Spark2.1.0——存储体系概述
本书在5.7节曾介绍过存储体系的创建,那时只为帮助读者了解SparkEnv,现在是时候对Spark的存储体系进行详细的分析了。简单来讲,Spark存储体系是各个Driver、Executor实例中的BlockManager所组成的。但是从一个整体出发,把各个节点的BlockManager看成存储体系的一部分,那么存储体系还有更多衍生内容,比如块传输服务、map任务输出跟踪器、Shuffle管理器等。
存储体系架构
在正式介绍存储体系的内容之前,如果能对存储体系从整体上有个宏观的认识,无疑有利于读者对后续内容的理解。图1能够从整体上表示存储体系架构。
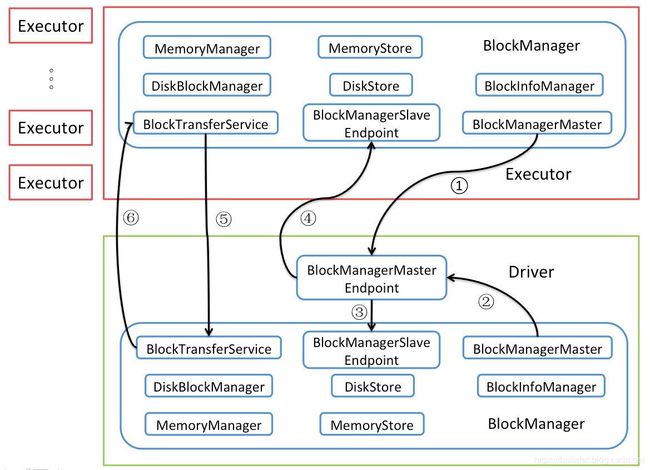 图1 存储体系架构
图1 存储体系架构
从图1,我们可以看到BlockManager依托于很多组件的服务,这些组件包括:
- BlockManagerMaster:代理BlockManager与Driver上的BlockManagerMasterEndpoint通信。图1中的记号①表示Executor节点上的BlockManager通过BlockManagerMaster与BlockManagerMasterEndpoint进行通信,记号②表示Driver节点上的BlockManager通过BlockManagerMaster与BlockManagerMasterEndpoint进行通信。这些通信的内容有很多,例如注册BlockManager、更新Block信息、获取Block的位置(即Block所在的BlockManager)、删除Executor等。BlockManagerMaster之所以能够和BlockManagerMasterEndpoint通信,是因为它持有了BlockManagerMasterEndpoint的RpcEndpointRef。
- BlockManagerMasterEndpoint:由Driver上的SparkEnv负责创建和注册到Driver的RpcEnv中。BlockManagerMasterEndpoint只存在于Driver的SparkEnv中,Driver或Executor上的BlockManagerMaster的driverEndpoint属性将持有BlockManagerMasterEndpoint的RpcEndpointRef。BlockManagerMasterEndpoint主要对各个节点上的BlockManager、BlockManager与Executor的映射关系以及Block位置信息(即Block所在的BlockManager)等进行管理。
- BlockManagerSlaveEndpoint:每个Executor或Driver的SparkEnv中都有属于自己的BlockManagerSlaveEndpoint,分别由各自的SparkEnv负责创建和注册到各自的RpcEnv中。Driver或Executor都存在各自的BlockManagerSlaveEndpoint,并由各自BlockManager的slaveEndpoint属性持有各自BlockManagerSlaveEndpoint的RpcEndpointRef。BlockManagerSlaveEndpoint将接收BlockManagerMasterEndpoint下发的命令。图1中的记号③表示BlockManagerMasterEndpoint向Driver节点上的BlockManagerSlaveEndpoint下发命令,记号④表示BlockManagerMasterEndpoint向Executor节点上的BlockManagerSlaveEndpoint下发命令。这些下发命令有很多,例如删除Block、获取Block状态、获取匹配的BlockId等。
- SerializerManager:序列化管理器。SerializerManager 的内容已在《Spark内核设计的艺术》一书的5.4节详细分析过,此处不再赘述。
- MemoryManager:内存管理器。负责对单个节点上内存的分配与回收。
- MapOutputTracker:map任务输出跟踪器。其实现与工作原理已在《Spark内核设计的艺术》一书的5.6节详细介绍过。
- ShuffleManager:Shuffle管理器。由于Shuffle与计算的关系更为紧密,所以留在《Spark内核设计的艺术》一书的第8章详细介绍。
- BlockTransferService:块传输服务。此组件也与Shuffle相关联,主要用于不同阶段的任务之间的Block数据的传输与读写。例如:map任务所在节点的BlockTransferService给 Shuffle对应的reduce任务提供下载map中间输出结果的服务。
- shuffleClient:Shuffle的客户端。与BlockTransferService配合使用。图1中的记号⑤表示Executor上的shuffleClient通过Driver上的BlockTransferService提供的服务上传和下载Block,记号⑥表示表示Driver上的shuffleClient通过Executor上的BlockTransferService提供的服务上传和下载Block。此外,不同Executor节点上的BlockTransferService和shuffleClient之间也可以互相上传、下载Block。
- SecurityManager:安全管理器。具体实现已在《Spark内核设计的艺术》一书的5.2节介绍。
- DiskBlockManager:磁盘块管理器。对磁盘上的文件及目录的读写操作进行管理。
- BlockInfoManager:块信息管理器。负责对Block的元数据以及锁资源进行管理。
- MemoryStore:内存存储。依赖于MemoryManager,负责对Block的内存存储。
- DiskStore:磁盘存储。依赖于DiskBlockManager,负责对Block的磁盘存储。
小贴士:在Spark 1.x.x版本中还提供了TachyonStore,TachyonStore负责向Tachyon中存储数据。Tachyon也诞生于UCBerkeley的AMP实验室,是以内存为中心的高容错的分布式文件系统,能够为内存计算框架(比如Spark、MapReduce等)提供可靠的内存级的文件共享服务。从软件栈的层次来看,Tachyon是位于现有大数据计算框架和大数据存储系统之间的独立的一层。它利用底层文件系统作为备份,对于上层应用来说,Tachyon就是一个分布式文件系统。自Spark 2.0.0版本开始,TachyonStore已经被移除。Tachyon发展到1.0.0版本时改名为Alluxio。更多Alluxio的信息,请访问http://www.alluxio.org。
基本概念
存储体系中有一些概念,需要详细说明。正所谓“磨刀不误砍柴工”,有了对这些概念的理解,后面的内容理解起来会更加容易。
BlockManager的唯一标识BlockManagerId
根据之前的了解,我们知道在Driver或者Executor中有任务执行的环境SparkEnv。每个SparkEnv中都有BlockManager,这些BlockManager位于不同的节点和实例上。BlockManager之间需要通过RpcEnv、shuffleClient以及BlockTransferService相互通信,所以大家需要互相认识,正如每个人都有身份证号一样,每个 BlockManager都有其在Spark集群内的唯一标识。BlockManagerId就是BlockManager的身份证。
Spark通过BlockManagerId中的host、port、executorId等信息来区分BlockManager。BlockManagerId中的属性包括:
- host_:主机域名或IP。
- port_:此端口实际使用了BlockManager中的BlockTransferService对外服务的端口。
- executorId_:当前BlockManager所在的实例的ID。如果实例是Driver,那么ID为driver,否则由Master负责给各个Executor分配,ID格式为:app-日期格式字符串-数字。
- topologyInfo_:拓扑信息。
理解了BlockManagerId中的属性,来看看它提供的方法:
- executorId:返回executorId_的值。
- hostPort:返回host:port格式的字符串。
- host:返回host_的值。
- port:返回port_的值。
- topologyInfo:返回topologyInfo_的值。
- isDriver:当前BlockManager所在的实例是否是Driver。此方法实际根据executorId_的值是否是driver来判断。
- writeExternal:将BlockManagerId的所有信息序列化后写到外部二进制流中。writeExternal的实现见代码清单1。
代码清单1 writeExternal的实现
override def writeExternal(out: ObjectOutput): Unit = Utils.tryOrIOException {
out.writeUTF(executorId_)
out.writeUTF(host_)
out.writeInt(port_)
out.writeBoolean(topologyInfo_.isDefined)
// we only write topologyInfo if we have it
topologyInfo.foreach(out.writeUTF(_))
}
- readExternal:从外部二进制流中读取BlockManagerId的所有信息。readExternal的实现见代码清单2。
代码清单2 readExternal的实现
override def readExternal(in: ObjectInput): Unit = Utils.tryOrIOException {
executorId_ = in.readUTF()
host_ = in.readUTF()
port_ = in.readInt()
val isTopologyInfoAvailable = in.readBoolean()
topologyInfo_ = if (isTopologyInfoAvailable) Option(in.readUTF()) else None
}
块的唯一标识BlockId
了解操作系统存储的读者,应该知道文件系统的文件在存储到磁盘上时,都是以块为单位写入的。操作系统的块都是以固定的大小读写的,例如512字节、1024字节、2048字节、4096字节等。
在Spark的存储体系中,数据的读写也是以块为单位,只不过这个块并非操作系统的块,而是设计用于Spark存储体系的块。每个Block都有唯一的标识,Spark把这个标识抽象为BlockId。抽象类BlockId的定义见代码清单3。
代码清单3 BlockId的定义
@DeveloperApi
sealed abstract class BlockId {
def name: String
def asRDDId: Option[RDDBlockId] = if (isRDD) Some(asInstanceOf[RDDBlockId]) else None
def isRDD: Boolean = isInstanceOf[RDDBlockId]
def isShuffle: Boolean = isInstanceOf[ShuffleBlockId]
def isBroadcast: Boolean = isInstanceOf[BroadcastBlockId]
override def toString: String = name
override def hashCode: Int = name.hashCode
override def equals(other: Any): Boolean = other match {
case o: BlockId => getClass == o.getClass && name.equals(o.name)
case _ => false
}
}
根据代码清单3,BlockId中定义了以下方法:
- name:Block全局唯一的标识名。
- isRDD:当前BlockId是否是RDDBlockId。
- asRDDId:将当前BlockId转换为RDDBlockId。如果当前BlockId是RDDBlockId,则转换为RDDBlockId,否则返回None。
- isShuffle:当前BlockId是否是ShuffleBlockId。
- isBroadcast:当前BlockId是否是BroadcastBlockId。
BlockId有很多子类,例如:RDDBlockId、ShuffleBlockId、BroadcastBlockId等。BroadcastBlockId曾在《Spark内核设计的艺术》一书的5.5节介绍广播管理器BroadcastManager时介绍过, BlockId的子类都是用相似的方式实现的。
存储级别StorageLevel
前文提到Spark的存储体系包括磁盘存储与内存存储。Spark将内存又分为堆外内存和堆内存。有些数据块本身支持序列化及反序列化,有些数据块还支持备份与复制。Spark存储体系将以上这些数据块的不同特性,抽象为存储级别(StorageLevel)。
分析StorageLevel,也是从其成员属性开始。StorageLevel中的成员属性如下:
- _useDisk:能否写入磁盘。当Block的StorageLevel中的_useDisk为true时,存储体系将允许Block写入磁盘。
- _useMemory:能否写入堆内存。当Block的StorageLevel中的_useMemory为true时,存储体系将允许Block写入堆内存。
- _useOffHeap:能否写入堆外内存。当Block的StorageLevel中的_useOffHeap为true时,存储体系将允许Block写入堆外内存。
- _deserialized:是否需要对Block反序列化。当Block本身经过了序列化后,Block的StorageLevel中的_deserialized将被设置为true,即可以对Block进行反序列化。
- _replication:Block的复制份数。Block的StorageLevel中的_replication默认等于1,可以在构造Block的 StorageLevel时明确指定_replication的数量。当_replication大于1时,Block除了在本地的存储体系中写入一份,还会复制到其他不同节点的存储体系中写入,达到复制备份的目的。
有了对StorageLevel中属性的了解,现在来看看StorageLevel提供了哪些方法?
- useDisk:能否写入磁盘。实际直接返回了_useDisk的值。
- useMemory:能否写入堆内存。实际直接返回了_useMemory的值。
- useOffHeap:能否写入堆外内存。实际直接返回了_useOffHeap的值。
- deserialized:是否需要对Block反序列化。实际直接返回了_deserialized的值。
- replication:复制份数。实际直接返回了_replication的值。
- memoryMode:内存模式。如果useOffHeap 为true,则返回枚举值MemoryMode.OFF_HEAP,否则返回枚举值MemoryMode.ON_HEAP。
- clone:对当前StorageLevel进行克隆,并返回克隆的StorageLevel。
- isValid:当前的StorageLevel是否有效。判断的条件为:
(useMemory || useDisk) && (replication > 0)- toInt:将当前StorageLevel转换为整形表示。toInt的实现见代码清单4。
代码清单4 toInt的实现
def toInt: Int = {
var ret = 0
if (_useDisk) {
ret |= 8
}
if (_useMemory) {
ret |= 4
}
if (_useOffHeap) {
ret |= 2
}
if (_deserialized) {
ret |= 1
}
ret
}
根据代码清单4,toInt方法实际是把StorageLevel的_useDisk、_useMemory、_useOffHeap、_deserialized这4个属性设置到四位数字的各个状态位。例如,1000表示存储级别为允许写入磁盘;1100表示存储级别为允许写入磁盘和堆内存;1111表示存储级别为允许写入磁盘、堆内存及堆外内存,并且需要反序列化。
- writeExternal:将StorageLevel首先通过toInt方法将_useDisk、_useMemory、_useOffHeap、_deserialized四个属性设置到四位数的状态位,然后与_replication一起被序列化写入外部二进制流。writeExternal的实现见代码清单5。
代码清单5 writeExternal的实现
override def writeExternal(out: ObjectOutput): Unit = Utils.tryOrIOException {
out.writeByte(toInt)
out.writeByte(_replication)
}
- readExternal:从外部二进制流中读取StorageLevel的各个属性。readExternal的实现见代码清单6。
代码清单6 readExternal的实现
override def readExternal(in: ObjectInput): Unit = Utils.tryOrIOException {
val flags = in.readByte()
_useDisk = (flags & 8) != 0
_useMemory = (flags & 4) != 0
_useOffHeap = (flags & 2) != 0
_deserialized = (flags & 1) != 0
_replication = in.readByte()
}
了解了StorageLevel原生类提供的这些方法,我们再来看看StorageLevel的伴生对象。由于StorageLevel的构造器是私有的,所以StorageLevel的伴生对象中已经预先定义了很多存储体系需要的StorageLevel,见代码清单7。
代码清单7 内置的StorageLevel
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
代码清单7所示的代码调用StorageLevel的构造器创建了多种存储级别。StorageLevel私有构造器的参数从左至右分别为_useDisk、_useMemory、_useOffHeap、_deserialized、_replication。
块信息BlockInfo
BlockInfo用于描述块的元数据信息,包括存储级别、Block类型、大小、锁信息等。按照惯例,我们先看看BlockInfo的成员属性:
- level:BlockInfo所描述的Block的存储级别,即StorageLevel。
- classTag:BlockInfo所描述的Block的类型。
- tellMaster:BlockInfo所描述的Block是否需要告知Master。
- _size:BlockInfo所描述的Block的大小。
- _readerCount:BlockInfo所描述的Block被锁定读取的次数。
- _writerTask:任务尝试在对Block进行写操作前,首先必须获得对应BlockInfo的写锁。_writerTask用于保存任务尝试的ID(每个任务在实际执行时,会多次尝试,每次尝试都会分配一个ID)。
有了对BlockInfo的了解,现在看看BlockInfo提供的方法:
- size与size_:对_size的读、写。
- readerCount与readerCount_:对_readerCount的读、写。
- writerTask与writerTask_:对_writerTask的读、写。
BlockResult
BlockResult用于封装从本地的BlockManager中获取的Block数据以及与Block相关联的度量数据。BlockResult中有以下属性:
- data:Block及与Block相关联的度量数据。
- readMethod:读取Block的方法。readMethod采用枚举类型DataReadMethod提供的Memory、Disk、Hadoop、Network四个枚举值。
- bytes:读取的Block的字节长度。
BlockStatus
样例类BlockStatus用于封装Block的状态信息,包括:
- storageLevel:即Block的StorageLevel。
- memSize:Block占用的内存大小。
- diskSize:Block占用的磁盘大小。
- isCached:是否存储到存储体系中,即memSize与diskSize的大小之和是否大于0。