DANet: 利用双注意力捕获全局上下文信息解决场景分割任务
文章目录
- 1. 相关资源
- 2. 问题描述
- 3. 创新点
- 4. 整体架构
- 4.1 Position Attention Module
- 4.2 Channel Attention Module
- 4.3 加深理解
- 5. 实验结果
- 6. 总结
- 参考文献
1. 相关资源
- 原文地址:Dual Attention Network for Scene Segmentation [ 2019] [CVPR] [DANet] [场景分割] [双重注意力]
- 源码地址:https://github.com/junfu1115/ DANet/
2. 问题描述
场景分割的目标是识别每一个像素。要分割的对象或内容经常受尺度,光照,遮挡的影响,由于卷积运算本身属于local operation,导致局部感受野。因此,具有相同标签的像素的特征可能具有一些差异,这些差异引入了类内不一致性并影响了识别准确性。
为了解决这个问题,作者通过建立与注意力机制的特征之间的关联来探索全局上下文信息,提出本文的双注意力网络。
已有的解决上述问题的工作参考:DeepLabV3[1]和PSP-Net[2]等方法利用多尺度上下文融合,U-Net[3]和PSP-Net[4]等编码器-解码器结构用于融合中级和高级语义特征。
作者认为虽然上下文融合有助于捕获不同比例的对象,但它无法利用全局视图中对象或内容之间的关系,这对于场景分割也是必不可少的。
3. 创新点
提出一种双注意力网络,包括位置注意力模块(Position Attention Module)和通道注意力模块(Channel Attention Module)。
- 位置注意力模块,引入自注意力机制来捕获特征图中的任意两个位置之间的空间依赖性。对于某个位置的特征,通过加权求和在所有位置聚合特征来更新,其中权重由相应两个位置之间的特征相似性决定。
- 通道注意力模块,使用类似的自注意力机制来捕获任意两个通道图之间的通道依赖关系,并使用所有频道图的加权和来更新每个通道图。
4. 整体架构
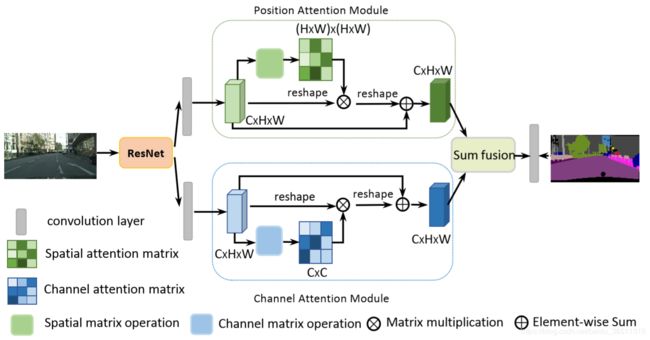
网络的主干(backbone) 采用ResNet-50或ResNet-101,将 Attention Module 接在主干网络末端,两个注意力模块的输出融合之后再上采样回原来的大小进行预测,训练中也分别用两个注意力模块的输出进行辅助监督。
为什么要把 Attention Module 接在主干网络末端? 我觉得主要因为Attention Module中进行了矩阵运算,运算量的大小取决于特征图的大小,网络末端的特征图经过很多次下采样(8x or 16x…)后相比原图已经很小了, 因此把Attention Module放在此处可以最大限度降低计算量。
4.1 Position Attention Module
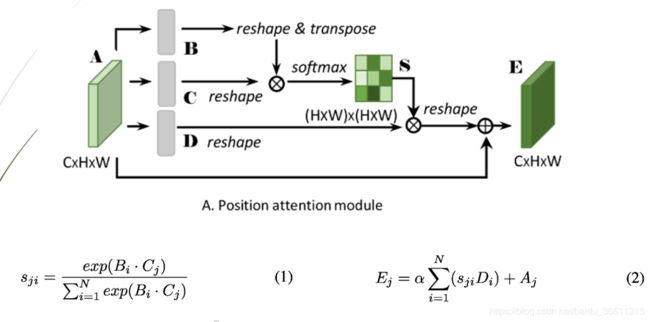
解释如下:

核心思路就是,当我们要求特征图中某一个位置的值时,常规的卷积操作(比如3x3)只用了该位置周围的8个像素值的加权和。而本文的位置注意力中,通过矩阵乘法操作,求一个位置的值,相当于是所有位置的值的加权和。
公式2利用了残差的思想,α是一个可学习的参数。文中所说的位置注意力模块可自适应的聚合全局上下文信息,应该就体现再这里,α的初始值为0,让网络自己学习,是否需要attention特征或为attention特征分配多少权重。
我觉得位置注意力还是比较好理解的,这种实现方式可能是借鉴了 CVPR 2018 的一篇文章 Non-local Neural Networks。
类似的实现方式还有,CCNet: Criss-Cross Attention for Semantic Segmentation [ICCV2019], 十字注意力网络,参数量更小。
结合代码更好理解:
class PAM_Module(Module):
""" Position attention module"""
#Ref from SAGAN
def __init__(self, in_dim):
super(PAM_Module, self).__init__()
self.chanel_in = in_dim
self.query_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self, x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X (HxW) X (HxW)
"""
m_batchsize, C, height, width = x.size()
proj_query = self.query_conv(x).view(m_batchsize, -1, width*height).permute(0, 2, 1)
proj_key = self.key_conv(x).view(m_batchsize, -1, width*height)
energy = torch.bmm(proj_query, proj_key)
attention = self.softmax(energy)
proj_value = self.value_conv(x).view(m_batchsize, -1, width*height)
out = torch.bmm(proj_value, attention.permute(0, 2, 1))
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
4.2 Channel Attention Module
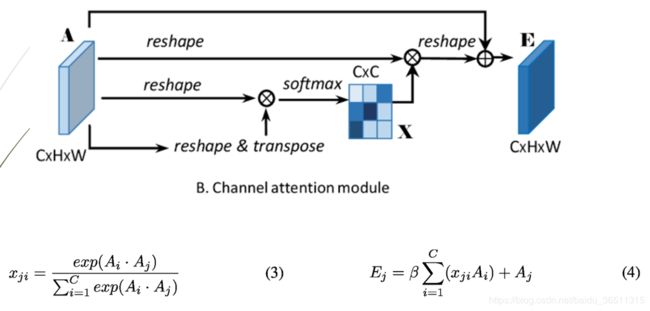
通道注意力的实现类似位置注意力。只是矩阵乘法那里,相当于求得是通道维度的加权和,看公式(1)和(3)的差别就能看出了。

结合代码更好理解:
class CAM_Module(Module):
""" Channel attention module"""
def __init__(self, in_dim):
super(CAM_Module, self).__init__()
self.chanel_in = in_dim
self.gamma = Parameter(torch.zeros(1))
self.softmax = Softmax(dim=-1)
def forward(self,x):
"""
inputs :
x : input feature maps( B X C X H X W)
returns :
out : attention value + input feature
attention: B X C X C
"""
m_batchsize, C, height, width = x.size()
proj_query = x.view(m_batchsize, C, -1)
proj_key = x.view(m_batchsize, C, -1).permute(0, 2, 1)
energy = torch.bmm(proj_query, proj_key)
energy_new = torch.max(energy, -1, keepdim=True)[0].expand_as(energy)-energy
attention = self.softmax(energy_new)
proj_value = x.view(m_batchsize, C, -1)
out = torch.bmm(attention, proj_value)
out = out.view(m_batchsize, C, height, width)
out = self.gamma*out + x
return out
4.3 加深理解
我当时有个疑问,为什么位置注意力求一个位置的值是用所有位置的加权和?为了加深理解,我就用一个简单的实例来分别推导两个注意力模块的具体计算过程,发现确实如此。下图仅供参考,就不做详细说明了,读者可以尝试动手推导一番 ^_^。

5. 实验结果
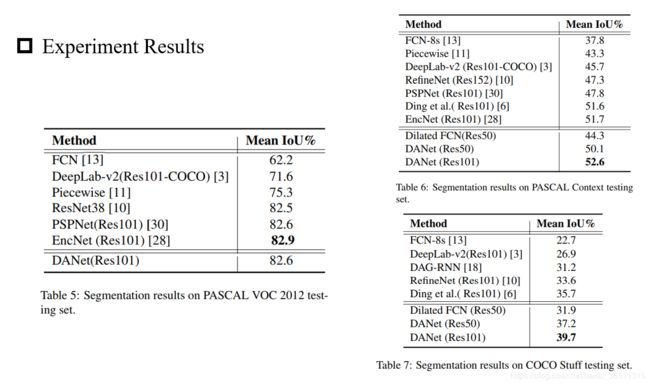
看一下作者论文中的实验结果对比。论文中在4个公开的数据集(Cityscapes,PASCAL VOC2012,PASCAL Context和COCO Stuff)上都做了实验。
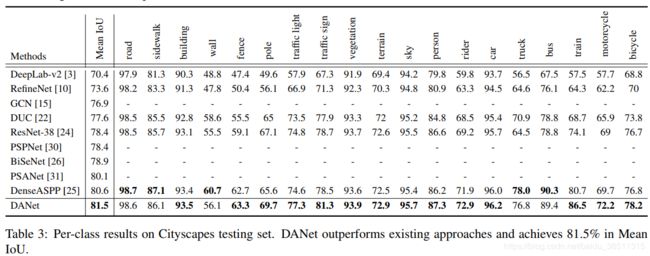
6. 总结
位置注意力或空间注意力可以简单理解为:当我们要求一个位置的特征值时,为了利用全局上下文信息,就把所有位置的值都拿过来进行加权和得到该值,而不是简单的把该值周围或者附近的一些值拿来求加权和。
通道注意力就是把每个通道图进行求值,再分配权重,对目标相应较大的通道就分配更大权重。
一句话总结,通道注意力教网络Look What,位置注意力教网络Look Where。
参考文献
- DeepLabV3: Rethinking Atrous Convolution for Semantic Image Segmentation
- PSPNet: Pyramid Scene Parsing Network
- U-Net: Convolutional Networks for Biomedical Image Segmentation
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- Non-local: Non-local Neural Networks [CVPR] [2018]
- CCNet: Criss-Cross Attention for Semantic Segmentation [ICCV] [2019]