
- 数据库查询mongodb
- 模糊查询
- 条件查询
2020/04/14 add 数据库查询(mongoDB)
2020/04/17 add 数据库聚合函数
2020/04/17 add 关系型数据库和非关系型数据库
2020/04/19 add 数据库事务
2020/05/08 add mongoDB
2020/05/13 add 数据库删除
2020/05/20 add redis
redis
在实际的应用中,是把它放在业务和 DB 中间进行使用
是什么
Redis (Remote Dictionary Server) is an open-source in-memory data structure project implementing a distributed, in-memory key-value database with optional durability.
Redis 作为一种远程缓存服务,可以帮助DB抗一些请求来做高性能的数据查询
存储的数据类型
Redis 数据类型
List: 按照插入的顺序排序的字符串链表。和数据结构中的普通链表一样,可以在其头部(left)和尾部(right)添加新的元素。在插入元素时,如果该键不存在,Redis将为该键创建一个新的链表。如果链表中所有的元素均被移除,那么该键也会从数据库中删除。
redis关键技术
事件循环
redis整个是一个单线程服务。启动后即陷入巨大的while循环,不停地处理文件事件和时间事件。
- 文件事件: 在多个客户端中实现多路复用,接受它们发来的命令请求,并将命令的执行结果返回给客户端。【即响应请求】
- 时间事件:记录那些要在指定时间点运行的事件,多个时间事件以无序链表的形式保存在服务器状态中 【redis为了维持其作为数据库的状态进行的一些定时任务】
- 关闭、清理失效的客户端连接
- 检查是否需要RDB dump,AOF重写 Redis持久化 - RDB和AOF 进程和线程的区别介绍
- 数据库后台操作,key过期清理、数据库rehash等
整个流程是这样的:
beforeSleep -> epollwait -> 处理请求 -> 定时事件 ->xx
建议: 减少大 key,减少耗时命令。
beforeSleep的执行频率一般比定时事件更频繁一些。主要做以下几件事:
- cluster集群状态检查,ok->fail、fail->ok
- 处理被block住的的client,如一些阻塞请求BLPOP等
- 将AOF buffer持久化到AOF文件
逐出
redis是一个内存服务,会设定内容上限的。
逐出 - 当执行write但内存达到上限时,强制将一些key删除
- allkeys - 所有key
- volatile - 设置了过期的key
- LRU - 最久未被使用
- random - 随机
- ttl - 最快过期的
特点:
- 不是精准算法,而是抽样比对
- 每次写入操作前判断
- 逐出是阻塞请求的
建议:关注逐出qps,过高会影响正常请求处理
过期
过期 - 当某个key到达了ttl(time to live)时间,认为该key已经失效
两种方式:
惰性删除 - 读、写操作前判断ttl,如过期则删除
定期删除 - 在redis定时事件中随机抽取部分key判断ttl
特点
并不一定是按设置时间准时地过期
定期删除的时候会判断过期比例,达到阈值才退出
建议:打散key的过期时间,避免大量key在同一时间点过期
持久化
redis虽然作为一个缓存存在,通常作为业务和DB之间的一个衔接,如果只保存在内存中,不进行持久化机器宕机之后就会造成数据的丢失。
ps: 内存和磁盘有什么样的区别??
持久化 - 将内存中的数据dump到磁盘文件
-
RDB持久化(一次性写入)
- 经过压缩的二进制格式
- fork子进程dump可能造成瞬间卡顿
-
AOF持久化(总是在写入追加,因此这个文件会越来越大,因此也就有了AOF重写)
- 保存所有修改数据库的命令
- 先写aof缓存,再同步到aof文件
- AOF重写,达到阈值时触发,减小文件大小(利用替换的策略)
应用:利用AOF文件灾备
- 可将数据恢复到最近3天任意小时粒度
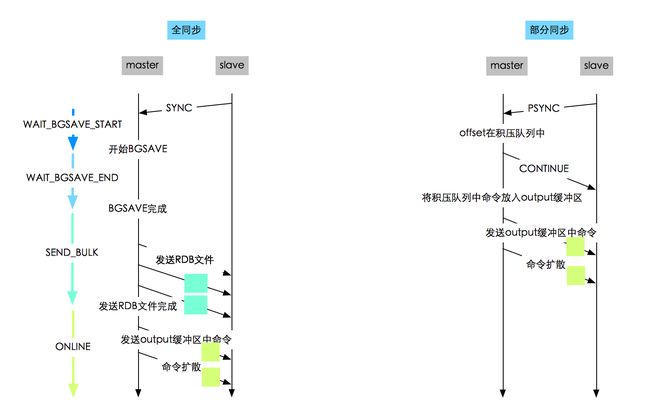
主从复制(异步操作:写入成功即成功)
主从模式
- 主、从节点都可以挂从节点
- 最终一致性
全量同步
- 传递RDB文件&restore命令重建kv
- 传递在RDB dump过程中的写入数据
部分同步
- 根据offset传递积压缓存中的部分数据
- 注:每一个master上都有对应的slave的output缓存区
- 注:如果slave向master请求的offset不在积压队列中,那么就会发起一次全量的同步
pipeline
优点:
- 节省往返时间;
- 减少了proxy、redis server的IO次数
mget
- client: 使用mget命令
- redis: 一个命令中处理多个key;等所有key处理完后组装回复一起发送
- twemproxy:拆key分发到不同redis
- server;需要等待、缓存mget中全部回复
优点:
- 节省往返时间
缺点:
- proxy缓存mget结果;
- mget延时是最后一个key回复时间,前面的key需要等待
建议:利用pipeline代替mget,且控制一次请求的命令数量(建议50以内)(因为proxy做分发也会产生一定的压力)
注:
和pipeline的区别
- pipeline处理完一个请求即返回
- mget 等所有key处理完后组装回复一起发送
redis集群:一致性hash&redis cluster
一致性hash:
- 实例宕机、加节点容易造成数据丢失
- 注:如果要做水平扩容,即增加redis实例,不会对原有的数据进行搬迁,改变拓扑会造成原有的key miss掉
redis cluster(涉及缓存的业务尽量用这种集群方式):
- 节点之间两两通信,有节点数量上限
redis 客户端: 服务发现
什么是服务发现
什么是服务发现
数据库删除
逻辑删除
逻辑删除记录,不会直接删除数据库中的数据,仅是通过某些手段屏蔽被逻辑删除的数据在前台的显示,不会释放物理空间,并且还可以从数据库中查得数据。
物理删除
物理删除记录,即是会将数据库中的数据记录直接清除(也可以说是磁盘上的删除),会释放出物理空间,也将不能再从数据库中搜索到删去的数据记录;
后记
一般来讲大部分公司都采用逻辑删除的方式:对数据记录用处极大
逻辑删除真的不是一个好的设计
mongoDB
__v字段
mongodb中的__v字段
“__v” 是 “versionKey"的简写,当每一个文档由mongoose创建时就会自动添加,代表这该文档的版本,此属性可配置修改,默认为“__v”,
作用是可以在"save文档"时作为一个查询条件,避免在"取出数据"到"save数据"的这段时间内,数据被其他进程修改而导致冲突。
数据库事务
数据库事务
概念
数据库事务( transaction)是访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。事务由事务开始与事务结束之间执行的全部数据库操作组成。
性质
- 原子性(Atomicity):事务中的全部操作在数据库中是不可分割的,要么全部完成,要么全部不执行。
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序 串行执行的结果相一致。
- 夺隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 夺持久性(Durability):对于任意已提交事务,系统必须保证该事务对数据库的改变不被丢失,即使数据库出现故障。
事务的ACID特性是由关系数据库系统(DBMS)来实现的,DBMS采用日志来保证事务的原子性、一致性和持久性。日志记录了事务对数据库所作的更新,如果某个事务在执行过程中发生错误,就可以根据日志撤销事务对数据库已做的更新,使得数据库同滚到执行事务前的初始状态。
对于事务的隔离性,DBMS是采用锁机制来实现的。当多个事务同时更新数据库中相同的数据时,只允许持有锁的事务能更新该数据,其他事务必须等待,直到前一个事务释放了锁,其他事务才有机会更新该数据。
关系型数据库 vs 非关系型数据库
工作原因,平常会比较多用mongoDB,而它实际区别于以前用过的譬如mysql oracle等
关系型数据库和非关系型数据库举例
常见的关系型数据库和非关系型数据及其区别
聚合函数 DB
深入理解数据库当中的聚合函数
SQL中的聚合函数介绍
聚合函数是什么
聚合函数对一组值执行计算并返回单一的值。
在数据库当中,函数分为两种:单行函数和多行函数,相应概念如下:
单行函数:每一行返回一个数值(如lower)
多行函数:多行返回一个数值(如count)
聚合函数:多行函数,即表中的多条记录返回至一个数值,通常用于分组的相关信息。
常见的聚合函数
聚合函数的分类:(常用的5个)
- count:
- count(*):统计表中所有记录的个数
- count(列名):统计一列中值的个数,其中重复的记录也会被当做有效的记录。
- count(distinct 列名):统计一列中值的个数,其中重复的记录只会被记录一次。
- sum(列名):计算一列值的总和。
- avg(列名):计算一列值的平均值。
- max(列名):计算一列值中的最大值。
- min(列名):计算一列值中的最小值。
我认为只要记住count为统计一列中值的个数就可以了,因为里面毕竟是distinct的用法。
注意点
- 聚合函数同order by、distinct、top等都是一样的,都是作用于最终的结果集合的,而不是最用于单行元组的,所以在SQL语句的处理过程当中一定要分清该关键字是作用域单行记录的,还是作用于最终的结果集合的。
- 在聚合函数遇到空值的时候,除count(*)外,所有的聚合函数都会跳过空值而只处理非空值。
- 单行函数和多行函数不能混合使用。
- 如果未对查询结果进行分组,聚集函数将作用于整个查询结果,而分组后聚集函数将作用于每一个组,即每一个组都有一个函数值。
数据库查询mongodb
模糊查询
{name:/xxx/} // 包含
{name:/^xxx/} // 以xxx开头
{name:/xxx^/} // 以xxx结尾
{name:/xxx/i} // 忽略大小写
条件查询
db.collections.find({'name':{$in:['tommy'],['Ammy']}) // 查询名字叫Tommy 和 Ammy的人