团队开发框架核心架构—Value Objects
本篇将介绍另一个重要的构造块——值对象,它是聚合中的主要成分。
如果说你已经在使用DDD分层架构,但你却从来没有使用过值对象,这毫不奇怪,因为多年来养成的数据建模思维已经牢牢把你禁锢,以致于你在使用面向对象方式进行开发时,还是以数据为中心。
当我们完成了基本的需求分析以后,如果说需要进行设计,那么你能想到的就是数据库表及表关系的设计,这就是数据建模。数据建模的主要依据是数据库范式设计,根据要求严格程度的递增分为第N范式,基本的要求是把每个标量属性值用单独的一列来存储,每个非键属性必须完全依赖于键属性。数据库范式设计的目标是消除存储在多个位置上的冗余数据,以免导致更新异常。为了达到这个目的,需要进行不断的表拆分,直到每个表都只表示一个单一的概念。这可以认为是SRP(单一职责原则)在表上的应用,从而使表中的数据产生更高的内聚性。这从数据库的角度看可能是不错的,但对于面向对象开发却不见得是个好事。
每一个表称为一个数据库实体。当你完成了表设计以后,很自然的把数据库实体与DDD实体等同起来,这产生了一个直观的映射,所以每个表在你的系统中都是一个实体。受这个根深蒂固的开发模式影响,你与值对象无缘相见。
值对象不仅在概念上提供强大的帮助,而且在技术上,特别是持久化方面能够大幅简化系统设计,后面我将逐步介绍聚合与值对象是如何帮助你降低系统复杂性而脱困的。
什么是值对象
通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体。
在值对象的概念中,隐含了如下信息:
- 值对象可以对某些简单业务概念建模。
- 值对象没有标识。值对象比实体简单得多,不需要跟踪变化,所以它没有标识。
- 值对象是不可变的。这是值对象的核心特征,后面将详述。
- 值对象的相等性比较是通过各个属性值的比较来完成的。
- 由于值对象代表一个概念整体,所以只能进行整体替换,而不是修改值对象的某个属性。
值对象的价值
看了上面的概念描述,可能并不能打动你。你会说“实体不就比值对象多一个标识,能复杂到哪去”。由于你使用实体同样可以对业务概念建模,所以是否使用值对象,对你来说根本不重要。
下面来看看使用值对象的其它好处。
值对象的一个作用是可以帮助优化性能。当一个值对象需要在多个地方使用时,可以共享同一个值对象。为了共享同一个值对象,你可以使用工厂来创建单例模式的值对象实例,由于值对象是不可变的,所以可以安全的使用。
当然,你可能对使用值对象来提升性能也不感兴趣,你需要更实在的好处,否则就免谈。下面将介绍值对象的重型武器,它对你将产生空前的影响,甚至颠覆你平时的建模习惯和开发模式。
前面已经说过,你为了满足数据库规范化设计,创建大量的表,各个表之间关系错综复杂,而且你也意识到正是表的膨胀导致了系统复杂性的上升。如果能够减少表的数量,那么表之间的关系也会变得简单和清晰,有什么办法可以减少表的数量吗?答案就是值对象与逆范式设计。
首先来看一个简单情况。现在要为人力资源系统建立员工档案,我们使用一个名为Employee的员工类来表示这个业务概念,除了名字以外,还要管理他的地址信息,我们可以将地址信息直接放到员工实体上,数据库表结构与员工实体一样,代码如下所示。
public class Employee : Entity
{
public string Name { get; set; }
public string Province { get; set; }
public string City { get; set; }
public string County { get; set; }
public string Street { get; set; }
public string Zip { get; set; }
}
不过你的数据库规范化专业技能非常敏感,让你察觉到这几个地址属性都不完全依赖于员工主键,所以你决定专门建一张地址表,再把地址表与员工表关联起来。
你的代码也作出相应调整如下。
using System;
namespace Rdf.Domain.Entities
{
public class Employee : Entity
{
public string Name { get; set; }
public Guid AddressId { get; set; }
public Address Address { get; set; }
}
public class Address : Entity
{
public string Province { get; set; }
public string City { get; set; }
public string County { get; set; }
public string Street { get; set; }
public string Zip { get; set; }
}
}
可以看到,对于这样的简单场景,一般有两个选择,要么把属性放到外部的实体中,只创建一张表,要么建立两个实体,并相应的创建两张表。第一种方法的问题是,一个整体业务概念被弱化成一堆零碎的属性值,不仅无法表达业务语义,而且使用起来非常困难,同时将很多不必要的业务知识泄露到调用端。第二种方法的问题是导致了不必要的复杂性。
更好的方法很简单,就是把以上两种方法结合起来。我们通过把地址建模成值对象,而不是实体,然后把值对象的属性值嵌入外部员工实体的表中,这种映射方式被称为嵌入值模式。换句话说,你现在的数据库表采用上面的第一种方式定义,而你在C#代码中通过第二种方式使用,只是把实体改成值对象。这样做的好处是显而易见的,既将业务概念表达得清楚,而且数据库也没有变得复杂,可谓鱼和熊掌兼得。
使用嵌入值模式映射值对象,你发现将部分违反范式设计的规则,这正是数据建模与对象建模一个重要的不同之处。要想尽量的发挥对象的威力,就需要弱化数据库的作用,只把他作为一个保存数据的仓库。对象建模越成功,与数据建模就会差别越大。所以当违反数据库设计原则时,不用大惊小怪,只要业务能够顺利运行,就没什么关系。
使用嵌入值进行映射的另一个优势是能够优化查询性能,因为不需要进行联表,单表索引调优也要容易得多。
嵌入值映射基本没什么副作用,它是单个值对象的标准映射方式。但是,嵌入值映射只能映射单个值对象,如果值对象是一个集合会怎样?
继续我们的员工管理模块,客户要求能够管理员工的教育经历、职务变动等一系列和该员工相关的附属信息,而且这些附属信息都是多行记录,比如教育经历,他从小学一直到博士的所有教育经历,需要多次录入。从数据库的角度,就是主从表设计,员工是主表,其它都是从表。从对象的角度考虑,外层的员工是聚合根,附属的所有信息都是聚合内部的子对象,要么建模成实体,要么建模成值对象,它们从概念上构成一个整体,即聚合。
现在先来看传统的主从表建模方式,每个附属信息都需要创建一个表,并映射成一个实体。如果附属信息有10种,那么一共需要创建11个表,可以看到,表数据大量增加,从而导致系统变得复杂。另外,考虑员工管理在界面上的操作,可以在界面上放一个选项卡来显示员工的每项附属信息,现在如果要添加员工的教育经历,一种简单的方法是在添加完一条教育经历以后立即保存并刷新。但有时为了易用性等考虑,允许客户在界面上随意操作,并在最后一步点击保存按钮一次性提交。把一个包含多个实体集合的聚合提交到服务端进行持久化,这可能非常复杂,需要从数据库中将聚合取出,然后通过标识判断出每个子实体,哪些是新增的,哪些是修改的,哪些是已经删除的。
如果把实体换成值对象,情况就大不相同了,将大幅简化系统设计。前面介绍了单个值对象通过嵌入值模式映射,那么现在是值对象集合,如何映射呢?由于你不可能把值对象集合的每个元素映射到外层的实体表中,但是创建多个表又增加复杂性,所以一个变态的方法是使用序列化大对象模式。把一个值对象的集合直接序列化到表中的一个字段中,这甚至违反了数据建模第一范式。可以看到,这种保存数据的方式已经颠覆了你平时的习惯。
说到这里,很多人可能准备质疑这个示例的建模方案了,这些子对象能不能被建模成值对象,甚至应不应该放到员工聚合中都要看具体情况,需要考虑多方面因素,诸如业务需求,查询需求,并发和性能需求等,现在假设,员工的附属信息使用值对象建模没什么问题,我们来看看对系统的简化有多大改观。
首先,11个表被简化成了1个表,在表中增加了10个列而已。这个简化简直惊人。
另外再来看看界面上的操作,如果需要一次性提交整个聚合,由于值对象没有标识,而且是整体替换的,所以你不需要从数据库中把聚合拿出来作比较,只需要重新一个序列化,就万事大吉。
从上面可以看出,值对象可以帮你大幅简化持久化方面的工作,这都打动不了你,我确实也无话可说。
值对象的设计要点
值对象必须不可变。
不变性是值对象的一个基本特征,为何要如此严格的规定?有几个原因:
- 值对象代表的就是一个值,这个值是一个整体,如果需要修改,必须整个替换,不能部分修改。这是从概念上说明值对象的不变性。
- 为了安全的使用值对象,防止别名Bug。前面说过,值对象的一个作用是优化性能,减少内存占用,这是通过共享同一个值对象来实现的。如果值对象允许修改,当一个值对象被多个其它对象共享时,如果其中一个对象改变了值对象的某个属性值,这个改变在其它对象上也会马上生效,可能导致严重的问题,这被称为别名Bug。另外,将值对象进行引用传递时,值对象在其它代码中可能发生任何操作。这是从技术上保证值对象只有不可变,才能安全的使用,不然随时可能担心吊胆,当发生Bug时也很难跟踪。
- 当把值对象作为Dictionary这样的哈希集合的键时,哈希集合会使用值对象的GetHashCode计算出一个地址,并将值保存在这里,之后,如果需要查找一个值,通过值对象的GetHashCode重新计算出该地址,然后把值提取出来。如果值对象是可变的,当把数据保存到哈希集合之后,修改了值对象,那么通过值对象重新计算出来的hashcode可能不同,从而丢失了这个值。
使用Object建模值对象,而不是Struct。
想想看,我们现在讨论的值对象,它的不变性与.Net提供的值类型Struct如此相似,那么是不是应该使用Struct建模值对象呢?不行,原因如下:
- Struct用来实现基元类型,比如int,这些类型都非常小,专家建议不要超过16字节大小。我们现在的值对象虽然比实体可能简单些,但还是可能很庞大。一个比较大的对象,从性能上考虑,放入堆中进行垃圾回收更合适,实际上string就是一个值对象。
- 如果使用像Entity Framework这样的ORM框架,它可能不支持Struct的映射。
嵌入值模式映射列名可以遵循一定命名规则。
当使用嵌入值模式进行映射时,在聚合表中,可以根据层次关系命名列名。比如员工聚合中的地址值对象的城市属性,可以命名为:Employee_Address_City,或者Address_City,这样可以更清晰的表达子对象的映射关系。
使用值对象的挑战
使用值对象的第一个挑战来自关系数据库。
从上面的例子可以看到,值对象可以极度简化系统设计是因为采用了序列化大对象模式。但是这种设计方式存在很多弊端,最重要的是导致搜索值对象属性值变得异常困难。比如,客户提出,需要根据员工教育经历的学校名称进行搜索,以查找哪些员工在某个学校曾经读过。
采用序列化大对象模式,一种方式是序列化成二进制流,然后保存到Sql Server的varbinary(MAX)字段中。如果采用这种方式存储,当我们要搜索教育经历的学校名称时,只能把所有员工读取到内存进行过滤。除此之外,当你直接查看数据库时,将完全不知所云,相信你不会牛B到能读懂二进制流的境界。还有一个问题是,当值对象的结构发生变化,比如你增加了几个属性,可能在反序列化时失败。所以这种方式不被推荐。
另一种方式是序列化成文本流,保存到Sql Server的nvarchar(MAX)字段中。你可以选择XML格式,或者JSON格式。一般来讲JSON要好得多,不仅占更少空间,而且更加简单清晰。当我们要搜索教育经历的学校名称时,可以在nvarchar(MAX)字段中通过Like进行搜索,这样虽然不是太高效,但比起读取全部员工实体进行过滤还是要强些。
值对象集合的搜索解决办法如下:
- 根本不提供值对象属性的查询条件。这一点需要你的客户或老板通人性才行,另外也有一些技巧。如果你直接告诉老板,这个搜索功能做不了,你的老板会大发雷霆“这么简单都做不出来,我要你来干嘛”。但是,如果你告诉老板不提供这几个搜索条件,可以提前两天完工,他有可能就批了。
- 更换成NOSQL数据库,比如MongoDB。MongoDB支持层次化存储和查询,从而从根本上解决问题。但不是每个系统都能用上MongoDB,也不是每个系统都适合使用MongoDB,比如你的系统需要很强的事务控制,但MongoDB只有一些有限的原子操作能力,不支持事务。
- 使用Like进行搜索,这在数据不太大的时候,也能凑活。
- 建立单独的查询数据库或表。为了提升查询效率,专门为查询创建一些表,这些表的结构按照搜索最方便的方式设计,这样将查询与操作分离开来。这样做的问题是比较麻烦,另外导致复杂度上升,但它能够兼顾操作的简便性和查询性能,所以也不失为一种解决方法。使用这种方法需要将数据保存两份,在同一事务中采用同步更新可能导致更新上的性能损失。如果采用异步方式更新,虽然性能提升,又可能导致更新延时,造成界面显示异常等问题。
- 转成实体。如果上面的方法,你觉得都不好,可能转成实体更简单方便。
在《实现领域驱动设计》一书中,提供了另一种设计方案,它采用实体的表设计方式,然后在值对象的层超类型中隐藏标识,这样在代码中感觉它还是一个值对象,同时又可查询。不过我个人不是太喜欢这个方案,我如果创建了单独的表,可能使用实体更方便。
使用值对象的另一个挑战来自表现层界面。
值对象的一个关键设计是支持不变性,这意味着值对象的每个属性都没有setter,或者setter只在对象内部允许访问,这对我们有什么影响呢?
现在你的表现层正在使用Mvc或Wpf,它们都支持模型绑定。当你在Mvc表单界面进行输入之后,提交到控制器操作,你可以在控制器操作上使用一个实体来接收参数。想像一下,你现在需要把员工地址传递到控制器操作,但由于Address是不可变的,从而导致模型绑定失败。
为了解决这个问题,使用值对象的必备条件是创建一个配套的可变值对象,对于Address,你可以给这个可变值对象取名为AddressViewModel,或者AddressDto都行,我一般叫它AddressInfo。这个对象的所有属性都有setter,并且是public的,这样才可以在表现层使用,然后它会转换成值对象,供领域层使用。
从以上可以看出,虽然说考虑领域模型时,不要考虑数据库和界面,但最终这两个大环境对设计决策是可能造成影响的。
使用值对象的建议
- 聚合中尽量使用值对象。值对象与实体在很多时候可能是可互换的,由于值对象可以简化系统,所以当它的缺点可以克服就应该坚决采用。
- 值对象必须设计成不可变,并且值对象的任何方法都不能修改属性值。如果值对象的方法需要进行修改,可以通过该方法返回一个该值对象的新实例。如果对象是可变的,应该建模为实体,而不是值对象。
- 如果需要跟踪对象的生命周期,或者在聚合外部,需要进行标识引用,应该采用实体,而不是值对象。
最后,总结一下
值对象(Value Object)
- 不需要唯一标识
- 只关心“是什么”,不关心“是哪一个”
- 只要所有属性相同则认为是同一个值对象
- 我们把整个值对象看成一个不可变的整体,不能修改值对象的属性,但是可以整个替换掉
- 因为值对象的不变性,所以可以被共享
- 值对象应该设计的尽量保持简单
值对象例子
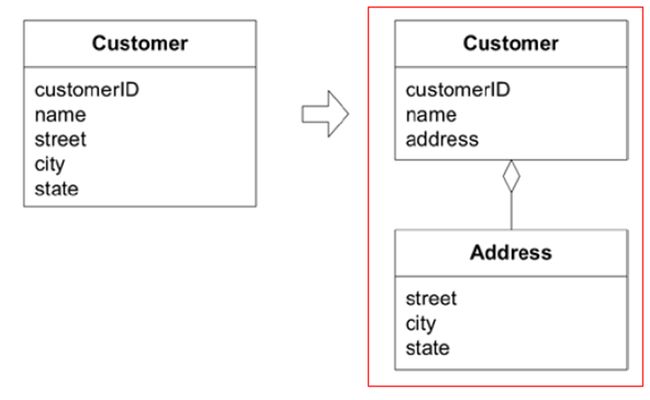
你排斥值对象的主要原因:
- 长期以来,我们使用数据库所造成的思维定势影响。
- 序列化大对象,造成查询不便。
- 不可变值对象在界面上无法绑定,需要额外创建配套的可变值对象,让你觉得工作量变大。
- 代码生成器无法直接创建值对象,需要将生成出来的代码手工调整,你不想这么麻烦。
值对象为你提供的主要价值:
- 更简单,更清晰的表达简单业务概念。
- 帮助你优化系统性能。
- 帮助你简化系统设计,特别是持久化方面。
值对象的设计要点:
- 值对象必须不可变。
- 值对象的任何方法都不能直接修改属性值,可以通过该方法返回一个新实例。
- 使用Object建模值对象,而不是Struct。
- 当值对象是单个时,优先使用嵌入值模式映射。
在EF中通过ComplexTypeConfiguration配置映射。 - 当值对象是集合,或者值对象的内部层次关系很复杂时,优先使用序列化大对象模式映射。
- 嵌入值模式映射列名可以遵循一定命名规则,比如Employee_Address_City。
- 序列化大对象时,优先使用Json格式保存。
- 为每个值对象创建一个配套的可变值对象,以方便界面使用。
实体与值对象的区别:
- 实体拥有标识,而值对象没有。
- 相等性测试方式不同。实体根据标识判等,而值对象根据内部所有属性值判等。
- 实体允许变化,值对象不允许变化。
- 持久化的映射方式不同。实体采用单表继承、类表继承和具体表继承来映射类层次结构,而值对象使用嵌入值或序列化大对象方式映射。