PageRank算法和MapReduce框架
PageRank算法和MapReduce框架
- 摘要
- 引言
- 文献综述
- 研究方法
- PageRank算法
- 核心思想
- 随机浏览者假设
- 计算方法
- 收敛证明
- MapReduce框架
- 核心思想
- 矩阵运算
- 讨论
- 结论
摘要
对于一个特定的查询,搜索结果的排名取决于两方面的信息,第一个是关键字与网页的相关性,第二个是网页本身的质量,本文着重于第二点,也就是介绍一种被证明行之有效的评估网页质量的办法及其并行计算策略。
如今的全球搜索引擎巨头Google,最早的革命性发明是一款名为PageRank的算法,它是用来衡量网页本身的重要性的,核心思想并不复杂,发明人将互整个互联网想象成一张相互关联的有向图,如果图里的每个结点如果一个网页被其他很多网页链接,那么就说明该网页很重要,是受到普遍认可的,那么它的排名就要高。1
算法具体的实现方法涉及到图论和线性代数,为了更快地进行稀疏矩阵的运算,Google还专门开发了并行计算工具MapReduce,本文旨在先清晰地说明其中的技术细节。
引言
在上世纪末,互联网上的网页数量快速增多,传统的搜索引擎,例如AltaVista和Yahoo,疲于应付新的趋势,主要原因是他们的算法是根据关键词分类所收录网站的。2但是对于应对大规模的查询业务,很少有学术研究涉及到相关工程领域。Google的这项技术在1998年前后使得搜索引擎的结果在相关性方面取得了质的飞跃,具体表现在改善了网页的排序上,同时也完美地支持了高并发状态,从而一举超过Yahoo成为行业领头羊。
互联网发明最初是为了更高效地传递学术信息,在发展过程中,商业信息逐渐变成了主流内容,商业网站的占比从1993年的1.5%上升到1997年的超过60% 3,但是学术内容和商业网站之间存在着明显的差别,商业网站可以通过程序自动创建大量指向特定网站的链接,使自己的网站排名提高以谋求利润。所以Google在满足学术研究需求的同时,兼顾商业运营,以一种截然不同的方式对商业网站排名。Google这个项目的最终目的是要建立起一个覆盖全球互联网的网页索引大全。
文献综述
PageRank这方面的文章和工作主要由谢尔盖·布林和拉里·佩奇为代表的谷歌公司工程师完成,引用来介绍这个算法的文章大多也由他们亲自撰写。
不过在他们之前,已经有了一些开发文本链接结构系统的工作,Pitkow已经尝试用网页链接分析万维网的环境4,Spertus把拥有链接结构的系统用在了数据挖掘上5,此外还有人从不同的角度出发,也在对网页质量进行评估6。当时的搜索引擎巨头也是把链接结构当作重要指标来优化搜索结果,但是这些项目都是简单地以链接数目作为评判标准,忽略了不同网站的链接权重并不相等这一事实,后面会仔细介绍这点。
研究方法
PageRank算法
核心思想
我们可以假设现在所有的网页都是图上的节点,网页之间的链接是有向边,每个节点都有一定数量的入链接(inedges)和出链接(outedges),被链接数大的网页很大概率就是更加重要的网页。7
此外也要考虑到这样一种情况,某一个网页被连接数不多,但都是被比较重要的网页所链接,比如如下图所示有一个网页C,只有两个网页A和B链接了它,但是这个网页B相当重要,收到了1000个其他网页的链接在这里插入图片描述,那么网页A的重要性就不是单纯一个被链接数量能够描述的。下图展示一种最简单的文件链接情况:
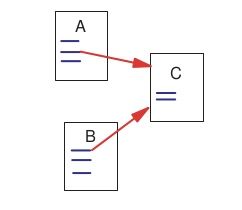
为了通过链接更加合理地度量网页的重要性从而解决这个问题,不同网页被赋予了不同的权重,换句话说,如果一个网页想要得到高的排名,那么链接它的网页排名也需要尽可能地高。
随机浏览者假设
首先我们假设有一个网页的浏览者,他随机点击网页上的一个链接,一直持续下去。但是有可能网页上的链接是循环往复的,所以按照假设,他会一直持续点击这些链接。事实上,并不会有人真的这样做,如果碰到循环的情况,真实世界的浏览者肯定会重新打开一个新的网页,而且每次用户不一定会一直点击到没有链接为止,每当打开一个新网页,浏览者的下一步行为都有可能是打开一个不被现在网页直接链接的随机网页8

为了在算法中模拟出在这个情况下的用户行为,我们需要一个 N N N维向量 E E E来存储随机浏览者转跳到不同网页的概率,其中的 N N N是收录的网页数量。一般来说,我们继续假定每个网页被点击的概率都是相等的,当然这是一个可以个性化的参数,而且直接影响到收敛速度。关于向量 E E E的进一步说明,我把它放在了第四部分。这小节假设的情况是为了给接下来介绍计算得分的方法作铺垫。
计算方法
假设网页A被n个网页所链接,这些网页分别记为 T 1 , T 2 , ⋯ , T n T_1,T_2,\cdots,T_n T1,T2,⋯,Tn,令 C ( T i ) C(T_i) C(Ti)表示网页 T i T_i Ti的出链接数量,接着我们还需要一个衰减系数 d ∈ ( 0 , 1 ) d \in (0,1) d∈(0,1),这是为了让每个网页在开始迭代的时候都有一定的保底分数。那么网页A的重要性得分可以按照以下的公式得出
P R ( A ) = ( 1 − d ) + d ( P R ( T 1 ) C ( T 1 ) + ⋯ + P R ( T n ) C ( T n ) ) PR(A) = (1-d) + d(\frac{PR(T_1)}{C(T_1)} + \cdots + \frac{PR(T_n)}{C(T_n)}) PR(A)=(1−d)+d(C(T1)PR(T1)+⋯+C(Tn)PR(Tn))
这里的 d d d一般取0.85。我们可以借助下图来直观的理解不同链接权重的含义。
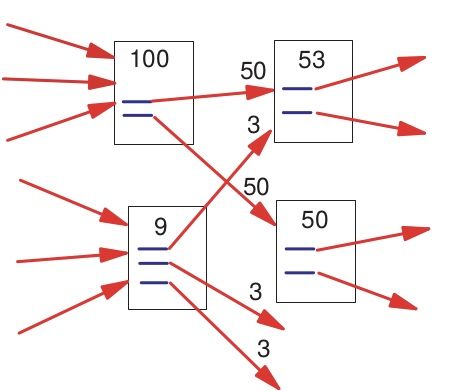
之后为了求出网页A的得分,我们要解决的问题是获取 T 1 , T 2 , ⋯ , T n T_1,T_2,\cdots,T_n T1,T2,⋯,Tn得分,这些网页又会有链接到它的其他网页。如果不存在循环链接的情况,那么从最底层的网页分数依次网上累加;如果存在如随机浏览者假设中循环链接的情况,那么就不存在最底层的网页,无法自底向上加出总分。为了解决这个问题,PageRank算法把问题转变成了一个二维矩阵相乘的问题,并用迭代的方法最终解决了它。
具体来看这个迭代的过程,首先我们把所有网页都给予从 1 1 1到 N N N的唯一编号,把它们的对应的最终得分记录在下面这个 N N N维向量中
B = [ b 1 , b 2 , ⋯ , b N ] T B=[b_1,b_2,\cdots,b_N]^T B=[b1,b2,⋯,bN]T
然后把链接结构用如下的矩阵
A = [ a 11 a 12 ⋯ a 1 N ⋮ ⋮ a m 1 a m 2 ⋯ a m N ⋮ ⋮ a N 1 a N 2 ⋯ a N N ] A= \begin{bmatrix} a_{11} & a_{12} & \cdots & a_{1N} \\ \vdots & & & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mN} \\ \vdots & & & \vdots \\ a_{N1} & a_{N2} & \cdots & a_{NN} \\ \end{bmatrix} A=⎣⎢⎢⎢⎢⎢⎢⎡a11⋮am1⋮aN1a12am2aN2⋯⋯⋯a1N⋮amN⋮aNN⎦⎥⎥⎥⎥⎥⎥⎤
记录下来,其中的 a m n a_{mn} amn表示第m个网页指向第n个网页的链接数,迭代起点设置为
B 0 = [ 1 N , 1 N , ⋯ , 1 N ] T B_0=[\frac{1}{N},\frac{1}{N},\cdots,\frac{1}{N}]^T B0=[N1,N1,⋯,N1]T
迭代公式设置为
B n + 1 = A B n + ( ∣ ∣ A B n ∣ ∣ 1 − ∣ ∣ B n ∣ ∣ 1 ) E B_{n+1}=AB_n+(||AB_n||_1-||B_n||_1)E Bn+1=ABn+(∣∣ABn∣∣1−∣∣Bn∣∣1)E
完整过程我用伪代码的形式给出

收敛证明
取 e e e为所有分量都为1的列向量,定义矩阵
M = α E + 1 − α N e e T M=\alpha E+\frac{1-\alpha}{N}ee^T M=αE+N1−αeeT
那么上述的迭代过程就是 B n = M B n − 1 B_n=MB_{n-1} Bn=MBn−1, 于是该问题就转为了一个Markov过程了。马尔科夫链的收敛条件如下9
- M为随机矩阵
- M是不可约的
- M是非周期的
以上条件均满足,所以pagerank是收敛的,且与初始值无关,即无论 B 0 B_0 B0取值如何,都不会影响最后各个网页的得分情况。
MapReduce框架
核心思想
从前面的算法可以看出,为了给新收录的网页评分,PageRank算法反复做大规模的矩阵运算,而且计算量每次都会增加,很紧迫的需求就是切分矩阵实现并行计算。针对挑战,Google给出的解决方案是一个叫做MapReduce的程序,它的核心设计思想是分治算法。10
将一个大任务拆分成若干个子任务,并且完成子任务的计算,这个过程叫做Map,将中间结果合并成最终要的结果,这个过程叫做Reduce。还有很多更加具体的问题需要考虑,比如平均分配负载,分布式存储数据,错误容忍。11
MapReduce框架给出的是一个并行计算的通用解决方案,文件首先要输入(input)程序,然后进行切分(split),把每一个片段分配(map)到不同的工作站(worker)中,计算的结果分布的存储在本地,之后由远端的工作站(worker)逐个读取结果并且重新排序(shuffle),最后一步才是合并(reduce)输出最终的文件。具体的过程见下图

此外还有一个需要强调的部分是,过程中还会产生一个主工作站(master worker),这个和其他工作站等级是一样的,只不过会做一些特殊事情,它会作为用户的代理来协调整个过程,用户就可以做其他事情。主工作站会让一个工作站去拿1号数据,另一个工作站负责拿2号数据等等,这就是分配数据的过程。抽象地说,主工作站是将map任务产的中间数据位置传送到reduce任务的管道,所以主工作站保存了map任务完成后产生的若干中间文件的位置信息包含大小,当然,map任务结束的时候会更新位置和大小信息。这个信息会被逐步的推送到正在处理reduce任务的工作站。
矩阵运算
由于PageRank算法涉及到大规模矩阵并行计算,所以这里特别说明一下MapReduce在处理矩阵乘法上的应用。我们先讲理论抽象,假设我们有规模为 m × n m \times n m×n的矩阵 A A A和规模为 n × p n \times p n×p的矩阵 B B B,两者相乘得到矩阵 C C C.就以 a 11 a_{11} a11为例,它将会在 c 11 , c 12 , ⋯ , c 1 p c_{11},c_{12},\cdots,c_{1p} c11,c12,⋯,c1p的计算中使用。也就是说,在Map阶段,当我们从切分完毕的文件中取出一行记录时,如果该记录是 A A A的元素,则需要存储成 p p p个< k e y key key, v a l u e value value>对,并且这 p p p个 k e y key key互不相同;如果该记录是 B B B的元素,则需要存储成 m m m个< k e y key key, v a l u e value value>对,同样的, m m m个 k e y key key也应互不相同;但同时,用于存放计算 c i j c_{ij} cij的 a i 1 , a i 2 , ⋯ , a i n a_{i1},a_{i2},\cdots,a_{in} ai1,ai2,⋯,ain和 b 1 j 、 b 2 j , ⋯ , b n j b_{1j}、b_{2j},\cdots, b_{nj} b1j、b2j,⋯,bnj的< k e y key key, v a l u e value value>对的 k e y key key应该都是相同的,这样才能被传递到同一个Reduce中。举个例子,我们有规模为 3 × 2 3\times2 3×2的矩阵 A A A和规模为 2 × 4 2\times4 2×4的矩阵 B B B
C = A B = [ 5 3 10 2 1 1 ] × [ 3 0 7 11 9 2 6 8 ] C=AB= \begin{bmatrix} 5 & 3 \\ 10 & 2\\ 1 & 1\\ \end{bmatrix} \times \begin{bmatrix} 3 & 0 & 7 & 11\\ 9 & 2 & 6 & 8\\ \end{bmatrix} C=AB=⎣⎡5101321⎦⎤×[390276118]
在计算的时候,我们需要将矩阵 A A A转换成下面这张键值表
| key | value | key | value | key | value |
|---|---|---|---|---|---|
| 1,1 | a,1,5 | 2,1 | a,1,10 | 3,1 | a,1,1 |
| 1,1 | a,2,3 | 2,1 | a,2,2 | 3,1 | a,2,1 |
| 1,2 | a,1,5 | 2,2 | a,1,10 | 3,2 | a,1,1 |
| 1,2 | a,2,3 | 2,2 | a,2,2 | 3,2 | a,2,1 |
| 1,3 | a,1,5 | 2,3 | a,1,10 | 3,3 | a,1,1 |
| 1,3 | a,2,3 | 2,3 | a,2,2 | 3,3 | a,2,1 |
| 1,4 | a,1,5 | 2,4 | a,1,10 | 3,4 | a,1,1 |
| 1,4 | a,2,3 | 2,4 | a,2,2 | 3,4 | a,2,1 |
这里的key是指这个数据用来计算矩阵 C C C中哪个位置的值,比如第一行第一列这个位置对应 k e y = ( 1 , 1 ) key=(1,1) key=(1,1),计算过程涉及到矩阵 A A A中的两个值,所以上表中同样的 k e y key key也只对应两个 v a l u e value value。 v a l u e value value第一部分表示它属于哪个矩阵,第二部分表示它是原矩阵这一行/列第几个元素,只有对应的元素才能相乘,第三部分才是用来计算的数值,其余部分都是为了用来定位的。同样的办法可以得到矩阵 B B B的键值表,如下所示
| key | value | key | value | key | value |
|---|---|---|---|---|---|
| 1,1 | b,1,3 | 2,1 | b,1,3 | 3,1 | b,1,3 |
| 1,1 | b,2,9 | 2,1 | b,2,9 | 3,1 | b,2,9 |
| 1,2 | b,1,0 | 2,2 | b,1,0 | 3,2 | b,1,0 |
| 1,2 | b,2,2 | 2,2 | b,2,2 | 3,2 | b,2,2 |
| 1,3 | b,1,7 | 2,3 | b,1,7 | 3,3 | b,1,7 |
| 1,3 | b,2,6 | 2,3 | b,2,6 | 3,3 | b,2,6 |
| 1,4 | b,1,11 | 2,4 | b,1,11 | 3,4 | b,1,11 |
| 1,4 | b,2,8 | 2,4 | b,2,8 | 3,4 | b,2,8 |
后面重排(shuffle)这步将分布式存储的数据按照 k e y key key值进行归类
| key | value -A | value-B | key | value_A | value-B |
|---|---|---|---|---|---|
| 1,1 | a,1,5 | b,1,3 | 1,2 | a,1,5 | b,1,0 |
| 1,1 | a,2,3 | b,2,9 | 1,2 | a,2,3 | b,2,9 |
| 1,3 | a,1,5 | b,1,7 | 1,4 | a,1,5 | b,1,11 |
| 1,3 | a,2,3 | b,2,6 | 1,4 | a,2,3 | b,2,8 |
| 2,1 | a,1,10 | b,1,3 | 2,2 | a,1,10 | b,1,0 |
| 2,1 | a,2,2 | b,2,9 | 2,2 | a,2,2 | b,2,2 |
| 2,3 | a,1,10 | b,1,7 | 2,4 | a,1,10 | b,1,11 |
| 2,3 | a,2,2 | b,2,6 | 2,4 | a,2,2 | b,2,8 |
| 3,1 | a,1,1 | b,1,3 | 3,2 | a,1,1 | b,1,0 |
| 3,1 | a,2,1 | b,2,9 | 3,2 | a,2,1 | b,2,2 |
| 3,3 | a,1,1 | b,1,7 | 3,4 | a,1,1 | b,1,11 |
| 3,3 | a,2,1 | b,2,6 | 3,4 | a,2,1 | b,2,8 |
最后一步是归并(reduce),依次对每一个 k e y key key进行加总输出结果,比较简单直接,这里就不列表进行展示了。
讨论
PageRank算法为了解决循环链接的问题,我在随即浏览者假设里引入了一个描述转跳概率的矩阵 E E E,之前我们假设所有网页被转跳到的概率是一模一样的,实际上数值是被重新设置过的。在测试中发现,一些写有著作权,免责申明的网页被广泛链接,还有邮件服务器等没有实际内容的网页评分也很高。解决方案是只给各大网站的根目录给予一定的概率分布,另外对用户设置的家网页更高的概率。
结论
这篇文章可以分成前后两个部分。第一个部分描述了PageRank算法的工作原理,它的目的是给全球的网页重要性评分,从而作为搜索结果排序的一个重要依据。得分结果与网页的内容无关,只跟它在链接图中的位置有关,所以PageRank并不是搜索算法的全部,还需要与关键词检索算法TF-IDF相结合才能得到最终的排序。
第二个部分介绍了MapReduce框架,它以键值结构存储数据并且分配工作。所以在实际项目中,关键要找到一个合理的数据结构,能够支持分布式存储和计算。在矩阵计算的这个例子里,矩阵 A A A的第 i i i行用来生成 C C C中第 i i i行中的 p p p个元素,所以要花至少 p p p倍的空间存储,本质上也是拿空间换时间的做法。
The Anatomy of a Large-Scale Hypertextual Web Search Engine, Sergey Brin and Lawrence Page ↩︎
浪潮之巅,吴军 ↩︎
Web Growth Summary, Matthew Gray ↩︎
Characterizing World Wide Web Ecologies, James E. Pitkow ↩︎
Parasite: Mining structural information on the web, Ellen Spertus ↩︎
Evaluating quality on the net, Hope N. Tillman ↩︎
The PageRank Citation Ranking: Bringing Order to the Web, Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd ↩︎
PageRank and The Random Surfer Model, Prasad Chebolu and Páll Melsted ↩︎
关于为什么pagerank能收敛, https://blog.csdn.net/ustbfym/article/details/80219814 ↩︎
数学之美,吴军 ↩︎
MapReduce: Simplified Data Processing on Large Clusters, Jeffrey Dean and Sanjay Ghemawat ↩︎