算法上机报告1——渗透问题(Percolation)
算法上机报告1——渗透问题(Percolation)
目录
算法上机报告1——渗透问题(Percolation)
一、实验简介
二、实验目的
三、实验环境
四、实验内容(含源代码)
五、实验感想
一、实验简介
本实验要求学生能够综合运用排序、搜索、图处理和字符串处理的基础算法和数据结构,
将算法理论、算法工程和编程实践相结合开发相应的软件,解决科学、工程和应用环境下的
实际问题。使学生能充分运用并掌握算法设计与分析的方法以及算法工程技术,为从事计算
机工程和软件开发等相关工作打下坚实的基础。
二、实验目的
通过本课程的学习使学生系统掌握算法设计与分析的基本概念和基本原理,理解排序、
搜索、图处理和字符串处理的算法设计理论及性能分析方法,掌握排序、搜索、图处理和字符串处理的数据结构与算法实现技术。课程强调算法的开发及 Java 实现,理解相应算法的性能特征,评估算法在应用程序中的潜在性能。
三、实验环境
- 安装Windows操作系统的计算机
- Java的IDE——eclipse
- 安装 Java 编程环境。 引入stdlib.jar and algs4.jar。前者包含库:从标准输入读数据、向标准输出写数据,以及向标准绘制绘出结果,产生随机数、计算统计量以及计时程序;后者包含了教科书中的所有算法。
四、实验内容
1.问题重述
在一个著名的科学问题中,研究人员对以下问题感兴趣:如果将格点以概率 p 独立地设置为 open 格点(因此以概率 1-p 被设置为 blocked 格点),系统渗透的概率是多少? 当 p = 0 时,系统不会渗出; 当 p=1 时,系统渗透。
使用合并-查找(union-find)数据结构,编写程序通过蒙特卡罗模拟(Monte Carlo simulation)来估计渗透阈值。
下图显示了 20×20 随机网格(左)和 100×100 随机网格(右)的格点空置概率 p 与渗滤概率。此概率可以检测算法的准确性和结果的精确度。
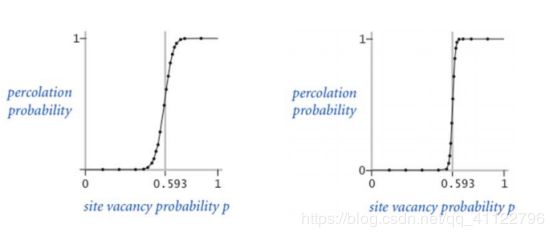
由此知,先验条件给出的待求概率p为0.593。
2.问题求解
对于渗透问题,可以使用教材中给出的union-find算法。
Union-find算法的API如下所示

其中重要的操作就是find操作——找到p所在连通分量的标识符,以及union操作——在p、q之间添加一条连接。
下面的表列出了各种算法的性能特点
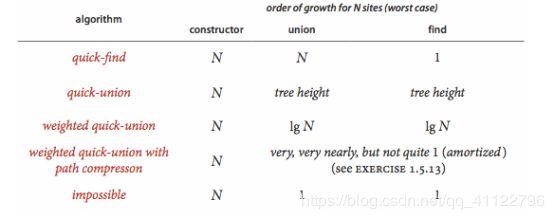
其中加权的quick-union算法能够有效的控制树高,性能较优,可以解决大型问题,我采用了加权的quick-union算法来实现本次实验内容。
3.实验结果
方阵大小200*200,运行次数100,结果为

也可测试小规模问题,测试可以对内部渗透结构有直观的了解

其中数字代表连通分量所在树的根节点,-1表示没有被渗透,被框柱的部分是存在着一条渗透通路,说明此时的p可以使模型发生渗透。
4源代码
package uf;
import java.util.Scanner;
import java.util.Random;
public class UF {
private int[][] id;//区块数组
//private int p;//打开概率
private int[][] sz;//各个根节点对应分量的大小
private int count;//连通分量
private int num;
public int flag;
private double p0;
public UF(int N)
{//初始化分量id数组
count = 0;
flag=0;
num=N;
id = new int[N][N];//-1表示阻塞,大于0时表示它的根节点
sz = new int[N][N];//各个分量的大小
p0=0.1;
}
private void random_id(double p)
{
int i,j;
Random ran=new Random();
for(i=0;i { for(j=0;j { if(ran.nextDouble()<=p) { id[i][j]=i*num+j;//根节点的根是自己 count++; } else id[i][j]=-1; sz[i][j]=1; //System.out.println( i +" "+ j); } } } public int count() {//返回连通分量数量 return count; } public boolean connected(int p,int q) {//查看是否已经连接 return (find(p) == find(q))&&getid(p)>=0; } public int find (int p) {//找到p所属连通分量 if(getid(p)==-1) return -1; while(p!=getid(p)&&getid(p)!=-1) p=getid(p);//根节点的根是自己 return p; } public int getid(int p) { return id[p/num][p%num]; } public int getsz(int p) { return sz[p/num][p%num]; } //--------------------加权的quick-union算法--------------- public void union(int p,int q) {//把p、q归并到相同的连通分量中(归并到同一根节点) int proot=find(p); int qroot=find(q); if (proot==qroot) return;//在同一连通分量则返回 //将小树的根节点连接到大树根节点 if (getsz(proot) { id[proot/num][proot%num]=qroot; sz[qroot/num][qroot%num]+=sz[proot/num][proot%num]; } else { id[qroot/num][qroot%num]=proot; sz[proot/num][proot%num]+=sz[qroot/num][qroot%num]; } count--; //System.out.println("count "+count); } public void check(int i,int j) { int p=i*num+j; if(id[i][j]<0) return; if(j+1 { union(p,p+1); } if(i+1 { union(p,p+num); } if(j-1>0&&id[i][j-1]>0) union(p,p-1); if(i-1>0&&id[i-1][j]>0) union(p,p-num); return; } public double open(double p) { int n=num; random_id(p); int i=0,j=0; for(i=0;i { for(j=0;j { check(i,j); } } for(i=0;i { for(j=0;j { if(connected(i,n*(n-1)+j)) { //System.out.println("这个概率可以连通,p="+p); flag=1; } } } //System.out.println("p为:"+p); if(flag==1) //System.out.println("这个概率可以连通"); return p; else return open(p+(double)(1.0/num)); } //public public void print() { //System.out.println("概率为:"+p0); int i,j; for(i=0;i { for(j=0;j { System.out.print(find(i*num+j)+"\t"); } System.out.println(); } System.out.println(); } public static void main(String[] args) { // TODO Auto-generated method stub long start_time=System.nanoTime(); Scanner scan = new Scanner(System.in); System.out.println("请输入方阵大小、循环次数"); int N =scan.nextInt();//读取触点数量 int loop=scan.nextInt();//读取循环次数 scan.close(); int i; double [] sum=new double[loop]; double mean=0; UF[] uf = new UF[loop];//初始化N个分量 for(i=0;i { uf[i]=new UF(N); double s=uf[i].open(0.5); mean+=s; sum[i]=s; uf[i].print(); } mean=mean/loop; System.out.println("平均值为:"+mean); double std=0; for(i=0;i { std+=(sum[i]-mean)*(sum[i]-mean)/loop; //System.out.println("第i个发生渗透的概率值为:"+sum[i]); } long consumingtime=System.nanoTime()-start_time; double up = mean+1.96*std/Math.sqrt(loop); double down = mean-1.96*std/Math.sqrt(loop); System.out.println("方差为:"+std); System.out.println("运行时间为:"+consumingtime/1000000+"毫秒"); System.out.println("95%的置信区间为:("+down+","+up+")"); } } 并查集寻找连通分量的思想非常简洁有效,并且还能够大幅度提高算法性能,从quick-find算法开始,每一个小的改动都能带来性能上的提高,最后的路径压缩算法成本更是接近了常数,这非常吸引人,算法设计确实是非常有意思的智力活动。 五、实验感想