Andrew Ng机器学习入门学习笔记(六)之支持向量机(SVM)
一.支持向量机的引入
支持向量机(SVM)是一种极受欢迎的监督学习算法,为了引入支持向量机,我们首先从另一个角度看逻辑回归。
1.从单个样本代价考虑
假设函数 hθ(x)=11+e−θTx 。由于S型函数有如下图的特性,

则,如果 y=1 ,那我们希望 hθ(x)≈1 ,即 θTx>>0 ;如果 y=0 ,那我们希望 hθ(x)≈0 ,即 θTx<<0 。
对于逻辑回归,对于单个样本 (x,y) ,其代价为
①如果 y=1 ,上述单个样本代价函数中只有第一项起作用,第二项为 0 。
令 z=θTx ,此时代价随 z 的变化曲线如下图所示

结合此图也可以看出对于正样本(即, y=1 ),为了使代价 −log11+e−θTx 最小,我们将设置 θTx 比较大,这时代价接近于 0 。
在支持向量机中这种情况可以用两条线段作为新的代价函数 cost1(z) ,如下图桃红色部分

②如果 y=0 ,上述单个样本代价函数中只有第二项起作用,第一项为 0 。
此时代价随 z 的变化曲线如下图所示,

结合此图也可以看出对于负样本(即, y=0 ),为了使代价 −log(1−11+e−θTx) 最小,我们将设置 θTx 比较大,这时代价接近于 0 。
在支持向量机中可以用两条线段作为新的代价函数 cost0(z) ,如下图桃红色部分

2.从优化目标考虑
对于逻辑回归,优化目标是
支持向量机就是要将其中的 (−loghθ(x(i))) 换成前面 y=1 时新的单个样本代价 cost1(θTx(i)) ,将 (−log(1−hθ(x(i)))) 换成前面 y=0 时新的单个样本代价 cost0(θTx(i)) ,即
又由于无论是否有 1m 都不会影响最小化的结果,故可以忽略 1m ;
同时正则化逻辑回归总的代价函数包括两项,即 A+λB (通过 λ 控制 A,B 间的平衡),SVM则通过另一种方式控制 A,B 间的平衡,即 CA+B 。
综上,SVM的优化目标为
二.SVM的决策边界
1.SVM优化目标进一步研究
为了最小化代价函数, y=1 时,我们希望 θTx⩾1 ,而不仅仅像逻辑回归那样只要 θTx⩾0 ,就可以预测 hθ(x)=1 ;
同理, y=0 时,我们希望 θTx⩽−1 ,而不仅仅像逻辑回归那样只要 θTx<0 ,就可以预测 hθ(x)=0 。
可以看出SVM相比逻辑回归而言要求更高,相当于多了一个安全的间距因子。故人们也会将SVM看作是大间距分类器。
当 C 为一个很大的值时,为了
y(i)=1 时,希望 cost1(θTx(i))=0 ,即 θTx(i)⩾1 ;
y(i)=0 时,希望 cost0(θTx(i))=0 ,即 θTx(i)⩽−1 。
综上,SVM的优化目标为
2.SVM的决策边界
SVM的这个要求会对决策边界有什么影响呢?
以一个线性可分数据集为例,有多条直线可以把正样本与负样本分开,如下图:

SVM会趋于以黑色线来分离正、负样本,因为黑色线和训练样本间有更大的最短距离,而粉色线和绿色线在分离样本时表现就较差。SVM总是努力用最大间距(margin)来分离样本,这也是它为什么被称为大间距分类器,同时这也是SVM具有鲁棒性的原因。
事实上,SVM比大间距分类器表现得更成熟,比如异常点的影响,如图:

参数 C 控制着对误分类的训练样本的惩罚,故参数 C 较大时会努力使所有训练数据被正确分类,这会导致仅仅因为一个异常点决策边界就能从黑色线变成粉色线,这是不明智的。SVM可以通过将参数 C 设置得不太大而忽略掉一些异常的影响, C 的作用类似于 1λ ,对于这个例子仍然会得到黑线线代表的决策边界。
3.大间距分类背后的数学
前面说到SVM的优化目标是
其中, ||θ|| 为向量 θ 的长度或称为 θ 的范数。
如果将 θTx(i) 看成是经过原点的两个向量相乘,如下图:
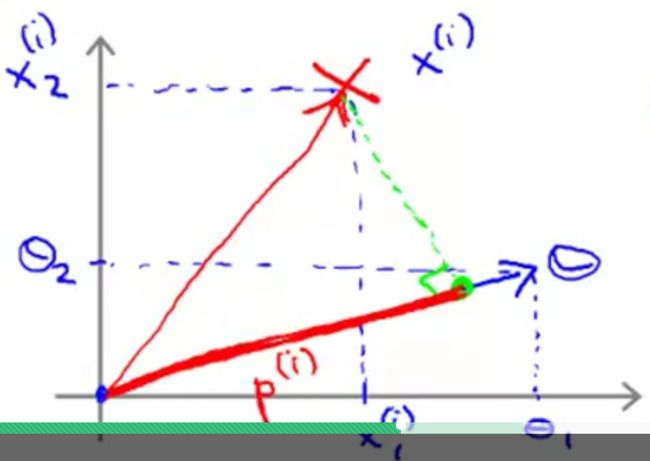
则 θTx(i) 等价于向量 x(i) 在向量 θ 上的投影 p(i) 与 θ 的范数 ||θ|| 相乘,即
故SVM的优化目标就变为:
①小间距决策边界
假设 θ0=0 ,下图展示了一个小间距决策边界的例子。(绿色线为决策边界)

向量 θ 的斜率为 θ2θ1 ,决策边界为 θTx=0 ,即 θ1x+θ2y=0 ,斜率为 −θ1θ2 ,也就是说决策边界也过原点且与向量 θ 垂直。
取上图中最贴近决策边界的一个正样本(红叉)点 x(1) ,因为正样本点 y(1)=1 ,故要求 p(1)||θ||⩾1 。但事实是这种小间距决策边界, x(1) 在向量 θ 上的投影 p(1) 非常小,这就要求 ||θ|| 很大,显然这与优化目标 minθ12∑j=1nθ2j=minθ12||θ||2 不符。
同理,上图中最贴近决策边界的一个负样本(蓝圈)点 x(2) ,因为负样本点 y(2)=0 ,故要求 p(2)||θ||⩽−1 。 x(2) 在向量 θ 上的投影 p(2)<0且|p(2)|也非常小 ,这也要求 ||θ|| 很大。
由于这种小间距决策边界的选择与SVM的优化目标不符,故SVM不会选择这种决策边界。
②大间距决策边界
假设 θ0=0 ,下图展示了一个大间距决策边界的例子。(绿色线为决策边界)
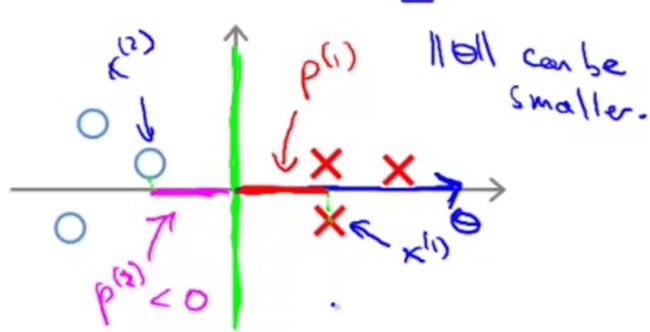
同样的,决策边界也是和向量 θ 垂直的。不同的是,对于正样本点 x(1) ,它在 θ 上的投影 p(1) 比小间距分类那里的要长多了;对于负样本点 x(2) ,它在 θ 上的投影 p(2) 的长度比小间距分类那里也要长很多。在满足SVM优化目标的要求时, ||θ|| 可以变小而不必很大。
反过来看,通过在优化目标里让 ||θ|| 不断变小,SVM就可以选择出上图所示的大间距决策边界。这也是SVM可以产生大间距分类器的原因。
以上我们都是假设 θ0=0 ,这会让决策边界通过原点,幸运的是即使 θ0≠0 ,SVM会产生大间距分类仍然是成立的。
三.核函数(Kernels)
SVM利用核函数可以构造出复杂的非线性分类器。如下图
1.SVM的假设函数
2.非线性决策边界特征变量的定义
例如假设函数
我们可以定义特征项 f1=x1,f2=x2,f3=x1x2,f4=x21,⋯ ,
则 θ0+θ1x1+θ2x2+θ3x1x2+θ4x21+⋯=θ0+θ1f1+θ2f2+θ3f3+θ4f4+⋯
对于SVM,有没有比这些高阶项更好的特征项?
给定 x ,根可以据与标记点的接近程度来计算新的特征项。如下图手动选择了3个标记点 l(1),l(2),l(3) 。

则,
更具体点,忽略 x0 ,则上述
如果 x 的位置接近于 l(1) ,即 x≈l(1) ,则
相反,如果 x 的位置远离于 l(1) ,则
故,有三个标记点时,给定一个 x ,就可以计算出3个新的特征。
例如: l(1)=[35],σ2=1,n=2 时
x=[35] 时, f1=1 ;而 x 在离 [35] 较远时,如下图的边缘位置,则 f1≈0 。

f 的值在0与1之间,具体取决于 x 与标记点 l 的接近程度。
改变核函数中 σ2 的大小,如减小到 σ2=0.5 ,可看到突起变窄了,从1降到低处的速度会变得更快,如下图

若增大 σ 到 σ2=3 ,则突起会变宽,新的特征值从大减小的速度会变慢,如下图

3.通过核函数和标记点构造复杂的非线性边界
假设只考虑3个标记点,根据SVM假设函数的定义,若 θ0+θ1f1+θ2f2+θ3f3⩾0 ,则预测 y=1 。
假设 θ0=−0.5,θ1=1,θ2=1,θ3=0 ,标记点和训练样本的位置如下图:

则,对于桃红色的那个训练样本,根据前面SVM新特征项的定义, f1≈1,f2≈0,f3≈0 ,因为 θ0+θ1f1+θ2f2+θ3f3=0.5⩾0 ,故预测 y=1 。
对于蓝绿色的那个训练样本, f1≈0,f2≈0,f3≈0 ,因为 θ0+θ1f1+θ2f2+θ3f3=−0.5<0 ,故预测 y=0 。
综上可以发现,对于接近标记点 l(1) 或 l(2)的点,预测结果为 y=1 ,而对于那些远离标记点 l^{(1)} 和 l^{(2)}的点,预测结果为 y=0 。
故,最终的决策边界会是非线性的,在边界内部预测 y=1 ,在边界外部预测 y=0 ,如下图

这就是通过核函数和标记点来训练出复杂的非线性决策边界的方法。
4.标记点的选择及特征向量的构造
在实际应用中,如何选择这些标记点 l(1),l(2),l(3),⋯ 是机器学习必须解决的问题。
给定 m 个训练样本 (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m)) ,可以选择 l(1)=x(1),l(2)=x(2),⋯,l(m)=x(m) ,即选择与样本点重合的位置作为标记点。
给定一个样本 x (可属于训练集,交叉验证集或测试集),则
f(i)0=1
f(i)1=similarity(x(i),l(1))
⋮
f(i)i=similarity(x(i),l(i))=similarity(x(i),x(i))=1
⋮
f(i)m=similarity(x(i),l(m))
合成一个可以用来描述样本 x(i) 的特征向量
四.SVM实现
1.假设函数
假设已经有了参数 θ ,给定一个 x ,可以计算出特征向量 f∈Rm+1 (标记点个数等于训练样本数)。则SVM假设函数的定义变为,若 θTf=θ0f0+θ1f1+⋯+θmfm⩾0 ,则 hθ(x)=1 ,其他情况则 hθ(x)=0 。
2.优化目标
有了核函数之后,SVM的优化目标如下:
另外,在SVM的实现中,最后一项略有差别, ∑nj=1θ2j 本应等于 θTθ ,也就是 ||θ|| ,但是在SVM的实现中使用 θTmθ 却比直接优化 ||θ|| 更高效,更能适应超大的训练集。
需要注意,上述那些SVM的计算技巧应用到别的算法,如逻辑回归中,会变得非常慢,所以一般不将核函数以及标记点等方法用在逻辑回归中。
3.SVM的参数
前面提到参数 C 相当于逻辑回归中的 1λ ,那么参数 C 对方差和偏差的影响如下:
C 太大,相当于 λ 太小,会产生高方差,低偏差;
C 太小,相当于 λ 太大,会产生高偏差,低方差。
同时,参数 σ2 也会对方差和偏差产生影响:
σ2 大,则特征 fi 变化较缓慢,可能会产生高偏差,低方差;
σ2 小,则特征 fi 变化不平滑,可能会产生高方差,低偏差。
4.使用SVM及核函数的选择
在具体实现时,我们不需要自己编写代码来最优化参数 θ ,而是使用SVM软件包(如:liblinear,libsvm等)来最优化参数 θ 。
当然了,在使用这些软件包时,我们需要自己选择参数 C 以及选择使用哪种核函数。
例如:选用线性核函数(即,没有使用核函数),若 θTx=θ0+θ1x1+⋯+θnxn>0,则hθ(x)=1 。最终这会产生一个线性分类器。liblinear就是使用线性核函数。
如特征数 n 很大,而训练样本数 m 很小,使用线性核函数产生一个线性分类器就较为适合,不容易过拟合。
如果特征数 n 很小,而训练样本数 m 很大,就适合用一个核函数去实现一个非线性分类器,高斯核函数是个不错的选择。
如果使用的是高斯核函数: fi=exp(−||x−l(i)||22σ2) ,其中 l(i)=x(i) ,则还需要选择参数 σ2 。
核函数还有一些其他选择,需要注意的是,不是所有的相似度函数都是有效的核函数,要成为有效的核函数,需要满足默塞尔定理这个技术条件。
还有一些其他核函数如:多项式核函数,字符串核函数等等,但大多数时候我们用的还是高斯核函数。
5.多类别分类问题
对于 K 类分类问题,可以使用已经内置了多类别分类函数的SVM软件包,也可以用一对多(one-vs-all)的方法训练 K 个SVM分类器,把 y=i ( i=1,2,⋯,K )的类同其他类区别开来,得到 K 个参数向量 θ(1),θ(2),⋯,θ(K) 。
对于输入的 x ,选择 (θ(i))Tx 最大的那个类别 i 作为识别结果。
6.SVM和逻辑回归的选择问题
什么时候该用逻辑回归?什么时候该用SVM?
①如果 n 相对于 m 来说很大,则应该使用逻辑回归或者线性核函数(无核)的SVM。
m 较小时,使用线性分类器效果就挺不错了,并且也没有足够的数据去拟合出复杂的非线性分类器。
②如果 n 很小, m 中等大小,则应该使用高斯核函数SVM。
③如果 n 很小, m 很大,则高斯核函数的SVM运行会很慢。这时候应该创建更多的特征变量,然后再使用逻辑回归或者线性核函数(无核)的SVM。
对于以上这些情况,神经网络很可能做得很好,但是训练会比较慢。实际上SVM的优化问题是一种凸优化问题,好的SVM优化软件包总是能找到全局最小值或者是接近全局最小的值。