CAE开发日志(6):cae_pdf2html设计
1、pdf2htmlEX介绍
一般发布的call表的文件类型是pdf,但是为了配合移动端的显示需求,需要将这些pdf文件转换成html文件,然后在移动端展示出来(目前只有安卓端所以就是用webview),为了实现pdf文件转换html文件,CAE引入了pdf2htmlEX的第三方软件来实现。
pdf2htmlEX是一个专门用来转换pdf到html的软件,它的使用方法也比较简单,只需要在命令行进入安装目录,然后输入“pdf2html
但是单纯通过命令行使用pdf2htmlEX有一个很大的弊端,那就是一次只能转换一个pdf,它没有提供批量操作的功能,如果一个一个pdf地转换就要编写多次命令,这样既费时费力,也不够优雅。因此,现考虑通过使用java来调用命令行的方式来实现批量操作,其实就是读取一个文件夹下的所有pdf文件,然后一个循环调用pdf2htmlEX即可完成。
但是单纯地循环调用还有一个问题需要解决,问题是出于pdf2htmlEX的单次转换运行时间,转换一个pdf其实是需要比较久的时间的,大概会有几秒,一旦转换的call表文件多起来的话,每个pdf都需要几秒,那么总共加起来的时间就比较长了。pdf2htmlEX的单次转换运行时间是取决于pdf2htmlEX内核的算法的,这个目前还无法优化,且难度较大,所以可以将其看作不可优化项,所以优化点就在于java调用pdf2htmlEX的方式。为了充分利用机器资源,现考虑使用线程池来并发调用pdf2htmlEX来提高性能。
2、cae_pdf2html总体设计
在第1节最后的结论的基础上,我再对使用线程池调用pdf2htmlEX的代码进行了再一次的封装,最终形成了一个类似于框架一样的程序,目前命名为cae_pdf2html。cae_pdf2html的总体架构如下:
下面是cae_pdf2html各个部分的设计介绍。
3、proxy
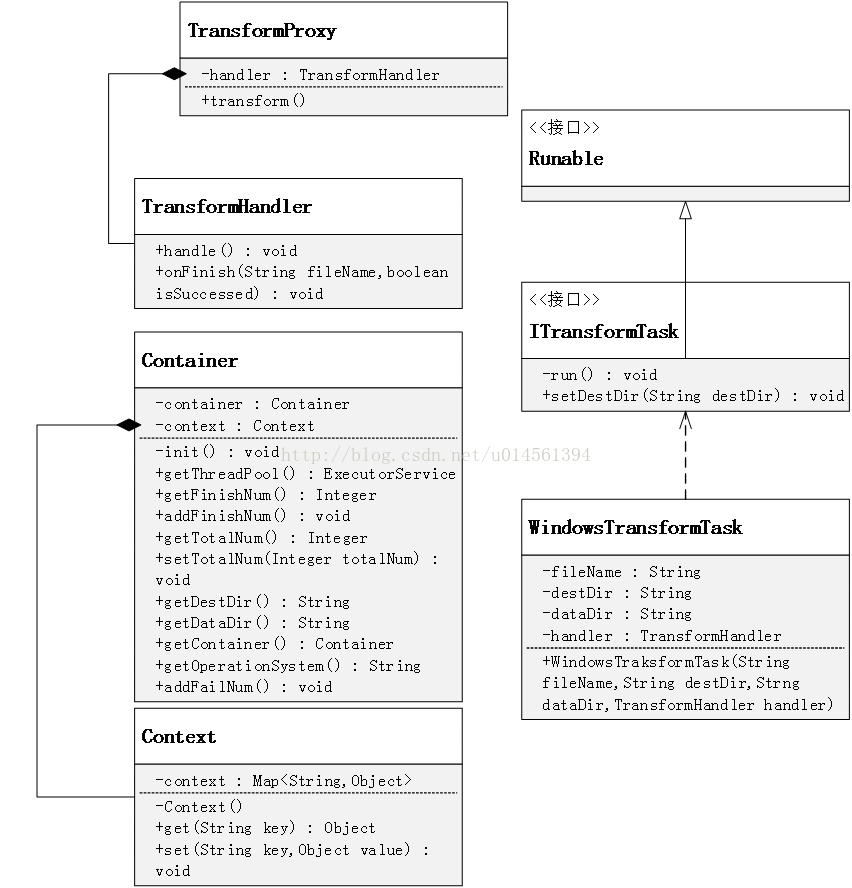
TransformProxy是专门面向客户端的一个类,客户端只需要配置好pdf文件夹的路径,然后直接调用TransformProxy.transform()方法即可开始转换。但实际上TransformProxy会把所有用户请求都委托为底层的TransformHandler来完成。使用TransformProxy的原因是希望能够对客户端屏蔽TransformHandler以及cae_pdf2html底层的一些对象和方法的存在,其实我也不清楚这是属于代理模式还是外观模式了,可能因为没有实现共同的接口,所以有点四不像的样子,但是只要能达到需求就好。
4、handler
TransformHandler才是真正的进行pdf转换的地方,接收到proxy的请求后,TransformHandler会从上下文对象Context中获取线程池并创建一个task,交给线程池去执行。它同时还要对全局进行判断,例如是否所有pdf已经转换完毕,并做出对应的逻辑。
onFinish()方法是用来给task回调用的,关于task的回调在之后再做详细分析。
5、task
task定义的是一个pdf转换任务,它本质上就是一个runnable,调用命令行就是在这里。不过这里还要考虑更多,例如不同操作系统上调用pdf2htmlEX的方式都是不一样的,所以在handler创建task的时候需要根据操作系统的不同创建不同的task,目前cae_pdf2html仅支持windows的调用,但是以后可能会增加linux甚至更多操作系统的task。
另外创建task的工作会交给一个叫TransformTaskFactory的工厂类去处理,TransformTaskFactory会从Context中读取当前的操作系统并根据当前的操作系统创建不同类型的task并返回。
6、关于task的回调
handler是整个cae_pdf2html的主线程,它的线程池创建了多个子线程,每个子线程就是一个task,这里需要主线程感知到子线程的状态(因为要统计转换是否全部成功、是否全部完成等)。那么主线程应该如何感知到子线程的状态呢?我所知道的有四种:
1、同步阻塞。就是不使用线程池,完全使用单线程去完成,就是一开始说到的循环调用,主线程做完了,就意味着整个转换任务都完成了,但是这种性能太差,CPU利用率低,且不符合现在的设计,所以放弃。
2、同步非阻塞。使用线程池,然后对于每个task都一个while(true)来询问是否已经完成,如果完成则+1,全部完成则调出while(true),虽然比同步阻塞的CPU利用率好了一点,但是还是太弱了,而且不优雅,暂且放弃。
3、Future模式。java提供了Future模式来解决这个问题,只要把task变为Callable即可具备返回某个值的功能,task完成后,返回值会自动注入到Future对象中,这时候只需要判断Future对象是否为空即可感知到子线程是否完成。但是这个方法本质上还是同步非阻塞,个人感觉只是代码更加优雅了,但本质并没有改变。
4、异步非阻塞。以上三种其实都是主线程主动去询问子线程的方案,但是“何时完成”应该是子线程自身最清楚,那么为什么不让子线程在完成任务后主动通知主线程呢?那么这种方法就是回调了,当然,回调的本质就是异步非阻塞。目前cae_pdf2html就是用这种方式去解决的。为了让子线程能够主动通知主线程“任务已经完成”,这里是通过调用handler的onFinish()方法来实现通信的,为了能够调用handler的onFinish()方法,可以看到在task的构造方法参数中有handler,这样task在完成转换任务后就可以调用自己内部的handler引用来实现“通知主线程”的功能了。
但是,回调这种方式本身也有缺点,如果子线程过多、而且任务几乎都是同时完成时,它们就会对主线程也就是handler造成激烈的竞争,因为这里是需要统计完成任务数,所以需要一个int值来统计,这里就会产生线程安全问题,目前为了解决这个问题完成数的变量是使用AtomicInteger来统计的,但即使如此也还会有竞争的风险,不过这里的并发线程数不多,而且cae_pdf2html本质上是客户端应用,所以这个问题不会太严重,所以暂不考虑这个问题。
7、context/container
Context是上下文对象,它存放了所有cae_pdf2html在运行时会用到的全局变量或对象,例如前面说到的线程池、任务完成数、操作系统等。
Container是容器对象,本质上就是一个Map,而Context则是对它的一些get和set操作,所以Context和Container中定义了大量的常量字符串变量,这些都是Container的Map的键。
8、线程池的选择
java的线程池是ThreadPoolExecutor对象,一般可以通过Executors来创建一些常用的线程池对象,Executors可创建四种线程池对象:
1、fixed,固定线程数的线程池
2、cached,无上限线程数的线程池
3、single,只有一条线程的线程池
4、scheduled,可以周期性执行任务的线程池
cae_pdf2html目前支持fixed、cached、single三种线程池,默认是选择fixed类型线程池,线程数是计算当前机器的CPU核数的数量。不推荐使用cached,因为cached会无节制地在一开始创建非常多的线程,如果有30个pdf文件就开30个线程,而30个task并发运行会导致机器的CPU使用率过高、内存100%甚至溢出的情况。线程池的种类可以在配置文件中进行配置。
9、配置文件
cae_pdf2html还支持用户自定义的配置文件,引入cae_pdf2html的jar包后,可以在src下创建“p2h.properties”文件,这个文件就是cae_pdf2html的配置文件,目前配置文件中可以对pdf文件夹的路径(输入路径)、html文件夹的路径(输出路径)、线程池种类、线程池线程数(fixed才会用到)进行自定义配置,cae_pdf2html在启动时会识别到这个配置文件并根据配置信息进行context的初始化工作。
如果没有发现p2h.properties文件,cae_pdf2html内部还有一个自带的默认的配置文件default_p2h.properties,这是cae_pdf2html使用的默认配置。
10、不足之处
一个最大的不足之处就是pdf2htmlEX如果一起打包进cae_pdf2html的jar包的话task是无法识别并调用到它的,所以客户端需要使用cae_pdf2html的话,除了要引入cae_pdf2html的jar包外,还需要自己引入pdf2htmlEX。