scala项目开发知识储备
Scala项目预备
本文档写的很详细。因为工程量浩大,内容会涉及超级多的引用。本文档前部分详细描述基础知识,最后将引入实际需求应用。
来说说为什么用scala
- 我看spark源码,由scala开发,非常的优雅、简洁,是一个伟大而令人兴奋的语言。
- 一定程度上替代java开发,仅仅是一定程度上,任然有许多场景非java不可。请注意我的措辞,在一定场景中,scala开发比java来的快捷方便。
- 函数式编程妙不可言,只有真的使用过后才会爱不释手。个人感觉就是,爽到无法呼吸的爱上她。
怎么用
关于怎么搭建,很简单。请看这篇文章,我不废话。
https://blog.csdn.net/zkq_1986/article/details/78951793
遇到搭建环境的小坑
写到这就得说道说道了。这两个小问题是当时第一次整遇到了,后面解决了,并做告知,提醒后来人。
- 没有new scala
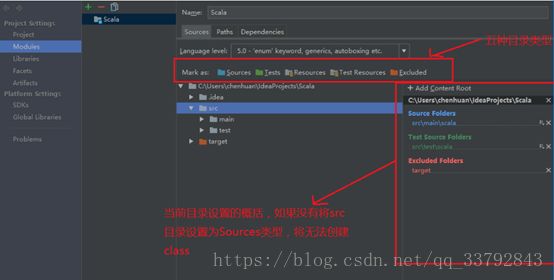
备注:src为sources
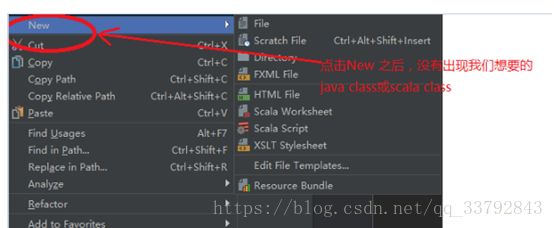
打开设置界面的路径如下: 主界面File——>Project Structure——>modules

- 如上图红圈所示,我们可以根据对项目的任意目录进行这五种目录类型标注,这个知识点非常非常重要,必须会。
- Sources 一般用于标注类似 src 这种可编译目录。有时候我们不单单项目的 src 目录要可编译,还有其他一些特别的目录也许我们也要作为可编译的目录,就需要对该目录进行此标注。只有 Sources 这种可编译目录才可以新建 Java 类和包,这一点需要牢记。
- Tests 一般用于标注可编译的单元测试目录。在规范的 maven 项目结构中,顶级目录是 src,maven 的 src 我们是不会设置为 Sources 的,而是在其子目录 main 目录下的 java 目录,我们会设置为 Sources。而单元测试的目录是 src - test - java,这里的 java 目录我们就会设置为 Tests,表示该目录是作为可编译的单元测试目录。一般这个和后面几个我们都是在 maven 项目下进行配置的,但是我这里还是会先说说。从这一点我们也可以看出 IntelliJ IDEA 对 maven 项目的支持是比彻底的。
- Resources 一般用于标注资源文件目录。在 maven 项目下,资源目录是单独划分出来的,其目录为:src - main -resources,这里的 resources 目录我们就会设置为 Resources,表示该目录是作为资源目录。资源目录下的文件是会被编译到输出目录下的。
- Test Resources 一般用于标注单元测试的资源文件目录。在 maven 项目下,单元测试的资源目录是单独划分出来的,其目录为:src - test -resources,这里的 resources 目录我们就会设置为 Test Resources,表示该目录是作为单元测试的资源目录。资源目录下的文件是会被编译到输出目录下的。
- Excluded 一般用于标注排除目录。被排除的目录不会被 IntelliJ IDEA 创建索引,相当于被 IntelliJ IDEA 废弃,该目录下的代码文件是不具备代码检查和智能提示等常规代码功能。
通过上面的介绍,我们知道对于非 maven 项目我们只要会设置 src 即可。如上图箭头所示,被标注的目录会在右侧有一个总的概括。其中 classes 虽然是 Excluded 目录,但是它有特殊性,可以不显示在这里。
然后就有了。
- 没有run as scala
备注:没有建立object
文件建错了,应该建一个object而不是建一个class。
基本数据结构
这里有一篇详细的不能再详细的了
https://blog.csdn.net/huanghuitan/article/details/69681184
或者可以和我一样,整本书过一过,作为工具书。
来研究一下scala强大的集合
时间关系。
Scala集合类详解:
https://blog.csdn.net/bitcarmanlee/article/details/72795013
https://blog.csdn.net/a2011480169/article/details/53421009
这里说一下,用的最多的还是mutable.ListBuffer,mutable.HashMap了
这里拓展一下集合排序的知识。
https://www.jianshu.com/p/77b288e54f7d
scala集合转换操作:
https://blog.csdn.net/wodatoucai/article/details/51544429
了解一下集合常用api,sortBy、foreach、map、flatMap、reduce操作
来研究dataframe
前段时间做了python数据集的需求,熟悉python的pandas、numpy类库,再来理解scala的dataframe会熟悉很多。
也不是很想扯,可以参看以下简书内容,写的很详细
https://www.jianshu.com/p/8ac9778eb4bd
可惜的是,scala、java没有直接的类库来操作dataframe,除了引入spark环境之外,dataframe类库目前也没有找到,只有一个朋友在git上面分享了一部分dataframe的功能的源码,所以说,这点python也是强大到没有朋友。
参看上述博文,你会发现,dataframe操作,极大地提高了编程效率,有多极大呢,开发三天的东西,dataframe两三行代码就能搞定。
准备poi的知识
不用多说哦,看下就好啦。
http://poi.apache.org/
关于poi的话,poi-ooxml听说是进阶版,在大数据量的excel读取会效率更加高。也不用听说了,就决定了,用ooxml了,我使用版本3.17
当然在网上找到的关于poi画出来的cell美化的内容也需要理解一番,也是我们程序v1.1的内容。
所以总结一下吧,用poi-ooxml原因有二,他是poi的升级版本;处理量更加大。
同时在普及一个知识,XSSFWorkbook是2007版本,HSSFWorkbook是2003版本,前者是xlsx后缀,后者是xls后缀,生成文件时不要搞错了哦。
因为这里遇到过一个小问题。
问题
在使用poi-3.15-beta2版本解析excel时, 发现并有网友所说的WorkbookFactory类.
原因
从poi-3.7.jar开始, WorkbookFactory类已经放进poi-ooxml-XXX.jar中了.
解决方法
同时引入这两个jar包: poi-3.15-beta2.jar, poi-ooxml-3.15-beta2.jar
Sbt原理以及应用
好了,讲讲sbt吧,可能我们接触maven较多,那么之前我也是一直使用maven,构建maven项目。
groupid和artifactId被统称为“坐标”是为了保证项目唯一性而提出的,如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。
groupId一般分为多个段,这里我只说两段,第一段为域,第二段为公司名称。域又分为org、com、cn等等许多,其中org为非营利组织,com为商业组织。举个apache公司的tomcat项目例子:这个项目的groupId是org.apache,它的域是org(因为tomcat是非营利项目),公司名称是apache,artigactId是tomcat。
比如我创建一个项目,我一般会将groupId设置为cn.snowin,cn表示域为中国,snowin是我个人姓名缩写,artifactId设置为testProj,表示你这个项目的名称是testProj,依照这个设置,你的包结构最好是cn.snowin.testProj打头的,如果有个StudentDao,它的全路径就是cn.snowin.testProj.dao.StudentDao

定义好了即可使用。
但是!本次,不想使用maven,就用sbt,虽然吐槽一下构建实在是慢,龟速吧。
先来举个例子吧,在build.sbt中
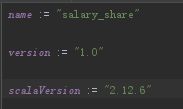
然后注意依赖规则:
libraryDependencies += groupId % revision % configuration
截图举例:

如果还是不清楚不理解的,可以看这篇博文:
https://www.cnblogs.com/shijiaqi1066/p/5103735.html
会告知怎么整合。
都说到这里了,那接着来说一下sbt构建时,jar冲突吧。以下博文图文并茂的告知了,idea中如何添加依赖以及移除冲突依赖哦。
https://blog.csdn.net/qq_39707130/article/details/81431136
关于日志
Scala 日志操作
https://www.jianshu.com/p/64b3f5ad3d9b
https://blog.csdn.net/duguxiaobiao/article/details/78988409
将日志输出至日志文件
关于打包
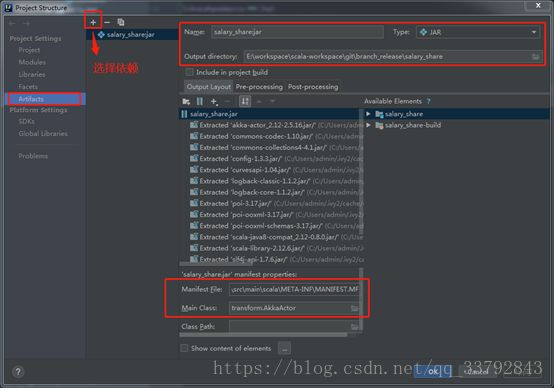
打成jar后打exe可执行程序。

注意选好Main class
再说一个很不错的文档:
https://blog.csdn.net/qq_20473985/article/details/53186216
基本上就可以搞定jar变身exe了。nice
关于akka
说道akka的并发编程,在2.11的scala中,actor到akka这里来了,同时呢,要知道akka的入口actorSystem的原理和操作。
如下我放至博文,需要的可以仔细研究一下。
值得一提的是,我在研读spark核心源码时,看到sparkContext的初始化时,就有akka的actor消息系统实现并发编程。
多啰嗦几句,scala认为java的并发线程存在锁争用、并发性能低、容易引入死锁。
有关于akka并发编程有一下博文:
akka使用
https://blog.csdn.net/zhaodedong/article/details/73441303
https://www.2cto.com/kf/201611/566954.html
scala线程安全避免死锁 akka实现
https://blog.csdn.net/cjuexuan/article/details/50447627
https://blog.csdn.net/lovehuangjiaju/article/details/51045146
akka官方的一张图

实际项目,请看我的下一篇博文。
https://blog.csdn.net/qq_33792843/article/details/82735908