neo4j︱Cypher完整案例csv导入、关系联通、高级查询(三)
图数据库常规的有:neo4j(支持超多语言)、JanusGraph/Titan(分布式)、Orientdb,google也开源了图数据库Cayley(Go语言构成)、PostgreSQL存储RDF格式数据。
—- 目前的几篇相关:—–
neo4j︱图数据库基本概念、操作罗列与整理(一)
neo4j︱Cypher 查询语言简单案例(二)
neo4j︱Cypher完整案例csv导入、关系联通、高级查询(三)
第三篇,一个比较完整的csv导入,并进行查询的案例,涉及的数据量较大,更贴合实际场景。
NorthWind Introduction
案例解析,官网:https://neo4j.com/developer/guide-importing-data-and-etl/
Github地址:https://github.com/neo4j-contrib/developer-resources
如果要全部一次性运行的话,可以键入命令:
bin/neo4j-shell -path northwind.db -file import_csv.cypher
本文是官方的一个比较完整的案例,包括三部分:csv载入、建立实体关联、查询
其中csv载入与建立实体关联可以了解到如何为Neo4j的数据集;
cypher的查询也有难易之分,该案例中较好得进行了使用,有初级查询与高级查询。
该数据集 NorthWind dataset 可以在github之中找到:neo4j-contrib/developer-resources
整个数据结构如图:

很复杂是吧…来理一下逻辑:
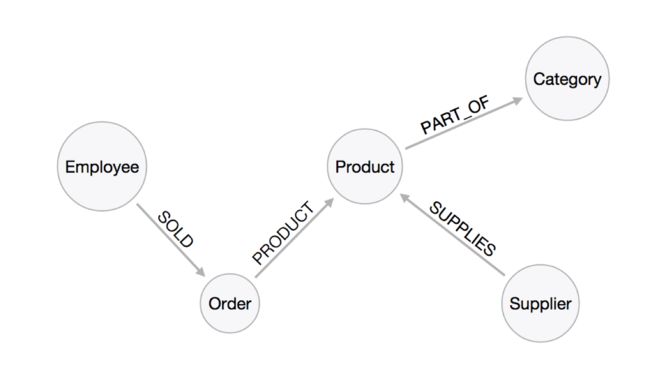
一、载入基本实体信息
保证数据格式
因为neo4j是utf-8的,而CSV默认保存是ANSI的,需要用记事本另存为成UTF-8的。
// Create customers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///customers.csv" AS row
CREATE (:Customer {companyName: row.CompanyName, customerID: row.CustomerID, fax: row.Fax, phone: row.Phone});
// Create products
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///products.csv" AS row
CREATE (:Product {productName: row.ProductName, productID: row.ProductID, unitPrice: toFloat(row.UnitPrice)});
// Create suppliers
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///suppliers.csv" AS row
CREATE (:Supplier {companyName: row.CompanyName, supplierID: row.SupplierID});
// Create employees
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///employees.csv" AS row
CREATE (:Employee {employeeID:row.EmployeeID, firstName: row.FirstName, lastName: row.LastName, title: row.Title});
// Create categories
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///categories.csv" AS row
CREATE (:Category {categoryID: row.CategoryID, categoryName: row.CategoryName, description: row.Description});
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS row
MERGE (order:Order {orderID: row.OrderID}) ON CREATE SET order.shipName = row.ShipName;
注意:
执行两次会重复加载,注意!
“file:///customers.csv”中的’///’请注意!
CREATE (:Product {productName: row.ProductName)})其中:
Product为图ID,可以通过Match (customers) return customers进行查看;row.ProductName的用法,跟dataframe差不多;- 类似dict,其中的
productName为Key
其中有一个比较奇怪的表格,那就是最后一个:orders.csv
为了查询更快,可以建立索引:
CREATE INDEX ON :Product(productID);
CREATE INDEX ON :Product(productName);
CREATE INDEX ON :Category(categoryID);
CREATE INDEX ON :Employee(employeeID);
CREATE INDEX ON :Supplier(supplierID);
CREATE INDEX ON :Customer(customerID);
CREATE INDEX ON :Customer(customerName);
给每个节点比较重要的ID字段建立索引。
不能同时执行,不然会报错:
Neo.ClientError.Statement.SyntaxError
同时添加一个约束:
CREATE CONSTRAINT ON (o:Order) ASSERT o.orderID IS UNIQUE;
同时,如果需要修改其中一部分内容,可参考下面案例:
如果Janet is now reporting to Steven那么久可以如以下方式进行修改:
MATCH (mgr:Employee {EmployeeID:5})
MATCH (emp:Employee {EmployeeID:3})-[rel:REPORTS_TO]->()
DELETE rel
CREATE (emp)-[:REPORTS_TO]->(mgr)
RETURN *;
定位到emp,把有关联的都先删掉DELETE,然后create新的关联。
延伸一:csv载入的两种方式(参考:3.3.20. LOAD CSV)
同时csv载入的方式有两种:本地载入+在线文档载入:
在线载入:
LOAD CSV FROM 'https://neo4j.com/docs/developer-manual/3.3/csv/artists.csv' AS line
CREATE (:Artist { name: line[1], year: toInteger(line[2])})本地载入中有个Bug,就是怎么写地址,难道要这么写?file:///C:\Users\mattzheng\Desktop\categories.csv,显然是不对的。
那么本地的话,需要把内容放到固定的文件夹之中,一个叫import文件夹之中。
有可能在:在XXX\Neo4j\graph.db\import文件夹内
也有可能在其他东西,笔者当时的文件夹路径藏得很深是:C:\Users\matt\.Neo4jDesktop\neo4jDatabases\database-b82284eb-23ab-4a42-8a83-f13af055ecf0\installation-3.3.4\import
笔者也是误打误撞找到了这个链接,是通过报错提醒得到的:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///C:\\Desktop\\categories.csv" AS row
CREATE (:Customer {companyName: row.CompanyName, customerID: row.CustomerID, fax: row.Fax, phone: row.Phone});然后他会报错:
Couldn't load the external resource at: file:/C:\Users\matt\.Neo4jDesktop\neo4jDatabases\database-b82284eb-23ab-4a42-8a83-f13af055ecf0\installation-3.3.4\import\categories.csv.
.
二、建立关联
2.1 order与 products/employees关联
order与 products and employees的关联:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (product:Product {productID: row.ProductID})
MERGE (order)-[pu:PRODUCT]->(product)
ON CREATE SET pu.unitPrice = toFloat(row.UnitPrice), pu.quantity = toFloat(row.Quantity);
//同时,创立新的关联属性,on create的作用
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (employee:Employee {employeeID: row.EmployeeID})
MERGE (employee)-[:SOLD]->(order);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///orders.csv" AS row
MATCH (order:Order {orderID: row.OrderID})
MATCH (customer:Customer {customerID: row.CustomerID})
MERGE (customer)-[:PURCHASED]->(order);
toFloat(row.UnitPrice)当数据中为数值型,则需要规定关系类型。
文本型可以不用规定具体的类似是啥。
MATCH (order:Order {orderID: row.OrderID})的意思为将图名称Order赋值为order,同时选中orderID=row.OrderID这些内容;
[pu:PRODUCT]中,pu代表关系的统称;PRODUCT代表关系的名称
2.2 products,suppliers,categories关联
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (supplier:Supplier {supplierID: row.SupplierID})
MERGE (supplier)-[:SUPPLIES]->(product);
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///products.csv" AS row
MATCH (product:Product {productID: row.ProductID})
MATCH (category:Category {categoryID: row.CategoryID})
MERGE (product)-[:PART_OF]->(category);
2.3 employees之间的关联
在employees构建 ‘REPORTS_TO’关系来表达上下级关系。
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///employees.csv" AS row
MATCH (employee:Employee {employeeID: row.EmployeeID})
MATCH (manager:Employee {employeeID: row.ReportsTo})
MERGE (employee)-[:REPORTS_TO]->(manager);
那么最终就会生成如下的内容:
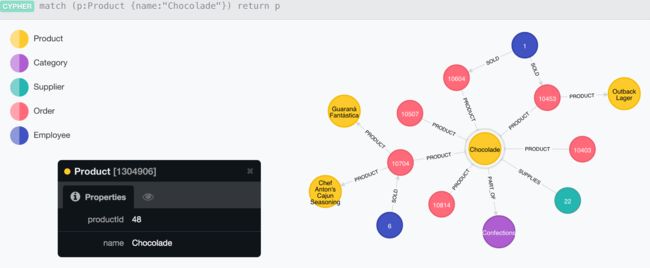
三、初级查询
来源于:From SQL to Cypher – A hands-on Guide
官方原文中还有跟sql的对比,比较了解sql的可以看原文。
查询一:单独查询两个关联表
MATCH (:Order)<-[:SOLD]-(e:Employee)
return *
查询二: product的价格,并排序:
match (p:Product)
return p.productName,p.unitPrice order by p.unitPrice DESC
limit 10;
逻辑:先从图数据库中定位p;order by 表示排序;limit 表 显示限制。
查询三:product 中’Chocolade’产品价格并排序:where、排序order使用
# 写法一:
match (p:Product)
where p.productName = 'Chocolade'
return p.productName,p.unitPrice order by p.unitPrice DESC limit 10;
# 写法二:
match (p:Product {productName : 'Chocolade'})
return p.productName,p.unitPrice order by p.unitPrice DESC limit 10;
写法一通过where来进行定位,写法二通过在match变量时,定义产品来进行产品定位。
查询四:product 中’Chocolade’以及’Chai’产品价格并排序:where、排序order使用
match (p:Product)
where p.productName IN ['Chocolade','Chai']
return p.productName,p.unitPrice order by p.unitPrice DESC limit 10;
查询五:条件筛选:where使用
MATCH (p:Product)
WHERE p.productName STARTS WITH "C" AND p.unitPrice > 100
RETURN p.productName, p.unitPrice;
意义为:选择p.productName中,首字母为’C’,同时unitPrice的价格大于100的范围内。
Indexing的使用
如果要加速某一列属性的查询,可以设置Index
CREATE INDEX ON :Product(productName);
CREATE INDEX ON :Product(unitPrice);
查询六:买了’Chocolade’的人有谁? :join用法
这边涉及四个表格:
- Product产品表,productID;
- Customer顾客表 CustomerID;
- orders索引表,orderID + CustomerID
orders_Details索引表,orderID + productID
//正确:
MATCH (p:Product {productName:”Chocolade”})<-[:PRODUCT]-(:Order)<-[:PURCHASED]-(c:Customer)
RETURN distinct c.companyName;
//错误
//match后面,跟的是主表,主表不带关系[],此时主表为Product
MATCH (c:Customer)-[:PURCHASED]
RETURN distinct c.companyName
//思考用法:用optional match之后为什么错误?
match (c:Customer)
where (p:Product {productName:”Chocolade”})<-[:Product]-(:Order)<-[:PURCHASED]-(c)
return distinct c.companyName
这里笔者的思考是,为什么Product是主表,需要遵循逻辑关系,逻辑关系是Customer表->order表->Product表,而不是Product表反向。
思考用法:此时命令返回的是全部的c.companyName,而不是买了巧克力的,optional match也是一个根据关系生成变量步骤,不是添加约束的步骤;此时也不能用where,where后面跟的对变量的约束,而不能嫁接关系
查询七:我买了啥+买了几件?:统计功能
‘Drachenblut Delikatessen’买了啥,买了几件东西。
客户和订单之间的匹配成为可选匹配,这与外连接相当。
//写法1+普通match写法
MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c:Customer {companyName:"Drachenblut Delikatessen"})
RETURN p.productName, toInt(sum(pu.unitPrice * pu.quantity)) AS volume
ORDER BY volume DESC;
//写法2+OPTIONAL MATCH
MATCH (c:Customer {companyName:"Drachenblut Delikatessen"})
OPTIONAL MATCH (p:Product)<-[pu:PRODUCT]-(:Order)<-[:PURCHASED]-(c)
RETURN p.productName, toInt(sum(pu.unitPrice * pu.quantity)) AS volume
ORDER BY volume DESC ;
OPTIONAL MATCH在我看来更多的还是赋值操作,而且可以在match写不下的时候,补充。
写法二,match先定义变量,然后在OPTIONAL MATCH后面补充连接关系。
其中:toInt()整数、sum()求和;AS volume生成新一列列名为’volumne’
查询八:雇员ID计数
MATCH (:Order)<-[:SOLD]-(e:Employee)
RETURN e.employeeID,count(*) AS cnt ORDER BY cnt DESC LIMIT 10
按照e.employeeID,进行分类count(*)计数。
| e.employeeID | cnt |
|---|---|
| “4” | 156 |
| “3” | 127 |
| “1” | 123 |
查询九:内容返回list/array格式
MATCH (o:Order)<-[:SOLD]-(e:Employee)
RETURN collect(e.lastName)
collect 将内容聚合成 (list,array)
.
四、高级查询
查询复杂度较大。来源于:Tutorial: Import Data Into Neo4j
查询一:Which Employee had the Highest Cross-Selling Count of ‘Chocolade’ and Which Product?
查询语句为:
MATCH (choc:Product {productName:'Chocolade'})<-[:PRODUCT]-(:Order)<-[:SOLD]-(employee),
(employee)-[:SOLD]->(o2)-[:PRODUCT]->(other:Product)
RETURN employee.employeeID, other.productName, count(distinct o2) as count
ORDER BY count DESC
LIMIT 5;
[:PRODUCT]-(:Order)代表的是:[]代表着关系名称;()代表着图名称;
第一条逻辑:(employee)-(:Order)-(choc:Product),定位到employee生产了叫Chocolade的product
第二条逻辑:(employee)-()-(other:Product),定位到的雇员生产了哪些其他Product(所有的)
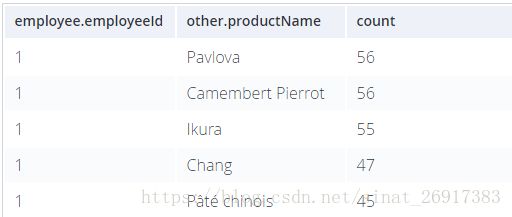
查询二:How are Employees Organized? Who Reports to Whom?
MATCH path = (e:Employee)<-[:REPORTS_TO]-(sub)
RETURN e.employeeID AS manager, sub.employeeID AS employee;
一个简单的模式,寻找Employee关系中REPORTS_TO的Employee。此时e代表雇主,sub代表雇员。
请注意,5号员工有人向他报告,但他也向2号员工报告。
这里有一个逻辑是:雇员、雇主都在Employee库中,所以要以REPORTS_TO关系为切入点。

查询三:Which Employees Report to Each Other Indirectly?
比查询二更深入一些,间接的。
MATCH path = (e:Employee)<-[:REPORTS_TO*]-(sub)
WITH e, sub, [person in NODES(path) | person.employeeID][1..-1] AS path
RETURN e.employeeID AS manager, sub.employeeID AS employee, CASE WHEN LENGTH(path) = 0 THEN "Direct Report" ELSE path END AS via
ORDER BY LENGTH(path);
第一步跟查询二的逻辑一样,在同一个Employee库汇总,查找关系为:REPORTS_TO的employee.
第二步,with用法,with从句可以连接多个查询的结果,即将上一个查询的结果用作下一个查询的开始,
(哈哈哈… 后面有点不明白,查完资料再补充…)

查询四:How Many Orders were Made by Each Part of the Hierarchy?
MATCH (e:Employee)
OPTIONAL MATCH (e)<-[:REPORTS_TO*0..]-(sub)-[:SOLD]->(order)
RETURN e.employeeID, [x IN COLLECT(DISTINCT sub.employeeID) WHERE x <> e.employeeID] AS reports, COUNT(distinct order) AS totalOrders
ORDER BY totalOrders DESC;
