创建自己的特征和转换器
创建新特征的数据
有时候,仅仅选择已有特征是不够的。我们需要在已有特征基础上创建新的特征。
一个效果好的新创建的特征,可以很有效的降低冗余信息,提高特征之间的相关性。对于算法准确率的提高有很好的促进作用。
接下来,加载一个新的数据集,从http://archive.ics.uci.edu/ml/datasets/Internet+Advertisements下载Advertisements(广告)数据集。保存到自己主目录下的Data文件夹中。下载ad.data和ad.names
接着,用pandas加载数据集。我们还是先指定文件的路径。
import os
import pandas as pd
import numpy as np
data_folder = os.path.join(os.path.expanduser("~"), "Data")
data_filename = os.path.join(data_folder, "Ads", "ad.data")数据集存在几个问题,加载过程需要我们做些处理。问题一,前几个特征是数值,但是pandas 会把它们当成字符串。要修复这个问题,我们需要编写将字符串转换为数字的函数,该函数能够 把只包含数字的字符串转换为数字,把其余的转化为“NaN” (“Not a Number”,不是一个数字), 表示参数值无法转换为数字。
问题二,数据集中有些值缺失,缺失的值用“?”表示。幸运的是,问号不会被转换为浮点型数据,因此,我们也可以把它们转换为“NaN”。
下面定义函数来解决这两个问题,首先使用try/except结构,捕获ValueError异常(字符串无法转换为数字时,抛出异常)。 如果转换失败,返回numpy库中的“NaN”类型。
def convert_number(x):
try:
return float(x)
except ValueError:
return np.nan创建一个字典存储所有特征及其转换结果,想把所有的特征值转换为浮点型。 把后一列(编号为#1558)的值转化为0或1,该列表示每条数据的类别。在Adult数据集中,我们专门创建了一列表示类别。对于当前实验,导入数据时,顺便把类别这一列各个类别值由字符串转换为数值。也就是对于是广告还是不是广告,我们希望用0和1来表示。1表示是广告,0表示不是广告。
from collections import defaultdict
converters = defaultdict(convert_number) #{i: convert_number for i in range(1558)}
converters[1558] = lambda x: 1 if x.strip() == "ad." else 0可以用read_csv加载数据集了,在参数中指定我们刚创建的转换函数。
数据集很大,有1559列,2000多条数据。先来看下前五条数据,在笔记本的新格子中输入并 运行ads[:5]。
ads = pd.read_csv(data_filename, header=None, converters=converters)
ads[:5]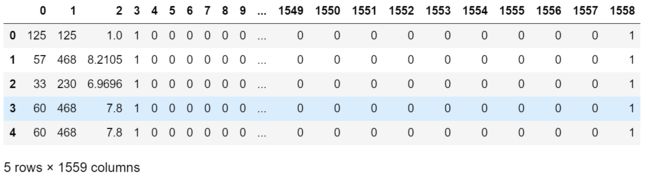
数据集所描述的是网上的图像,目标是确定图像是不是广告。
从数据集表头中无法获知每列数据的含义。你下载的另外两个文件ad.DOCUMENTATION和 ad.names有更多信息。前三 个特征分别指图像的高度、宽度和宽高比。后一列是数据的类别, 1表示是广告,0表示不是广告。
将数据集加载到pandas之后,我们再来抽取用于分类算法的x矩阵和y数组,x矩阵为数据框除去后一列的所有列,y数组包含数据框的后一列,也就是列编号为#1558的列。
#ads = ads.astype(float).dropna()
X = ads.drop(1558, axis=1).values
y = ads[1558]
print(X.shape)
print(y.shape)主成分分析
主成分分析算法(Principal Component Analysis,PCA)的目的是找到能用较少信息描述数据集的特征组合。它意在发现彼此之间没有相关性、能够描述数据集的特征,确切说这些特征的方差跟整体方差没有多大差距,这样的特征也被称为主成分。这也就意味着,借助这种方法,就能通过更少的特征捕获到数据集的大部分信息。
PCA跟其他转换器用法类似。它只有主成分数量这一个参数。它默认会返回数据集中的所有特征。然而,PCA会对返回结果根据方差大小进行排序,返回的第一个特征方差大,第二个特征方差稍小,以此类推。因此,前几个特征往往就能够解释数据集的大部分信息。
from sklearn.decomposition import PCA
pca = PCA(n_components=5)
Xd = pca.fit_transform(X)
Xd.shape输出:(2359, 5)
返回的结果Xd矩阵只有五个特征,但是不容小觑,我们看一下每个特征的方差。
np.set_printoptions(precision=3, suppress=True)
pca.explained_variance_ratio_输出结果为:
array([ 0.854, 0.145, 0.001, 0. , 0. ])
表明第一个特征的方差对数据集总 体方差的贡献率为85.4%。第二个为14.5%。第四个特征方差贡献率不可能高于1‰,后面1553个 特征则更少。
用PCA算法处理数据一个不好的地方在于,得到的主成分往往是其他几个特征的复杂组合, 例如,上述第一个特征就是通过为原始数据集的1558个特征(虽然很多特征值为0)分别乘以不 同权重得到的,前三个特征的权重依次为-0.092、-0.995和-0.024。经过某种组合得到的特征, 如果没有丰富的研究经验,理解起来很困难。
clf = DecisionTreeClassifier(random_state=14)
scores_reduced = cross_val_score(clf, Xd, y, scoring='accuracy')
print("The average score from the reduced dataset is {:.4f}".format(np.mean(scores_reduced)))输出为:The average score from the reduced dataset is 0.9356。
这是经过PCA处理之后计算出的准确率。
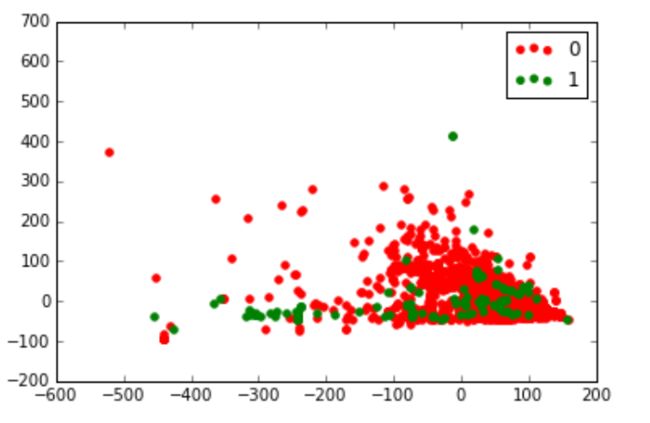
PCA算法的另一个优点是,你可以把抽象难懂的数据集绘制成图形。例如,把PCA返回的前 两个特征做成图形。
# 告诉IPython在当前笔记本作图
%matplotlib inline
from matplotlib import pyplot as plt
# 获取数据集中类别的所有取值(只有两个:是广告和不是广告)
classes = set(y)
colors = ['red', 'green']
# 用zip函数将这两个列表组合起来,同时遍历
for cur_class, color in zip(classes, colors):
# 为属于当前类别的所有个体创建遮罩层
mask = (y == cur_class).values
plt.scatter(Xd[mask,0], Xd[mask,1], marker='o', color=color, label=int(cur_class))
plt.legend()
plt.show()