基于MapReduce框架的PageRank算法实现
1.PageRank简述
PageRank算法将互联网看成一个有向图,而互联网中的每一个网页看成图中的一个顶点,将网页之间的链接看做图中的边。并且通过顶点之间的邻接关系计算每一个网页的权值,然后根据这个值的大小对网页的重要性进行排序。PageRank生成的Web网页排序是静态的,这是指每个网页的排序值是通过离线计算得到的,并且该值与用户的查询无关。在讨论讨论PageRank的公式之前,先阐述几个相关的主要概念:
网页i的入链(in-links):那些只想网页i的来自于其他网页的超链接,通常不包括同一站点内网页的超链接。
网页i的出链(out-links):那些从网页i指向其他网页的超链接,通常不包括镰刀同一站点内的网页超链接。
接下来我们阐述一些源于排序权值的思想,从而导出PageRank算法:
1)从一个网页指向另一个网页的超链接是一种权威性的隐式传输,这样一来,网页i的入链数越多就表示它得到的权值越高。
2)指向网页i的网页也有自己的权值分数。对于网页i来说,指向它的网页中,那些高权值的网页比低权值网页更重要。换句话说一个被其它重要网页指向的网页是重要的。
这里需要注意的是,一个网页可能会指向多个其它网页,**那么该网页的权值就应该被它指向的所有网页均分**。
2.PageRank模型
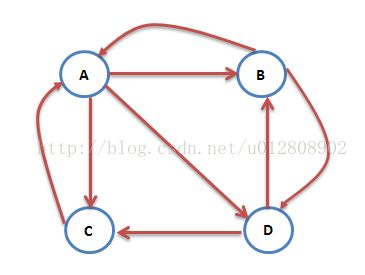

3.PageRank公式


4.PageRank实现
4.1 步骤
(1)得到初始的权值向量
统计待处理的源网页总数n,得出每个网页的初始权值 1/n 并输出到文件中,形成初始权值向量。
(2)PageRank主逻辑
此阶段将会一直迭代执行,直到最后权值向量收敛
Map阶段
输入:<源网页:所有链接网页网页>
输出:<链接网页:上一轮该链接网页的权值,链接网页的当前的部分权值>
1)将第一轮(或初始)的概率分布拿到并且缓存到maptask节点的工作目录,使每个maptask工作时都能拿到对应网页的权值。
2)通过所有网页的权值,计算被读取到的网页(源网页)所指向的所有网页(链接网页)的当前权值。
3)输出的时候为了方便reduce阶段的计算,将上一轮链接网页的权值作为键的一部分与链接网页地址一并输出
Redcue阶段
输入:<源网页:源网页的权值,链接网页的当前权值>
输出:<源网页,源网页的新权值>
1)map阶段发送过来的 “链接网页的当前权值”进行累加 得到当前源网页的一个“暂时的”新权值
2)因为有一些特殊情况,所以还要对此权值进行平滑处理V’ = aMV +(1-a)/n,处理后便得到最终的新权值。
3)在输出之前,要比较源网页的新权值与权值之间的差异,若其差异小于某阈值,则可视为其已经得到最终结果,自定义计数器Counter+1,当自定义计数器的值等于源网页的总数时迭代结束。
(3)对最终输出的文件进行排序处理
利用MapReduce二次排序的原理将最终收敛的权值向量文件进行排序。4.2 输入
A:B C D
B:A D
C:C
D:B C4.3 代码
//第一阶段首先统计网页总数n,并将初始的每个网页的权值设置为 1/n
/*
* 此时的map输出<"count",网站地址>,并且统计有源网页个数 将其赋值到counter中
*/
public class PageRankMapperInit extends Mapper{
//同一输出的键为count 这样只需在reduce阶段遍历一遍集合即可得到网页总数
Text k = new Text("count");
Text v = new Text();
Counter counter = null;
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
// 计数器+1,这个计数器在reduce阶段拿不到,只是给最后的控制迭代的main方法用
counter = context.getCounter("myCounter", "webNum");
counter.increment(1L);
String line = value.toString();
String webAddr = line.split(":")[0];
v.set(webAddr);
context.write(k, v);
}
}
/*
此时的reduce阶段统计总数n 并且将 map阶段传过来的“值”作为“键” 1/n作为“值” 输出
*/
public class PageRankReducerInit extends Reducer{
Text k = new Text();
DoubleWritable v = new DoubleWritable();
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
Long n = (long) 0;
List newValues = new ArrayList();
for(Text value : values){
newValues.add(value.toString());
n++;
}
for(String value : newValues){
k.set(value.toString());
v.set( 1.0/n);
context.write(k, v);
}
}
} (2)第二阶段:PageRank主逻辑
//第一阶段首先统计网页总数n,并将初始的每个网页的权值设置为 1/n
//输入文件中的每一行数据 即是M矩阵的每一列数据
/*
Map阶段的任务如下:
输入:<源网页:所有链接网页网页>
输出:<链接网页:上一轮该链接网页的权值,链接网页的当前的部分权值>
1)首先拿到缓存到的每个网页的权值数据,并将其放到map集合中
2)读取某个源网页链接到的所有网页数量 从而获得到源网页到每个链接网页的跳转概率,
3)再通过缓存数据得到源网页的权值 ,并将其参与计算 得出链接网页的部分权值 (其总权值需要reduce端合并)
*/
public class PageRankMapper extends
Mapper {
Map weightMap = new HashMap();
// 准备阶段将缓存进工作节点的概率分布表读出
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
//拿到缓存文件数组
URI[] uris = context.getCacheFiles();
//往缓存文件上兑一根输入流
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream(uris[0].getPath().toString())));
String line;
while (StringUtils.isNotEmpty(line = br.readLine())) {
String field[] = line.split("\t");
weightMap.put(field[0], field[1]);
}
br.close();
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] resource_links = line.split(":");
String resource = resource_links[0];
String[] links = resource_links[1].split("\t");
boolean containRes = false;//记录是否存在链接到源网页自身的链接
int linkNum = links.length; //源网页中所有链接网页的数量
double sourceWeight = Double.parseDouble(weightMap.get(resource)); //源网页权值
//在源网页之中的所有链接网页的“当前”权值都一样
double partLinkWeight = (1.0 / linkNum) * sourceWeight;
for (int i = 0; i < linkNum; i++) {
//当存在链接到源网页自身的链接时 布尔值改为true;
if (links[i].equals(resource))
containRes = true;
// 键为 链接网页 :上一轮链接网页的权值
//这样做的目的是为了新、老权值的变化,从而判断迭代是否完成
context.write(new Text(links[i] + ":" + weightMap.get(links[i])),
new DoubleWritable(partLinkWeight));
}
// 若网页的链接目标中没有本身,则输出<源网页地址,0.0> 以防丢失
if (!containRes)
context.write(
new Text(resource + ":"+ sourceWeight),
new DoubleWritable(0.0));
}
}
/*
Reduce阶段主要完成以下任务
输入:<源网页:源网页的权值,链接网页的当前权值>
输出:<源网页,源网页的新权值>
1) map阶段发送过来的 “链接网页的当前权值”进行累加 得到当前源网页的一个“暂时的”新权值
2) 因为有一些特殊情况,所以还要对此权值进行平滑处理(公式见上述说明),处理后便得到最终的新权值。
3)在输出之前,要比较源网页的新权值与权值之间的差异,若其差异小于某阈值,则可视为其已经得到最终结果,自定义计数器Counter+1,当自定义计数器的值等于源网页的总数时迭代结束。
*/
public class PageRankReducer extends Reducer{
Text k = new Text();
DoubleWritable v = new DoubleWritable();
Counter counter = null;
//判断该网站的新、老权值是不是小于阈值
public static boolean isChanged(double oldWeight, double newWeight){
if(Math.abs(oldWeight-newWeight) < 0.001)
return true;
return false;
}
@Override
protected void reduce(Text key, Iterable values,Context context)
throws IOException, InterruptedException {
double tempWeight = 0;
double oldWeight = Double.parseDouble(key.toString().split(":")[1]);
k.set(key.toString().split(":")[0]);
for(DoubleWritable value : values){
tempWeight += value.get();
}
//获得在configuration中保存的平滑因子以及源网页总数
double a = Double.parseDouble(context.getConfiguration().get("smooth"));
double e = 1.0/Integer.parseInt(context.getConfiguration().get("webNum"));
//按公式得出新权值
double newWeight = a*tempWeight + (1-a)*e;
boolean flag = isChanged(oldWeight,newWeight);
//若当前网页的新、老权值不变,则当前网页的权值收敛,counter+1
if(flag){
counter = context.getCounter("myCounter", "constringency");
counter.increment(1L);
}
v.set(newWeight);
context.write(k,v);
}
}
(3)第三阶段:对收敛的权值向量进行排序
public class PageRankMapperSort extends Mapper{
Text v = new Text();
DoubleWritable k = new DoubleWritable();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String webAddr_weight[] = line.split("\t");
v.set( webAddr_weight[0]);
//给权值取相反数,其目的是依权值的从大到小排序
k.set(-Double.parseDouble(webAddr_weight[1]));
context.write(k, v);
}
}
public class PageRankReducerSort extends Reducer{
Text k = new Text();
@Override
protected void reduce(DoubleWritable key, Iterable values,Context context)
throws IOException, InterruptedException {
for(Text value : values){
k.set(value.toString());
context.write(k, NullWritable.get());
}
}
}
(4)main方法提交
public class PageRank {
public static void main(String[] args)throws Exception {
String input = "H:/大数据/mapreduce/pagerank/input";
String output = "H:/大数据/mapreduce/pagerank/output";
//第一阶段
Configuration confInit = new Configuration();
Job jobInit = Job.getInstance(confInit);
jobInit.setJarByClass(PageRank.class);
jobInit.setMapperClass(PageRankMapperInit.class);
jobInit.setReducerClass(PageRankReducerInit.class);
jobInit.setMapOutputKeyClass(Text.class);
jobInit.setMapOutputValueClass(Text.class);
jobInit.setOutputKeyClass(Text.class);
jobInit.setOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(jobInit, new Path(input));
FileOutputFormat.setOutputPath(jobInit, new Path(output));
jobInit.waitForCompletion(true);
String weightPath = "file:/"+output+"/part-r-00000";
//拿到统计源网页个数的计数器 并源网页总数
Counter counterInit = jobInit.getCounters().getGroup("myCounter").findCounter("webNum");
Long webNum = counterInit.getValue();
//第二部分,迭代执行
int index = 0;
while(true){
Configuration conf = new Configuration();
conf.set("smooth", 0.8+""); //设置平滑因子
conf.set("webNum",webNum+"");//设置源网页总数
Job job = Job.getInstance(conf);
job.setJarByClass(PageRank.class);
job.setMapperClass(PageRankMapper.class);
job.setReducerClass(PageRankReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DoubleWritable.class);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output+index));
job.addCacheFile(new URI(weightPath));
URI[] uris = job.getCacheFiles();
if(uris != null)
for(int i=0;i4.4 输出
D 0.25
C 0.25
B 0.25
A 0.25
A 0.15
B 0.21666666666666665
C 0.4166666666666667
D 0.21666666666666665
A 0.13666666666666666
B 0.17666666666666667
C 0.51
D 0.17666666666666667
.... .... ...
第十次(最终)迭代输出:
A 0.10161308366485595
B 0.12875983487824416
C 0.6408672465786556
D 0.12875983487824416
C
D
B
A