tensorflow编程入门笔记之一
基本上每一个语言或者工具都有自己的“hello world” demo,那么学习它们一般都会从这个“hello world”开始。今天我们就来看看tensorflow的“hello world”(非官网)。
在开始编写“hello world”之前我们先看看tensorflow的编程模型。
一. tensorflow编程模型简介
这部分的一个很好的教程是官网上的Basic Usage,讲解的还是很清晰的。
Tensorflow中的计算可以表示为一个有向图(directed graph),或称计算图(computation graph),其中每一个运算操作将作为一个节点(node),节点与节点之间的连接成为边(edge),而在计算图的边中流动(flow)的数据被称为张量(tensor),所以形象的看整个操作就好像数据(tensor)在计算图(computation graphy)中沿着边(edge)流过(flow)一个个节点(node),这就是tensorflow名字的由来的。
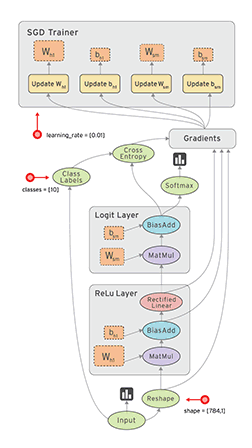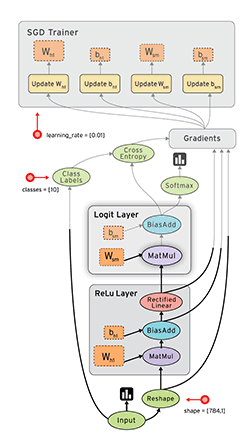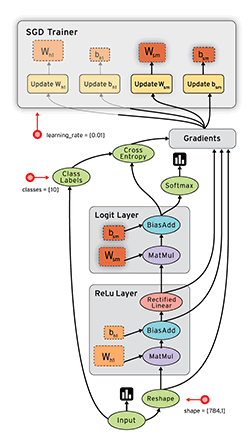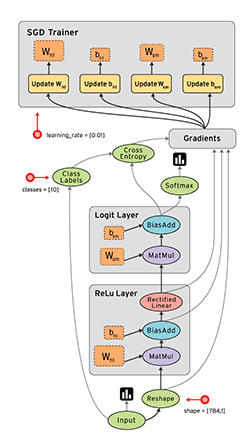
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。计算图描述了数据的计算流程,它也负责维护和更新状态,用户可以对计算图的分支进行条件控制或循环操作。用户可以使用pyton、C++、Go、Java等语言设计计算图。tensorflow通过计算图将所有的运算操作全部运行在python外面,比如通过c++运行在cpu或通过cuda运行在gpu 上,所以实际上python只是一种接口,真正的核心计算过程还是在底层采用c++或cuda在cpu或gpu上运行。
一个 TensorFlow图描述了计算的过程. 为了进行计算, 图必须在会话(session)里被启动. 会话将图的op分发到诸如CPU或GPU之的备上, 同时提供执行op的方法. 这些方法执行后, 将产生的tensor返回. 在Python语言中, 返回的tensor是numpy ndarray对象; 在C和C++语言中, 返回的tensor是tensorflow::Tensor实例。
从上面的描述中我们可以看到,tensorflow的几个比较重要的概念:tensor, computation graphy, node, session。正如前面所说,整个操作就好像数据(tensor)在计算图(computation graphy)中沿着边(edge)流过(flow)一个个节点(node),然后通过会话(session)启动计算。所以简单来说,要完成这整个过程,我们需要的东西是要定义数据、计算图和计算图上的节点,以及启动计算的会话。所以在实际使用中我们要做的大部分工作应该就是定义这些内容了。
二. tensorflow基本使用
正如官方教程里所说:
To use TensorFlow you need to understand how TensorFlow:
- Represents computations as graphs.
- Executes graphs in the context of Sessions.
- Represents data as tensors.
- Maintains state with Variables.
- Uses feeds and fetches to get data into and out of arbitrary operations.
我们只有理解了这些概念,明白它们分别是做什么的,才能掌握tensorflow的使用方法。下面简单介绍下这些概念及使用。
- 计算图(computation graphy)
计算图是由一个个节点和连接各个节点的边组成,因此要定义一个计算图,只需要定义好各个节点以及节点的输入输出(对应计算图的边)。节点代表各种操作,如加法、乘法、卷积运算等等,输入输出主要是各种数据(tensor)。下面是一个简单的计算图定义方法示例(来自官网):
import tensorflow as tf
# Create a Constant op that produces a 1x2 matrix. The op is
# added as a node to the default graph.
#
# The value returned by the constructor represents the output
# of the Constant op.
matrix1 = tf.constant([[3., 3.]])
# Create another Constant that produces a 2x1 matrix.
matrix2 = tf.constant([[2.],[2.]])
# Create a Matmul op that takes 'matrix1' and 'matrix2' as inputs.
# The returned value, 'product', represents the result of the matrix
# multiplication.
product = tf.matmul(matrix1, matrix2)
当然,我们也可以添加更多更复杂的操作(operation)的节点(node)到计算图(computation graphy)中,如果增加一些卷积网络节点、全连接网络节点等等就可以组建一个神经网络计算图了。
- 节点(node)
计算图中的每个节点可以有任意多个输入和任意多个输出,每个节点描述了一种运算操作(operation, op),节点可以算作运算操作的实例化(instance)。一种运算操作代表了一种类型的抽象运算,比如矩阵乘法货响亮加法。tensorflow内建了很多种运算操作,如下表所示:
| 类型 | 示例 |
|---|---|
| 标量运算 | Add、Sub、Mul、Div、Exp、Log、Greater、Less、Equal |
| 向量运算 | Concat、Slice、Splot、Constant、Rank、Shape、Shuffle |
| 矩阵运算 | Matmul、MatrixInverse、MatrixDeterminant |
| 带状态的运算 | Variable、Assign、AssignAdd |
| 神经网络组件 | SoftMax、Sigmoid、ReLU、Convolution2D、MaxPooling |
| 存储、恢复 | Save、Restore |
| 队列及同步运算 | Enqueue、Dequeue、MutexAcquire、MutexRelease |
| 控制流 | Merge、Switch、Enter、Leave、NextIteration |
在tensorflow中,也可以通过注册机制加入新的运算操作或者运算核,这和torch上的注册机制类似。
- 会话(session)
正如我们前面所说,计算图里描述的计算并没有真正执行,只是进行了定义和描述,要实际执行我们就需要在会话(session)里被启动. 这时session才会将计算图上的节点操作op分发到诸如CPU或GPU之类的设备上, 同时提供执行op的方法. 这些方法执行后,将产生的tensor返回.
要启动计算图,我们收下需要定义一个session对象:
sess = tf.Session()
启动操作,最简单的就是调用函数run:
result = sess.run(product)
tensorflow还支持分布式session,将计算图布置到多个机器上进行计算。由于我这边不具备该环境,就不介绍这部分内容了。
另外tensorflow还支持交互环境下采用InteractiveSession定义一个交互session,然后所有的操作都默认在该session上运行,可以直接调用Tensor.eval()和Operation.run()两个方法,如:
# Enter an interactive TensorFlow Session.
import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.Variable([1.0, 2.0])
a = tf.constant([3.0, 3.0])
# Initialize 'x' using the run() method of its initializer op.
x.initializer.run()
# Add an op to subtract 'a' from 'x'. Run it and print the result
sub = tf.sub(x, a)
print(sub.eval())
# ==> [-2. -1.]
# Close the Session when we're done.
sess.close()
- 数据(tensor)
TensorFlow程序使用tensor数据结构来代表所有的数据, 计算图中的节点间传递的数据都是tensor. 你可以把TensorFlow tensor看作是一个n维的数组或列表. 一个 tensor包含一个静态类型rank, 和一个shape。 - 变量(Variable)
在tensorflow里有一类数据比较特殊,那就是我们需要在整个计算图执行过程中需要保存的状态。比如我们在进行神经网络训练时要时刻保存并更新的网络参数,这时我们就需要用到Varibale来保存这些参数。其实,我们在前面的示例中已经用到了变量的定义了,它的定义关键字为Variable,如上面的x = tf.Variable([1.0, 2.0])。 - feed & fetch
我们都知道,进行机器学习或者神经网络训练时,都需要大量的训练数据。细心的朋友可能注意到,我们前面一直没讲到训练数据怎么定义,怎么输入到网络里。实际上,tensorflow提供了一个feed机制来将tensor直接放置到计算图的任意节点操作上去。“feed”这个词用的很形象啊,就像我们在上课学习时,老师拿课本里的各种例子、习题往我们脑子里喂。那么,这个利用这个feed机制我们就可以把训练数据“喂”到计算图的输入中去。一般我们采用placeholder来指定一个feed操作,这个placeholder就像是一个容器一样来接收训练数据,然后在最终进行计算时只需要用placehoder里的数据替换计算图的输入量就可以了。一个简单的例子:
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.mul(input1, input2)
with tf.Session() as sess:
print(sess.run([output], feed_dict={input1:[7.], input2:[2.]}))
采用两个placeholder操作来定义两个输入,在后面的see.run()里采用feed_dict替换成真正的训练数据,feed_dict里的才是真正的数据。一般情况,placeholder和feed_dict是搭配使用的。
fetch,正如其字面意思,就是取回数据的意思。我们将计算图部署到session上进行计算后,需要将计算结果取回,这就是一个fetch。下面是取回多个tensor的例子:
input1 = tf.constant(3.0)
input2 = tf.constant(2.0)
input3 = tf.constant(5.0)
intermed = tf.add(input2, input3)
mul = tf.mul(input1, intermed)
with tf.Session() as sess:
result = sess.run([mul, intermed])
print result
上面就是tensorflow编程模型的一些基本概念和内容。通过上面的介绍,我们可以用一句话来总结tensorflow的一个工作流程:
那么我们也可以简单总结出tensorflow编程的一个基本步骤:
- 定义数据
- 定义计算图与变量
- 定义会话
- 进行计算
三. 用tensorflow搭建神经网络“hello world”
按照我们上一节介绍的tensorflow编程的基本步骤,我们来搭建我们的第一个神经网络——基于mnist数据集的手写数字识别,即基于图片的10分类问题。
此部分可以参考官网教程MNIST For ML Beginners。
MNIST是一个简单的机器视觉数据集,如下图所示,它有几万张28×28像素的手写数字组成,这些图片只包含灰度信息,我们的任务就是对这些手写数字进行分类,转成0~9一共10类。
1.定义数据
在神经网络里我们需要定义的数据就是输入训练/测试数据,而变量用来存储网络模型里的各种参数。如:
# 输入数据(包括训练数据和测试数据)
x = tf.placeholder( tf.float32, [None, 784] )
y_ = tf.placeholder( tf.float32, [None, 10] )
这里我们把图片的2828个像素展开成一维列向量(2828-784)
2.定义计算图与变量
对于神经网络来说,涉及到的操作主要有三部分:网络模型定义,损失函数定义、训练/优化方法定义。那么我们的计算图基本也由这三部分的定义组成。(当然还可能包括其它部分,如输入数据初始化操作,网络参数初始化等等,这里我们不讨论)
- 网络模型定义
这里我们定义一个最简单的单层全连接网络,计算公式为:y=Wx+b,然后利用softmax来计算预测概率,预测概率最大的对应预测的分类。我需要定义两个变量来保存网络参数W和b的状态。

W = tf.Variable( tf.zeros([784,10]) )
b = tf.Variable( tf.zeros([10]) )
y = tf.nn.softmax( tf.matmul(x,W) + b )
- 损失函数定义
采用cross-entropy作为损失函数,它的公式为:$H_{y'}\left(y\right)=-\underset{i}{{\textstyle \sum}}y'{i}\log\left(y{i}\right)$。(才发现简书竟然不支持Latex,尴尬。。。)
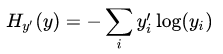
cross_entropy = tf.reduce_mean( -tf.reduce_sum( y_*tf.log(y), reduction_indices=[1] ) )
- 训练/优化方法定义
神经网络常采用SGD(Stochastic Gradient Descent)进行网络的优化训练。tensorflow会自动根据前面定义的计算图进行forward和backward计算并更新参数。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
3.定义会话
按照前面的方法,定义一个session即可。但是还要记住对所有的变量进行全局初始化。
sess = tf.InteractiveSession()
tf.global_variables_initializer().run() #由于是InteractiveSession可以直接run
或者
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run()
4.进行计算
对于神经网络来说,就是要开始迭代进行训练和评估,降低损失函数。
# training
for i in range(10000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run( {x:batch_xs, y_:batch_ys} ) #InteractiveSession
# sess.run(train_step, feed_dict={x:batch_xs, y_:batch_ys}) #非InteractiveSession
# eval
correct_prediction = tf.equal( tf.argmax(y,1), tf.argmax(y_,1) )
accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float32) )
print(accuracy.eval( {x:mnist.test.images, y_:mnist.test.labels} )) #InteractiveSession
print(sess.run(accuracy, feed_dict={x:mnist.test.images, y_:mnist.test.labels})#非InteractiveSession
以上就是整个神经网络的搭建过程。这里只采用的单层全连接网络,但是准确率依然达到了92%左右,如果我们采用卷积神经网络等更复杂的网络,可以将准确率提高到99%。
以上只是搭建一个神经网络的基本框架,当然实际中还是数据预处理、参数初始化、超参数设置等问题,这些就需要在实际使用过程中慢慢学习了。
以下是该网络的全部代码:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
x = tf.placeholder( tf.float32, [None, 784] )
y_ = tf.placeholder( tf.float32, [None, 10] )
W = tf.Variable( tf.zeros([784,10]) )
b = tf.Variable( tf.zeros([10]) )
y = tf.nn.softmax( tf.matmul(x,W) + b )
cross_entropy = tf.reduce_mean( -tf.reduce_sum( y_*tf.log(y), reduction_indices=[1] ) )
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
session = tf.InteractiveSession()
tf.global_variables_initializer().run()
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
train_step.run( {x:batch_xs, y_:batch_ys} )
# print(i)
correct_prediction = tf.equal( tf.argmax(y,1), tf.argmax(y_,1) )
accuracy = tf.reduce_mean( tf.cast(correct_prediction, tf.float32) )
print(accuracy.eval( {x:mnist.test.images, y_:mnist.test.labels} ))
作者:mac在路上
链接:https://www.jianshu.com/p/87581c7082ba
來源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。