Elasticsearch:在 Elasticsearch 中使用语言识别进行多语言搜索
我们很高兴地宣布,随着机器学习推理摄入处理器 (inference ingest processor)的发布,我们还将在 Elasticsearch 7.6 中发布语言识别。 在此发行版中,我们希望借此机会描述在多语言语料库中进行搜索的一些用例和策略,以及语言识别的作用。 过去我们讨论了其中一些主题,并将在以下一些示例的基础上继续进行讨论。
动机
在当今高度互连的世界中,我们发现文档和其他信息源以多种语言提供。这给许多搜索应用程序带来了问题。我们需要尽可能地了解这些文档的语言,以便我们对其进行适当的分析并提供最佳的搜索体验。输入语言标识。
语言识别用于改善这些多语言语料库的整体搜索相关性。给定一组文档,我们尚不知道它们包含的语言,因此我们想有效地对其进行搜索。这些文档可以包含一种或多种语言。前者在计算机科学等领域很普遍,英语是交流的主要语言,而后者在生物学和医学文本中很常见,拉丁语经常与英语穿插。
通过应用特定于语言的分析,我们可以通过确保适当地理解,索引和搜索文档术语来提高相关性(精确度和查全率)。通过在 Elasticsearch 中使用一套特定于语言的分析器(内置的和通过其他插件),我们可以提供改进 token 分词,token 过滤和术语过滤:
- 停止单词和同义词列表
- 词形规范化:词干和词形化
- 分解(例如德文,荷兰文,韩文)
出于类似的原因,我们发现更通用的自然语言处理(NLP)管道中的语言识别是利用高精度,特定于语言的算法和模型的第一个处理步骤之一。例如,经过预先训练的 NLP 模型(例如 Google 的 BERT 和 ALBERT 或 OpenAI 的 GPT-2)通常会针对每种语言的语料库或具有主要语言的语料库进行训练,并针对诸如文档分类,情感分析,命名实体识别等任务进行微调(NER)等
对于以下示例和策略,除非另有说明,否则我们将假定文档包含单一语言或主要语言。
特定语言分析的好处
为了进一步阐述这一点,让我们快速看一下特定语言分析器的一些好处。
分解
在德语中,名词通常是通过将其他名词复合在一起来构建的,以创造出精美而又难以阅读的复合词。一个简单的示例是将 “Jahr”(“年”)与 “Jahrhunderts”(“世纪”),“Jahreskalender”(“年历”)或 “ Schuljahr”(“学年”)等其他词组合。没有定制的分析器可以分解这些单词,我们将无法搜索 “jahr”,也无法获取有关 “Schuljahr” 学年的文档。此外,德语具有与其他拉丁语语言不同的复数形式和规则形式,这意味着搜索 “jahr” 也应与 “Jahre”(复数)和 “Jahren”(复数)匹配。
通用术语
某些语言还使用通用或特定于领域的术语。例如,“computer”是原样在其他语言中经常使用的单词。如果我们要搜索 “computer”,我们可能还会对非英语文档感兴趣。能够搜索一组已知的语言并且仍然匹配常用术语可能是一个有趣的用例。再次以德语为例,我们可能会以多种语言获得有关计算机安全性的文档。用德语表示的是 “Computersicherheit”(“sicherheit”,意思是 “安全性” 或 “安全”),并且只有使用德语分析仪时,才会搜索英语和德语之间的 “computer” 匹配项。
非拉丁语脚本
标准分析器对大多数拉丁语脚本语言(西欧语言)都适用。但是,使用非拉丁文字(例如西里尔字母/Cyrillic 或 CJK(中文/日文/韩文))后,它开始迅速崩溃。在上一个博客系列中,我们了解了 CJK 语言的形成方式以及使用特定于语言的分析器的必要性。例如,朝鲜语具有后置位置-在名词和代词中添加后缀会改变其含义。有时使用标准分析器匹配项搜索词,但是在匹配项评分上做得不好。这意味着你可能对文档有很好的查全率/recall,但是您的精度会受到影响。在其他情况下,标准分析器将不匹配任何术语,从而影响你的准确性和查全率。
让我们看一下“Winter Olympics”的工作示例。在韩语中,是 “동계올림픽대회는”,由 “동계” 表示“冬季”,“ 올림픽대회” 表示 “奥运会” 或 “奥林匹克竞赛”,最后是“는”,它是主题后置位–添加了后缀代表主题的单词。使用标准分析器搜索该确切的字符串(也就是整个字符串)会产生完美的匹配,但是搜索 “올림픽대회”(仅表示“奥运会”)不会返回任何结果。但是,通过使用 nori Korean 分析器,我们得到了匹配,因为 “동계올림픽대회는” / “冬季奥运会”已在索引时间正确地标记了。
语言识别入门
演示项目
为了帮助说明搜索中的语言识别用例和策略,我们设置了一个小型演示项目。 它包含此博客文章中的所有示例,以及用于对多语言语料库 WiLI-2018 进行索引和搜索的一些工具,您可以将其用作尝试和尝试多语言搜索的示例。 为了遵循这些示例,很有必要(但并非绝对必要)启动并运行演示项目,并为文档建立索引,以备日后参考。
对于这些实验,你可以在本地安装 Elasticsearch 7.6,或者免费试用 Elasticsearch Service。
第一次实验
语言识别是预先训练的模型,默认包含在 Elasticsearch 的默认发行版中。 通过在提取管道中设置推理处理器时,将lang_ident_model_1 指定为 model_id,将其与推理提取处理器结合使用。
{
"inference": {
"model_id": "lang_ident_model_1",
"inference_config": {},
"field_mappings": {}
}
}其余配置与其他模型相同,允许你指定设置,例如要输出的顶级类的数量,将包含预测的输出字段,以及最重要的是,对于我们的用例而言,要使用的输入字段 。 默认情况下,模型期望一个名为 text 的字段包含输入。 在以下示例中,我们将管道 _simulate API与一些单个字段文档一起使用。 它将输入内容字段映射到文本字段以进行推断-这种映射不会影响管道中的其他处理器。 然后输出前三个类进行检查(最有可能的三种推算的语言)。
# simulate a basic inference setup
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "lang_ident_model_1",
"inference_config": {
"classification": {
"num_top_classes": 3
}
},
"field_map": {
"contents": "text"
},
"target_field": "_ml.lang_ident"
}
}
]
},
"docs": [
{
"_source": {
"contents": "Das Leben ist kein Ponyhof"
}
},
{
"_source": {
"contents": "The rain in Spain stays mainly in the plains"
}
},
{
"_source": {
"contents": "This is mostly English but has a touch of Latin since we often just say, Carpe diem"
}
}
]
}输出显示了每个文档,以及 _ml.lang_ident 字段中的一些附加信息。 这包括存储在 _ml.lang_ident.predicted_value 中的每种前三种语言和每种顶级语言的概率。
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : "Das Leben ist kein Ponyhof",
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "de",
"class_probability" : 0.9996006023972855,
"class_score" : 0.9996006023972855
},
{
"class_name" : "el-Latn",
"class_probability" : 2.625873919853074E-4,
"class_score" : 2.625873919853074E-4
},
{
"class_name" : "ru-Latn",
"class_probability" : 1.130237050226503E-4,
"class_score" : 1.130237050226503E-4
}
],
"predicted_value" : "de",
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T06:52:39.922944Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : "The rain in Spain stays mainly in the plains",
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9988809847231199,
"class_score" : 0.9988809847231199
},
{
"class_name" : "ga",
"class_probability" : 7.764148026288316E-4,
"class_score" : 7.764148026288316E-4
},
{
"class_name" : "gd",
"class_probability" : 7.968926766495827E-5,
"class_score" : 7.968926766495827E-5
}
],
"predicted_value" : "en",
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T06:52:39.922952Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : "This is mostly English but has a touch of Latin since we often just say, Carpe diem",
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9997901768317939,
"class_score" : 0.9997901768317939
},
{
"class_name" : "ja",
"class_probability" : 8.756250766054857E-5,
"class_score" : 8.756250766054857E-5
},
{
"class_name" : "fil",
"class_probability" : 1.6980752372837307E-5,
"class_score" : 1.6980752372837307E-5
}
],
"predicted_value" : "en",
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T06:52:39.922955Z"
}
}
}
]
}看起来不错! 我们为第一份文件确定了德语,第二份和第三份文件确定为英语,即使在第三份文件中带有拉丁语也是如此。
搜索中的语言识别策略
现在,我们已经看到了语言识别的基本示例,是时候开始将其纳入索引和搜索策略了。
我们将使用两种基本的索引编制策略:按字段语言识别和按索引语言识别。在按字段语言策略中,我们将创建一个索引,其中包含一组特定于语言的字段,并使用针对每种语言量身定制的分析器。在搜索时,我们可以选择在已知语言字段中进行搜索,也可以在所有语言字段中进行搜索并选择最匹配的字段。在按索引语言策略中,我们将创建一组具有不同映射的特定于语言的索引,其中索引的字段具有针对该语言的分析器。在搜索时,我们可以对每个字段的语言采用类似的方法,并选择在单个语言索引中搜索,还是在搜索请求中使用索引模式跨多个索引进行搜索。
将这两种策略与你今天要执行的操作进行对比-多次索引同一字符串,每次都使用特定于语言的分析器对一个字段或索引进行索引。尽管这种方法可以工作,但确实会造成大量重复,从而导致查询速度变慢,并且大大超出需要的存储空间。
Indexing
让我们分解一下,看看两种索引策略,因为它们决定了我们可以使用的搜索策略。
按字段
在 “按字段语言策略” 中,我们将在提取管道中使用语言标识的输出和一系列处理器,以将输入字段存储在特定于语言的字段中。由于我们需要为每种语言设置特定的分析器,因此我们仅支持有限的语言集(德语,英语,韩语,日语和中文)。所有不使用我们支持的语言之一的文档都将使用标准分析器在默认字段中建立索引。
完整的管道定义可以在演示项目中找到:config/pipelines/lang-per-field.json (你需要下载 https://github.com/joshdevins/demo-es-lang-ident )
$ pwd
/Users/liuxg/python/demo-es-lang-ident
liuxg:demo-es-lang-ident liuxg$ tree -L 3
.
├── LICENSE
├── Makefile
├── README.md
├── bin
│ ├── index
│ └── search
├── config
│ ├── mappings
│ │ ├── de-analyzer.json
│ │ ├── lang-per-field.json
│ │ └── lang-per-index.json
│ └── pipelines
│ ├── lang-per-field.json
│ └── lang-per-index.json
├── examples
│ ├── olympics.txt
│ ├── simluate-concatenation.txt
│ ├── simulate-basic.out.json
│ ├── simulate-basic.txt
│ ├── simulate-concatenation.out.json
│ ├── simulate-lang-per-field.out.json
│ ├── simulate-lang-per-field.txt
│ ├── simulate-lang-per-index.out.json
│ └── simulate-lang-per-index.txt
└── requirements.txt支持此索引策略的映射如下所示:
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"contents": {
"properties": {
"language": {
"type": "keyword"
},
"supported": {
"type": "boolean"
},
"default": {
"type": "text",
"analyzer": "default",
"fields": {
"icu": {
"type": "text",
"analyzer": "icu_analyzer"
}
}
},
"en": {
"type": "text",
"analyzer": "english"
},
"de": {
"type": "text",
"analyzer": "german_custom"
},
"ja": {
"type": "text",
"analyzer": "kuromoji"
},
"ko": {
"type": "text",
"analyzer": "nori"
},
"zh": {
"type": "text",
"analyzer": "smartcn"
}
}
}
}
}
}(请注意,为简洁起见,上面的示例中省略了德语分析器配置,可以在以下位置找到:config/mappings/de_analyzer.json)
与前面的示例一样,我们将使用管道的 _simulate API 探索:
# simulate a language per-field and output top 3 language classes for inspection
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "lang_ident_model_1",
"inference_config": {
"classification": {
"num_top_classes": 3
}
},
"field_map": {
"contents": "text"
},
"target_field": "_ml.lang_ident"
}
},
{
"rename": {
"field": "contents",
"target_field": "contents.default"
}
},
{
"rename": {
"field": "_ml.lang_ident.predicted_value",
"target_field": "contents.language"
}
},
{
"script": {
"lang": "painless",
"source": "ctx.contents.supported = (['de', 'en', 'ja', 'ko', 'zh'].contains(ctx.contents.language))"
}
},
{
"set": {
"if": "ctx.contents.supported",
"field": "contents.{{contents.language}}",
"value": "{{contents.default}}",
"override": false
}
}
]
},
"docs": [
{
"_source": {
"contents": "Das leben ist kein Ponyhof"
}
},
{
"_source": {
"contents": "The rain in Spain stays mainly in the plains"
}
},
{
"_source": {
"contents": "オリンピック大会"
}
},
{
"_source": {
"contents": "로마는 하루아침에 이루어진 것이 아니다"
}
},
{
"_source": {
"contents": "授人以鱼不如授人以渔"
}
},
{
"_source": {
"contents": "Qui court deux lievres a la fois, n’en prend aucun"
}
},
{
"_source": {
"contents": "Lupus non timet canem latrantem"
}
},
{
"_source": {
"contents": "This is mostly English but has a touch of Latin since we often just say, Carpe diem"
}
}
]
}这是按字段使用语言的输出:
{
"docs" : [
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"de" : "Das leben ist kein Ponyhof",
"default" : "Das leben ist kein Ponyhof",
"language" : "de",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "de",
"class_probability" : 0.9996006023972855,
"class_score" : 0.9996006023972855
},
{
"class_name" : "el-Latn",
"class_probability" : 2.625873919853074E-4,
"class_score" : 2.625873919853074E-4
},
{
"class_name" : "ru-Latn",
"class_probability" : 1.130237050226503E-4,
"class_score" : 1.130237050226503E-4
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638578Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"en" : "The rain in Spain stays mainly in the plains",
"default" : "The rain in Spain stays mainly in the plains",
"language" : "en",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9988809847231199,
"class_score" : 0.9988809847231199
},
{
"class_name" : "ga",
"class_probability" : 7.764148026288316E-4,
"class_score" : 7.764148026288316E-4
},
{
"class_name" : "gd",
"class_probability" : 7.968926766495827E-5,
"class_score" : 7.968926766495827E-5
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638582Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"default" : "オリンピック大会",
"language" : "ja",
"ja" : "オリンピック大会",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "ja",
"class_probability" : 0.9993823252841599,
"class_score" : 0.9993823252841599
},
{
"class_name" : "el",
"class_probability" : 2.6448654791599055E-4,
"class_score" : 2.6448654791599055E-4
},
{
"class_name" : "sd",
"class_probability" : 1.4846805271384584E-4,
"class_score" : 1.4846805271384584E-4
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638584Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"default" : "로마는 하루아침에 이루어진 것이 아니다",
"language" : "ko",
"ko" : "로마는 하루아침에 이루어진 것이 아니다",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "ko",
"class_probability" : 0.9999939196272863,
"class_score" : 0.9999939196272863
},
{
"class_name" : "ka",
"class_probability" : 3.0431805047662344E-6,
"class_score" : 3.0431805047662344E-6
},
{
"class_name" : "am",
"class_probability" : 1.710514725818281E-6,
"class_score" : 1.710514725818281E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638586Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"default" : "授人以鱼不如授人以渔",
"language" : "zh",
"zh" : "授人以鱼不如授人以渔",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "zh",
"class_probability" : 0.9999810103320087,
"class_score" : 0.9999810103320087
},
{
"class_name" : "ja",
"class_probability" : 1.0390454083183788E-5,
"class_score" : 1.0390454083183788E-5
},
{
"class_name" : "ka",
"class_probability" : 2.6302271562335787E-6,
"class_score" : 2.6302271562335787E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638588Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"default" : "Qui court deux lievres a la fois, n’en prend aucun",
"language" : "fr",
"supported" : false
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "fr",
"class_probability" : 0.9999669852240882,
"class_score" : 0.9999669852240882
},
{
"class_name" : "gd",
"class_probability" : 2.3485226102079597E-5,
"class_score" : 2.3485226102079597E-5
},
{
"class_name" : "ht",
"class_probability" : 3.536708810360631E-6,
"class_score" : 3.536708810360631E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638592Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"default" : "Lupus non timet canem latrantem",
"language" : "la",
"supported" : false
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "la",
"class_probability" : 0.614050940088811,
"class_score" : 0.614050940088811
},
{
"class_name" : "fr",
"class_probability" : 0.32530021315840363,
"class_score" : 0.32530021315840363
},
{
"class_name" : "sq",
"class_probability" : 0.03353817054854559,
"class_score" : 0.03353817054854559
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638594Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"en" : "This is mostly English but has a touch of Latin since we often just say, Carpe diem",
"default" : "This is mostly English but has a touch of Latin since we often just say, Carpe diem",
"language" : "en",
"supported" : true
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9997901768317939,
"class_score" : 0.9997901768317939
},
{
"class_name" : "ja",
"class_probability" : 8.756250766054857E-5,
"class_score" : 8.756250766054857E-5
},
{
"class_name" : "fil",
"class_probability" : 1.6980752372837307E-5,
"class_score" : 1.6980752372837307E-5
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T07:29:05.638596Z"
}
}
}
]
}如预期的那样,我们将德语字段存储在 contents.de 中,将英语存储在 contents.en 中,将韩文存储在 contents.ko 中,等等。请注意,我们也混入了一些不受支持的语言示例-法语和拉丁语。我们看到它们没有得到支持的标志,并且只能在默认字段中进行搜索。还要查看拉丁文示例中排在前列的预测类别。看起来该模型认为它是拉丁文,这是正确的,但该模型尚不确定,并预测法语排名第二。
这只是带有语言识别的摄取管道的基本示例,但希望它使你对可能的想法有所了解。借助摄取管道的灵活性,我们可以完成许多不同的方案。我们将在文章末尾探讨一些替代方法。此示例中的某些步骤可以在生产管道中组合或省略,但是请记住,好的数据处理管道是易于读取和理解的管道,而不是行数最少的管道。
按索引
我们的按索引语言策略使用与按字段语言策略管道相同的基本构建块。最大的区别在于,我们使用了不同的索引,而不是存储到特定于语言的字段。这是可能的,因为在摄取时,我们可以设置文档的 _index 字段,这使我们能够覆盖默认值并将其设置为特定于语言的索引名称。如果我们不支持该语言,则跳过该步骤,该文档将在默认索引中建立索引。简单!
可以在演示项目中找到完整的管道定义:config/pipelines/lang-per-index.json
然后,支持此索引策略的映射如下所示。
{
"settings": {
"index": {
"number_of_shards": 1,
"number_of_replicas": 0
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"contents": {
"properties": {
"language": {
"type": "keyword"
},
"text": {
"type": "text",
"analyzer": "default"
}
}
}
}
}
}请注意,在该映射中,我们没有指定自定义分析器,而是使用此文件作为模板。 创建每种特定于语言的索引时,我们为该语言设置了分析器。
模拟此管道:
# simulate a language per-index and output top 3 language classes for inspection
POST _ingest/pipeline/_simulate
{
"pipeline": {
"processors": [
{
"inference": {
"model_id": "lang_ident_model_1",
"inference_config": {
"classification": {
"num_top_classes": 3
}
},
"field_map": {
"contents": "text"
},
"target_field": "_ml.lang_ident"
}
},
{
"rename": {
"field": "contents",
"target_field": "contents.text"
}
},
{
"rename": {
"field": "_ml.lang_ident.predicted_value",
"target_field": "contents.language"
}
},
{
"set": {
"if": "['de', 'en', 'ja', 'ko', 'zh'].contains(ctx.contents.language)",
"field": "_index",
"value": "{{_index}}_{{contents.language}}",
"override": true
}
}
]
},
"docs": [
{
"_source": {
"contents": "Das leben ist kein Ponyhof"
}
},
{
"_source": {
"contents": "The rain in Spain stays mainly in the plains"
}
},
{
"_source": {
"contents": "オリンピック大会"
}
},
{
"_source": {
"contents": "로마는 하루아침에 이루어진 것이 아니다"
}
},
{
"_source": {
"contents": "授人以鱼不如授人以渔"
}
},
{
"_source": {
"contents": "Qui court deux lievres a la fois, n’en prend aucun"
}
},
{
"_source": {
"contents": "Lupus non timet canem latrantem"
}
},
{
"_source": {
"contents": "This is mostly English but has a touch of Latin since we often just say, Carpe diem"
}
}
]
}这是带有按索引语言的输出:
{
"docs" : [
{
"doc" : {
"_index" : "_index_de",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "de",
"text" : "Das leben ist kein Ponyhof"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "de",
"class_probability" : 0.9996006023972855,
"class_score" : 0.9996006023972855
},
{
"class_name" : "el-Latn",
"class_probability" : 2.625873919853074E-4,
"class_score" : 2.625873919853074E-4
},
{
"class_name" : "ru-Latn",
"class_probability" : 1.130237050226503E-4,
"class_score" : 1.130237050226503E-4
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969448Z"
}
}
},
{
"doc" : {
"_index" : "_index_en",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "en",
"text" : "The rain in Spain stays mainly in the plains"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9988809847231199,
"class_score" : 0.9988809847231199
},
{
"class_name" : "ga",
"class_probability" : 7.764148026288316E-4,
"class_score" : 7.764148026288316E-4
},
{
"class_name" : "gd",
"class_probability" : 7.968926766495827E-5,
"class_score" : 7.968926766495827E-5
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969452Z"
}
}
},
{
"doc" : {
"_index" : "_index_ja",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "ja",
"text" : "オリンピック大会"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "ja",
"class_probability" : 0.9993823252841599,
"class_score" : 0.9993823252841599
},
{
"class_name" : "el",
"class_probability" : 2.6448654791599055E-4,
"class_score" : 2.6448654791599055E-4
},
{
"class_name" : "sd",
"class_probability" : 1.4846805271384584E-4,
"class_score" : 1.4846805271384584E-4
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969454Z"
}
}
},
{
"doc" : {
"_index" : "_index_ko",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "ko",
"text" : "로마는 하루아침에 이루어진 것이 아니다"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "ko",
"class_probability" : 0.9999939196272863,
"class_score" : 0.9999939196272863
},
{
"class_name" : "ka",
"class_probability" : 3.0431805047662344E-6,
"class_score" : 3.0431805047662344E-6
},
{
"class_name" : "am",
"class_probability" : 1.710514725818281E-6,
"class_score" : 1.710514725818281E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969456Z"
}
}
},
{
"doc" : {
"_index" : "_index_zh",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "zh",
"text" : "授人以鱼不如授人以渔"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "zh",
"class_probability" : 0.9999810103320087,
"class_score" : 0.9999810103320087
},
{
"class_name" : "ja",
"class_probability" : 1.0390454083183788E-5,
"class_score" : 1.0390454083183788E-5
},
{
"class_name" : "ka",
"class_probability" : 2.6302271562335787E-6,
"class_score" : 2.6302271562335787E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969457Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "fr",
"text" : "Qui court deux lievres a la fois, n’en prend aucun"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "fr",
"class_probability" : 0.9999669852240882,
"class_score" : 0.9999669852240882
},
{
"class_name" : "gd",
"class_probability" : 2.3485226102079597E-5,
"class_score" : 2.3485226102079597E-5
},
{
"class_name" : "ht",
"class_probability" : 3.536708810360631E-6,
"class_score" : 3.536708810360631E-6
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969459Z"
}
}
},
{
"doc" : {
"_index" : "_index",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "la",
"text" : "Lupus non timet canem latrantem"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "la",
"class_probability" : 0.614050940088811,
"class_score" : 0.614050940088811
},
{
"class_name" : "fr",
"class_probability" : 0.32530021315840363,
"class_score" : 0.32530021315840363
},
{
"class_name" : "sq",
"class_probability" : 0.03353817054854559,
"class_score" : 0.03353817054854559
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969461Z"
}
}
},
{
"doc" : {
"_index" : "_index_en",
"_type" : "_doc",
"_id" : "_id",
"_source" : {
"contents" : {
"language" : "en",
"text" : "This is mostly English but has a touch of Latin since we often just say, Carpe diem"
},
"_ml" : {
"lang_ident" : {
"top_classes" : [
{
"class_name" : "en",
"class_probability" : 0.9997901768317939,
"class_score" : 0.9997901768317939
},
{
"class_name" : "ja",
"class_probability" : 8.756250766054857E-5,
"class_score" : 8.756250766054857E-5
},
{
"class_name" : "fil",
"class_probability" : 1.6980752372837307E-5,
"class_score" : 1.6980752372837307E-5
}
],
"model_id" : "lang_ident_model_1"
}
}
},
"_ingest" : {
"timestamp" : "2020-07-29T08:21:09.969465Z"
}
}
}
]
}如你所料,语言识别结果与逐字段策略相同,唯一的区别是我们如何使用管道中的信息将文档路由到正确的索引。
Search
根据这两种索引策略,最佳搜索方式是什么?如上所述,我们为每种索引策略提供了两个选项。一个常见的问题是,我们如何为查询字符串指定一种特定于语言的分析器,以便它在索引字段上匹配?不用担心,你无需在搜索时指定特殊的分析器。除非你在查询 DSL 中指定 search_analyzer,否则查询字符串将由与匹配字段相同的分析器进行分析。与在每个字段的语言示例中一样,如果你具有字段 en 和 de,则在 en 字段匹配时将使用英语分析器分析查询字符串,而在 de 字段匹配时将使用 german_custom 分析器分析查询字符串。
查询语言
在研究搜索策略之前,重要的是首先在用户的查询字符串本身上设置一些有关语言识别的上下文。你可能会想,“好吧,既然我们知道所索引文档的(主要)语言,为什么不只对查询字符串进行语言识别并对相应的字段或索引进行常规搜索呢?” 不幸的是,搜索查询往往很短。喜欢,真的很短!早在2001年,一项对旧式 Excite 优秀网络搜索引擎的研究[1]显示,平均用户查询仅包含2.4个词!那是前一段时间,尽管对话搜索和自然语言查询已经发生了很多变化(例如 “how do I use Elasticsearch to search in multilingual corpora”),但是搜索查询仍然太短,无法用于识别语言。许多语言识别算法最好使用50个以上的字符[2]。为了解决这个问题,我们经常使用专有名词,实体名称或科学名称(例如 “Justin Trudeau”,“Foo Fighters” 或 “plantar fasciitis”)作为搜索查询。用户可能希望使用任意语言的文档,但仅通过分析这些类型的查询字符串就无法知道。
因此,我们不建议仅对查询字符串使用语言识别(任何形式)。如果你确实想使用用户的查询语言来选择搜索字段或索引,那么最好考虑使用利用有关用户的隐式或显式信息的其他方法。例如,隐式上下文可能使用的是网站域(例如.com或.de)或从中下载你的应用的应用商店的区域设置(例如美国商店或德国商店)。但是,在大多数情况下,最好的办法就是问你的用户!新用户首次访问该站点时,许多站点都有区域设置选择。你还可以考虑在文档语言上使用构面(带有术语汇总),以帮助用户将其引导至他们感兴趣的语言。
按字段
使用按字段策略,我们有多个语言子字段,因此我们需要同时搜索所有子字段并选择得分最高的字段。这是相对简单的,因为在索引管道中,我们仅设置一个语言字段。因此,当我们搜索多个字段时,实际上只填充了其中一个。为此,我们将使用类型为best_fields(默认)的 multi_match 查询。此组合作为 dis_max 查询执行,由于我们对单个字段(而不是跨字段)中的所有术语都感兴趣,因此我们使用此组合。
GET lang-per-field/_search
{
"query": {
"multi_match": {
"query": "jahr",
"type": "best_fields",
"fields": [
"contents.de",
"contents.en",
"contents.ja",
"contents.ko",
"contents.zh"
]
}
}
}如果要搜索所有语言,我们还可以将 content.default 字段添加到 multi_match 查询中。 每字段策略的一个优势还在于能够使用识别的语言来增强文档,例如与上述用户语言或地区相匹配的文档。 由于它可以直接用于影响相关性,因此可以提高准确性和查全率。 同样,如果我们要搜索一种语言,例如当我们知道用户的查询语言时,我们可以简单地在语言字段的 match 查询中使用该语言,例如 contents.de。
按索引
使用基于索引的策略,我们可以有多个语言索引,但是每个索引都具有相同的字段名称。 这意味着我们可以使用一个简单的查询,并且在发出搜索请求时仅指定索引模式:
GET lang-per-index_*/_search
{
"query": {
"match": {
"contents.text": "jahr"
}
}
}如果要搜索所有语言,请使用也与默认索引匹配的索引模式:lang-per-index*(请注意,下划线不存在)。 如果我们要搜索一种语言,则可以简单地使用该语言的索引,例如 lang-per-index_de。
例子
使用我们在 “动机” 部分中描述的示例,我们可以尝试在 WiLI-2018 语料库中进行搜索。 在演示项目中尝试这些命令,看看会发生什么。
我们首先按照 https://github.com/joshdevins/demo-es-lang-ident 里的要求来进行安装。
经过测试,为了能够使得下面的运行能够顺利进行,我们必须对 bin/search 里的 python 做如下的修改:
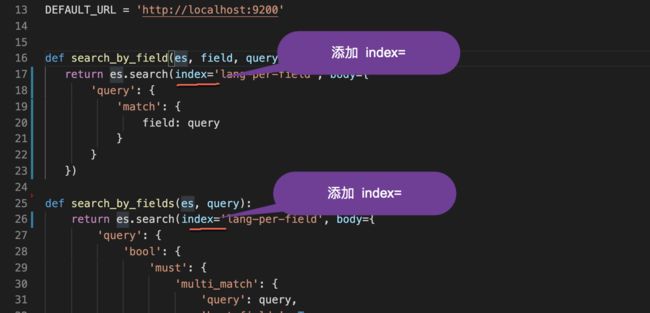
在这个文件中,我们需要对所有的 search_by_xxx 方法做相同的修改。
分解
# only matching exactly on the term "jahr"
bin/search --strategy default jahr# matches: "jahr", "jahre", "jahren", "jahrhunderts", etc.
bin/search --strategy per-field jahr常见术语
# only matching exactly on the term "computer", multiple languages are in the results
bin/search --strategy default computer# matches compound German words as well: "Computersicherheit" (computer security)
bin/search --strategy per-field computerNon-Latin scripts:
# standard analyzer gets poor precision and returns irrelevant/non-matching results with "network"/"internet": "网络"
bin/search --strategy default 网络# ICU and language-specific analysis gets things right, but note the different scores
bin/search --strategy icu 网络
bin/search --strategy per-field 网络比较
基于这两种策略,你应该实际使用哪一种? 这要看情况。 以下每种方法的优缺点有助于你做出决定。
| 优点 | 缺点 | |
|---|---|---|
| 按字段 |
|
|
| 按索引 |
|
|
总结
希望这篇博客文章为你提供一个起点,以及有关如何成功地将语言识别用于多语言搜索的一些想法! 我们希望收到你的来信,所以请不要犹豫,请加入我们的讨论论坛。 如果你成功使用语言识别或遇到任何问题,请告诉我们。
参考:
【1】https://www.elastic.co/blog/multilingual-search-using-language-identification-in-elasticsearch