监督学习——随机森林
一、随机森林原理
1.如何构建随机森林?
有两个方面:
1.数据的随机性化
2.待选特征的随机化
使得随机森林中的决策树都能够彼此不同,提升系统的多样性,从而提升分类性能。
- 数据的随机性化:使得随机森林中的决策树更普遍化一点,适合更多的场景
(有放回的准确性在:70%以上,无放回的准确率在:60%以上)
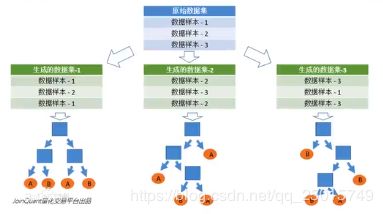
1.采用有放回的抽样方式构建子数据集,保证不同子集之间的数量级一样
2.利用子数据集来构建子决策树,将数据放到每个子决策树中,每个决策树输出一个结果
3.统计子决策树的投票结果,得到最终的分类就是随机森林的输出结果
4.如下图,假设随机森林中有3棵子决策树,2棵子树的分类是A类。1棵子树的分类结果是B类。那么随机森林的分类结果就是A类。
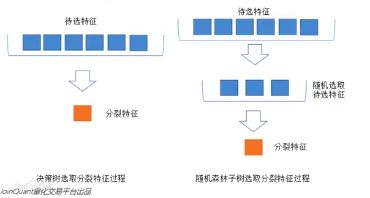
- 待选特征的随机化
1.子树从所有待选特征中随机选取一定的特性
2.在选取的特征中选取最优的特征
左图是一棵决策树的特征选取过程,通过在待选特征中选取最优的分裂特征,完成分裂。
右图是一个随机森林中的子类的特征选取过程。
2.开发流程
收集数据:任何方法
准备数据:转换样本集
分析数据:任何方法
训练算法:通过数据随机化和特征随机化,进行多实例的分类评估
测试算法:计算错误率
使用算法:输入样本数据,然后 进行随机森算法判断输入数据属于哪一类别,最后对计算出的分类执行后续处理
3.算法特点
优点:几乎不需要输入准备,可实现隐式特征选择,训练速度非常快,其他模型很难超越。
缺点:模型大小是个很难去解释的黑盒子。
4. 调参优化:
- n_estimators
森林中数目的数量。n_estimators越大,模型效果越好,但需要的训练时间越长,达到一定成都后,随机森林的精准性往往不再上升或开始波动。
其余参数与决策树相同。
在调参时,可以参考这个顺序:


二、sklearn库实现
症状及方法预测案例:
案例背景:根据用户状态数据和其采用的改善方法,预测其改善效果。即已知P和X,预测Y。
- 用户症状共13个维度,根据各维度属性的不同量化为不同水平的分类变量
- 改善方法共10种,1表示采用,0表示未采用
- 改善效果为分类变量,0变好,1不变,2变差。
实现代码:
**********************************************导入库********************************************************
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV #网格搜索
from sklearn.model_selection import cross_val_score #交叉验证
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
****************************************导入数据集,探索数据**************************************************
path=r'C:\Users\HP\Desktop\data.csv'
data=pd.read_csv(path,encoding='gbk')
**********************************************归一化*********************************************************
max_min_scaler = lambda x : (x-np.min(x))/(np.max(x)-np.min(x))#归一化
data[['症状1','症状2','症状3','症状4','症状5','症状6','症状7','症状8','症状9','症状10','症状11','症状12','症状13']]=\
data[['症状1','症状2','症状3','症状4','症状5','症状6','症状7','症状8','症状9','症状10','症状11','症状12','症状13']].apply(max_min_scaler)
train=data.loc[0:89999,:]#前90000行作为训练集
test=data.loc[90000:100000,:]#测试集
******************************************设置训练集和测试集***************************************************
train_y=train['效果']#训练标签
train_x=train.drop('效果',axis=1)#训练参数
test_y=test['效果']
test_x=test.drop('效果',axis=1)
********************************************随机森林建模预测***************************************************
clf=RandomForestClassifier(n_estimators=100)#定义随机森林
clf.fit(np.array(train_x),np.array(train_y))#训练
result=clf.predict(np.array(test_x))#预测
print('预测病情结果如下')
print(result)#输出结果
accurate=(result==test_y)#输出结果与应有的效果比较,True代表一样,False代表不一样
print(accurate.value_counts())
#结果:
预测病情结果如下
[1 1 0 ... 1 0 1]
True 5878
False 4122
Name: 效果, dtype: int64
*******************************************学习曲线调参n_estimators*********************************************
scorel = []#十次交叉验证的均值
for i in range(0,200,10):
clf = RandomForestClassifier(n_estimators=i+1,
n_jobs=-1,
random_state=90)
score = cross_val_score(clf,test_x,test_y,cv=10).mean()
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)#打印十次交叉的均值和索引
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
#结果:
0.5891211820243883 131
学习曲线如图1, n_estimators取131
***********************************************进一步细化学习曲线***********************************************
scorel = []#十次交叉验证的均值
for i in range(35,45):
clf = RandomForestClassifier(n_estimators=i,
n_jobs=-1,
random_state=90)
score = cross_val_score(clf,test_x,test_y,cv=10).mean()
scorel.append(score)
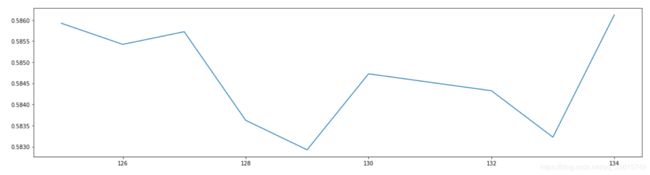
print(max(scorel),([*range(125,135)][scorel.index(max(scorel))]))#打印十次交叉的均值和索引
plt.figure(figsize=[20,5])
plt.plot(range(125,135),scorel)
plt.show()
#结果:
0.5861234791260843 134
学习曲线如图2,n_estimators取134
***********************************************网格搜索,调整max_depth*****************************************
param_grid = {'max_depth':np.arange(1,20,1)}
clf = RandomForestClassifier(n_estimators=134
,random_state=90
)
GS = GridSearchCV(clf,param_grid,cv=10)
GS.fit(test_x,test_y)
GS.best_params_
GS.best_score_
#结果:
{'max_depth': 8}
0.6154
*********************************************网格搜索,调整min_samples_leaf************************************
param_grid = {'min_samples_leaf':np.arange(1,20,1)}
clf = RandomForestClassifier(n_estimators=134
,max_depth=8
,random_state=90
)
GS = GridSearchCV(clf,param_grid,cv=10)
GS.fit(test_x,test_y)
GS.best_params_
GS.best_score_
#结果:
{'min_samples_leaf': 5}
0.6161
*********************************************网格搜索,调整min_samples_split************************************
param_grid = {'min_samples_split':np.arange(2,20,1)}
clf = RandomForestClassifier(n_estimators=134
,max_depth=8
,min_samples_leaf=5
,random_state=90
)
GS = GridSearchCV(clf,param_grid,cv=10)
GS.fit(test_x,test_y)
GS.best_params_
GS.best_score_
#结果:
{'min_samples_split': 2}
0.6161
***************************************************网格搜索,调整max_features*************************************
param_grid = {'max_features':np.arange(1,20,1)}
clf = RandomForestClassifier(n_estimators=134
,max_depth=8
,min_samples_leaf=5
,random_state=90
GS = GridSearchCV(clf,param_grid,cv=10)
GS.fit(test_x,test_y)
GS.best_params_
GS.best_score_
#结果:
{'max_features': 4}
0.6161
*****************************************************网格搜索,调整criterion***************************************
param_grid = {'criterion':['gini','entropy']}
clf = RandomForestClassifier(n_estimators=134
,max_depth=8
,min_samples_leaf=5
,random_state=90
)
GS = GridSearchCV(clf,param_grid,cv=10)
GS.fit(test_x,test_y)
GS.best_score_
#结果:
0.6152(下降了)
图1: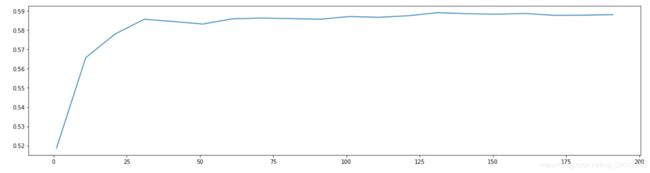
图2: