内部排序(七)桶排序与次位优先基数排序
排序算法算是学了一大半了- -、,在弄基数排序时了解到,前面所学的那些(选择、插入、希尔…堆排,快排)排序算法都是要通过比较序列元素之间的关系然后做移动这两步操作。的确,排序嘛,序列从无序到有序一定是比较元素之间的关系然后调整成正确的对应位置。不过基数排序不同,基数排序不需要进行元素之间的比较,而是借助“分配”和“收集”两个操作完成排序的。分配和收集具体是怎么样?我们通过桶排序来说明。没错是桶排序- -,讲基数排序前,先来讲讲桶排序,不是标题党不是标题党不是标题党!因为基数排序是桶排序的一种推广,所以通过桶排序来讲讲基数排序中用到的“分配”和“收集”两个操作。
桶排序是这样的,举个例子,假设我们要对学生的某一科成绩进行排序,一个班上有N个学生,成绩分数值为0分到100分之间。桶排序就是为这0到100分一共101种情况,建立101个对应的桶。

Bucket是一个链表的数组,也就是数组里面每一个元素对应一个空链表,所以每一个桶就是一个链表。
然后开始排序:假设第一个学生考了98分,然后就把98插入到Bucket数组中下标为98的桶里(也就是链表里)。

接下来的操作就是一直读出学生成绩,把它放到相应的桶中,最后从小到大收集所有的桶中元素即可。
//桶排序
void Bucket_Sort(PtrlSqlList P, int N)
{
int i;
//初始化一个桶
ListBucket B=InitialListBucket();
//待排序列放入桶中
for (i=0; iP[P->arr[i]], P->arr[i]);
}
//输出整个桶里的所有链表
PrintBucket(B);
return;
} 所以程序也比较简单,这里就不展开说太多,主要是第162行把元素插入桶时,插入到对应下标的Bucket数组中的桶里就ok了。桶排序时间复杂度为O(N+M),假设上面的例子,有N个学生,一个有M种成绩情况,对所有的学生成绩做排序时,要把所有N个学生的都遍历一遍,复杂度是N,最后收集所有的M个桶,也就是遍历一遍M个桶,时间复杂度是M,加起来就是O(N+M)。
不过桶排序有一个问题,就是假设我只有50个学生,但是我们要排序的是学生的所有科目总分,假设总分为750分,就是有751种情况,那么我们岂不是要建立751个桶?假设这50个同学的成绩都比较集中在某个分数段,这就太浪费空间了。
为了解决这种情况,就可以用基数排序。假设我们的N为10,有10个数,这10个数字每个数字最多由3位组成,也就是M大于等于0,小于1000。那么要对这10个数做排序,建立1000个桶明显是不划算的。用基数排序的话,我们只需建立10个桶就可以了,怎么做?
首先,基数排序中的基数,指的是进制数,二进制的进制数是2,八进制的进制数是8,我们这里的数据表示用十进制,所以进制数就是10。也就是说,这N=10个数中,虽然它们最多由3位组成,但每一位(个位、十位,百位)都只有十种情况(0到9)。所以我们利用这一点来建立桶,只建立0-9这十个桶。

假设我们要对这个序列做排序:
278、109、63、930、589、184、505、269、8、83。
这里先讲基数排序中的一种叫次位优先基数排序,比如上面的序列中第一个元素278,最低为个位8为次位,最高位百位2为主位。对上面的序列做排序,根据基数10建立好0-9十个桶后,第一躺排序首先把待排序列中每一个元素按照最低为个位开始排序,逐个放进相应的桶里,就是下面这种情况:
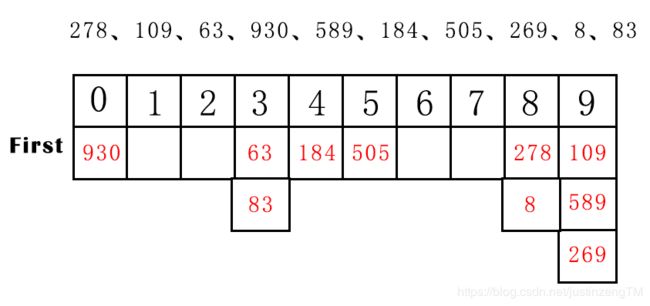
278次位是8放到8这个桶里,109次位是9放到9这个桶里…一直下去。一趟排序完成后,把桶里的元素按顺序收集起来,得到这样一个新的序列:
930、63、83、184、505、278、8、109、589、269。
因为序列中元素最高位有3位,所以排序还没完,第二趟排序继续从新序列开始,这次就是看十位了,因为个位已经排好序了,十位同样按照上面的方法放进相应的桶里,也就是下面这样:

第二趟排序后再按顺序把桶里的所有元素收集起来,得到一个新序列:
505、8、109、930、63、269、278、83、184、589。
看起来好像还是不怎么有序是吧?别急,还有最后一趟呢!最后一趟就剩最高位百位了,我们根据新序列按照百位插入到桶里,看看序列会变得怎么样:
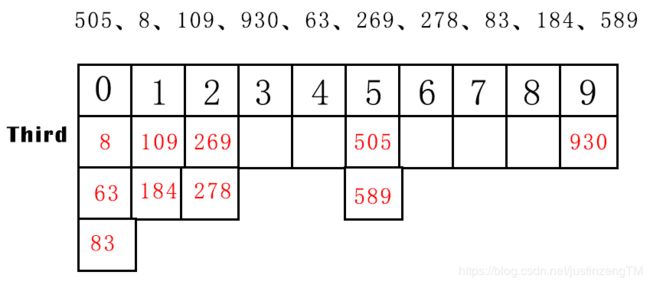
拍完序后,再收集起来看看,我们就得到一个有序序列了:
8、63、83、109、184、269、278、505、589、930。
次位优先基数排序时间复杂度也很好理解,总共N个数,插入时遍历一遍为N,收集一次也就是遍历一遍所有的桶,为 M,最后要做基数次,假设为P,所以时间复杂度就等于O(P(N+M))。桶的个数和基数也是有关的,桶的个数M等于logB(B为数据元素的取值范围一共有多少种)。
说了这么多,我们来看看程序怎么写:
//LSD次位优先基数排序
void Least_Significant_Digit_Sort(PtrlSqlList P, int N)
{
//基数排序 - 次位优先
int D, Di, i;
Bucket B; //建立一个桶的数组,也就是一堆桶
PtrlBucketNode tmp, p, q, List=NULL; //建立了三个桶,且初始化为NULL
//初始化每个桶为一个空链表
//数据最多有Radix位,所以需要Radix个桶
for (i=0; ikey=P->arr[i];
// tmp->Next=List;
// List=tmp;
// }
//将待排序列存入初始链表List中
tmp=InitialBucket(); //初始化一个桶元素结点
for (i=0; iarr[i], tmp);
}
List=tmp->Next;
// PtrlBucketNode a;
// printf("初始序列:");
// for (a=tmp->Next; a; a=a->Next) {
// printf("%d\t", a->key);
// }
//然后开始排序过程
for (D=1; D<=MaxDigit; D++) {
//对数据的每一位进行处理,这里设置数据最多有三位
p=List;
while (p) {
//D一开始从1开始,也就是一开始只看个位
//获得当前元素的当前位数字
Di=GetDigit(p->key, D);
tmp=p;
p=p->Next;
//对一个元素排完序后,把该元素从List链表中删除
tmp->Next=NULL;
//获得数位后,插入到B[Di]桶里
//特殊情况判断如果桶B[Di]的链表为空
if (B[Di].Head==NULL) {
B[Di].Head=B[Di].Tail=tmp;
} else {
B[Di].Tail->Next=tmp;
B[Di].Tail=tmp;
}
}
printf("第%d次次位优先基数排序\n", D);
for (i=0; i=0; Di--) {
if (B[Di].Head) {
//整个桶插入List表头
B[Di].Tail->Next=List; //最开始List==NULL
List=B[Di].Head;
//清空桶B[Di]
B[Di].Head=B[Di].Tail=NULL;
}
}
printf("收集桶:");
PrintBucketList(List);
printf("\n\n");
}
//做完所有排序后,将List放回用户的序列中并释放掉List
for (i=0; iNext;
P->arr[i]=tmp->key;
free(tmp);
}
} 定义三个变量用,Di是保存当前用来比较的位数字。第172行建立一个桶数组后,把里面的每一个桶都初始化,一共有基数个桶,每一个桶中的链表初始化为一个空链表。然后把用户的待排序列读进来用一个链表存储,第208行把用户的待排序列存进来做排序。(第200行注释中用逆序的方法把待排序列接进来,这样操作更快,代码少,但我不推荐这样用,因为把待排序列逆序后会把元素的相对位置改变了,所以第208行我选择了就正序链接进来,至于那些链接代码可以到本文末我的GitHub上看)。
接下来开始排序,一共做MaxDigit次,MaxDigit是元素数据的最多有多少位,外循环D从1开始也就是从第一位个位开始,到MaxDigit(MaxDigit等于3),也就是最多比较到百位,所以最外层一共做三次,也就是一共做3趟排序。第227行对List也就是待排序列每一个元素都进行取次位操作:
//获得位数字
int GetDigit(int K, int Digit)
{
//次位一开始为Down=1,主位为D<=MaxDigit.
int i, digit;
for (i=1; i<=Digit; i++) {
digit=K%Radix;
K/=Radix;
}
return digit;
} 取次位数代码就是把元素对基数取余,需要第几位的位数就对元素取余多少次。根据外循环第几次排序就把D传进来,对应Digit。
取得元素的数位后,先把它保存在临时结点tmp中,p指向下一位准备排序的元素,然后把tmp插入到相对应的桶中。While循环做完后,也就是待排序列List中的元素都插入到相应的桶中后,按顺序把所有桶中的元素收集回List链表中,做下一趟排序用。收集过程直接从最后一个桶就是下标为9的桶开始,List指向该桶的头结点,然后下标为8的桶尾结点指向List(此时也就是指向了下标为9的桶的头结点),List再指向下标为8的桶的头结点,一直链接下去,最终List会指向下标为0的桶的头结点。,完成链接。
(第276行)做完三趟排序后,把已排好序的序列List放回到用户的序列P中,然后释放掉List序列就可以了。

上面就是次位优先基数排序的过程和结果啦!呼~终于把次位优先基数排序讲完了,还有主位优先基数排序呢!下一篇日志再说~
桶排序和次位优先基数排序代码都在我的GitHub和代码云:
https://github.com/justinzengtm/Internal_Sort/blob/master/Least_Significant_Digit_First_Sort.c
https://gitee.com/justinzeng/codes/m6uihsp7bd4z291knfqtr52