NLP(自然语言处理):Representation Degeneration 表达退化
目录
- 前言
- 0. 摘要(Abstract)
- 1. 引言(Introduction)
- 2. 相关工作(Related Work)
- 3. 表达退化问题(Representation Degeneration Problem)
- 3.1 实验设计(Expermental Design)
- 3.2 实验讨论(Discussion)
- 4 理解问题(Understanding the problem)
- 4.1 极端情况:从未出现的词(Extreme Case: Non-Appeared Word Tokens)
- 4.2 对生僻词的延展(Extension to Rarely Appeared Word Tokens)
- 5 解决问题(Addressing the Problem)
- 6 实验(Experiment)
- 6.1 语言模型/机器翻译 (Language Model/ Machine Translation)
- 6.2 实验结果(Experiment Result)
- 6.4 结果讨论(Discussion)
- 7 总结与展望(Conclusion and Future Work)
前言
表达退化问题是由多伦多、微软、北大的Jun Gao et al. 共同在2019年的ICLR大会上提出的问题,其主旨在训练神经网络时出现的词向量表达退化的问题。本篇文章基于其发表的论文 Representation Degeneration Problem in Training Natural Language Generation Models. 本文旨在翻译文章。
0. 摘要(Abstract)
本文研究了一个存在于基于神经网络的语言生成任务中的问题,我们将它称作 表达退化 (Representation Degeneration)问题。我们发现,在通过最大似然和权重绑定(Weight tying)的方法训练一个基于神经网络的语言生成模型时,尤其是在大型训练集时,大多数学习得到的词嵌入会趋向于退化,并分布于一个狭窄的锥形区域内,这样的分布会很大程度上限制词嵌的表达能力。我们分析了这种问题出现的条件和出现的时间,并提出了一个新型的正则化方法来解决这个问题。在语言模型和机器翻译的实验表明,这种方法可以有效缓解表达退化问题,并且在对照组上获得更好的表现。
1. 引言(Introduction)
基于神经网络的算法在语言生成任务上取得了重大的突破,这其中包括语言模型,机器翻译和对话系统等方面的研究。虽然在应用和模型结构上,各个语言生成模型各不相同,但大多数模型还是依赖于 使用前序上下文信息和其他条件信息对下一个词进行预测 的思想。一种标准的方法是使用深度神经网络,把输入文本编码为固定维的向量,我们通常称这些向量为隐藏层(Hidden state),这些隐藏层最后会和词嵌入矩阵相乘,获得最终的Logits(在权重绑定的情况下,输入词嵌矩阵 = 输出词嵌矩阵)。其Logits会输入Softmax层,生成对于下一个预测此的分类分布。最终模型会通过最大似然训练。(PS:Logits本身为Log(P/(1-P)), 在此处可以理解为未归一化的概率)
当对模型在语言生成任务上训练时,我们发现了一些有趣且奇怪的现象。在前我们介绍了权重绑定,即当输入词嵌与输出词嵌共享时,词嵌入矩阵此时有双重作用 ,它既是输入的第一层,也是输出权重的最后一层。
- 输入第一层:当其位于输入的第一层时,我们希望词嵌入矩阵包含丰富的语义信息并且能够捕捉当前词的上下文信息,以在不同任务中进一步使用。
- 输出最后一层:当其用于输出最后一层,生成Logits的时候,我们需要其拥有足够的能力对不同隐藏层信息进行分类,并获得分类后的标签。
此时,我们对权重绑定的情况(图1(a))与不绑定的情况进行对比(图1), 图(b)为Word2Vec的方法训练的输入词向量,而图(c)为经典分类模型训练出的输出词向量,图片都是经过了SVD分解之后的结果。 
从图中,我们不难看出,后两个方法获得的词向量分布都十分离散,而第一个方法的词向量(由Transformer原型得到)并不理想,而是呈现锥形分布。进一步而言,在Transformer的词向量中,我们发现任意两个词向量都正向相关(Positively correlated)。这样的词向量在两个位置都十分不利:
- 输出端:生成的Logits并不能产生较大的预测边际,以获得较好的泛化性。
- 输入端:并没有足够的能力对分散的语义进行建模。
对于这样的问题,我们称其为表达退化(representation degeneration problem)。本文即是对此问题的理解和探究。对于此问题,本为提出了一些直觉上的解释和理论验证。
直觉上来说,在通过最大似然损失训练模型的过程中,对任意的隐藏层来说,其对应真值词的词嵌入都会被向前训练(push forward towards the direction of the hidden state),以取得一个更大的似然值,同时,其他所有词将会被向后推进(或说负向推进),以获得一个更小的似然值。而在自然语言模型的训练中,越大的语料库中每个词的词频通常越小,这就会使大多数隐藏层向各个负方向训练。而这样导致的结果是词表中,大多数词嵌都会向一个相同的方向负向更新,因此,词嵌空间中,我们会看到大量的词汇聚集成簇。
当然,直觉的推断并不可靠,理论上来说,首先我们对一些极端情况进行了分析:从未出现的词。我们证明了表达退化问题与隐藏层的结构息息相关:退化现象通常出现于隐藏层的凸包(Convex Hull)不包含坐标原点时,而这种情况在使用layer normalization时更易出现。所以,我们对低频词汇的优化过程做了进一步实际性研究。研究表明,在温和条件下,低频词更容易被训练得彼此相近,因此分布在一个集中的区域里。
受经验上的分析和理论启发,我们设计了一种新型结构,可以通过对词嵌入矩阵的正则化缓解退化问题。如我们所观察到的结果表示,词嵌都集中在一个狭窄的锥形区域,我们尝试通过减小词之间的相似性,以增大扩大锥形的顶点区域(aperture of the cone)。我们通过两个任务验证了此方法的有效性:语言模型和机器翻译。实验结果表示表达退化问题被缓解,且这种方法在对照组模型之上取得了更好的结果。
2. 相关工作(Related Work)
这部分内容关于机器翻译,语言模型和权重绑定,可以自行了解。
*此部分重新表述了表达退化问题,可跳过
3. 表达退化问题(Representation Degeneration Problem)
这一部分内容对基于时序生成任务的词嵌入进行了探究。
3.1 实验设计(Expermental Design)
这部分中我们实验的模型是基于SOTA(state-of-the-art)模型进行的分析,选取机器翻译模型,Transformer。我们使用了Transformer的官方代码和默认参数进行了实验,在训练模型上,我们在WMT2014 英-德数据集中取得了BLEU27.3的分数。此外,我们也分析了基于LSTM的模型,并且发现了这些观察的相似之处。
在自然时序信号生成任务上,词嵌入矩阵和sofrmax层的参数是绑定的。这些参数不仅可以被看作是第一层的输入,同时也是输出前的最后一层。因此,我们对比了这些 权重矩阵 与 传统的通过表达训练的词嵌矩阵的不同之处,同时也和传统Softmax前层训练得到的矩阵 进行比较。考虑到相似性与代表性,我们分别选取了Mikolov的经典Word2Vec模型和MNIST数据集经过两层卷积神经网络后的分类矩阵作为对照组。在分类任务上,我们简单的将最后一层的参数矩阵的行(最后一层全连接层)认为是分类矩阵,就如同使用权重捆绑时,词嵌在softmax层中的使用方法一样。
为了获得一个更明确的结果,这里我们对学习到的矩阵使用低秩矩阵近似(秩=2),通过SVD分解得到近似矩阵,并将他们呈现在平面上进行可视化(如图一所示)。我们同时检查了奇异值的分布,并且发现我们构造的低秩矩阵相当合理:未选中的奇异值要远小于选中的奇异值。
3.2 实验讨论(Discussion)
在分类任务中,Softmax前层的类别矩阵(图1(c))距离原点分布得十分离散。这说明分类矩阵的各个方向都各不相同,且分隔的很好,因此能导致较大的分类间隔区域,具备很好的泛化性。而对于Word2Vec中学习得到的词嵌矩阵,其原理与上近似。在投影区域中,词嵌仍旧距圆点平坦的分布,这种分布可以表征出不同词的不同语义信息。对GLOVE的观察也同样展现出相同的特征。
可我们在机器翻译模型上观察到了截然不同的现象。从图1(a)中可以看出,词嵌矩阵聚集在一起,且形成了一个狭窄的锥形区域。进一步来说,我们发现词嵌之间的余弦相似性几乎都呈正相关。这说明词嵌挤在了一起,并且没有在词嵌空间中很好的离散分布。
显然,作为词嵌来讲,其是神经网络的输出,它应该具有离散分布的特征,以代表不同的语义信息;作为softmax前的分类矩阵来说,其应该具有更加离散的分布,以在分类中获得更大的分类间隔,在目标句子中更好的锁定下一个目标词。然而现在Transformer的词表征,从分布上来看,限制了训练模型的表达能力。我们称这样的问题为表达退化问题 (Representation degeneration problem)。
4 理解问题(Understanding the problem)
通过前文章节,我们展示了在训练自然语言模型过程中,训练得到的词嵌矩阵会聚集成一个窄锥形,造成模型陷入表达瓶颈的问题。此节中,我们将尝试理解这些问题产生的原因,并且证明它的出现与低频词汇在分散上下文中的优化过程有关。
在自然语言生成任务中,词表的维度通常都很大,通过齐夫定律,我们可以得知每个词的词频都相当低。举例来说,在WMT 2014 英德数据集中,超过 90% 的词的词频都小于 0.01% 。即使是一个低频词,其词频也会相应变低。一个更具体的例子来源于对语料库中个别词的分析:“is” 的词频在整个语料库中有1%,因为几乎每个单独句子中都会出现 “is”。我们的分析主要集中在低频词的优化模型,注意,低频词代表了大多数语料库中的词。
时序词序列的生成模型通常表示为:
y = ( y 1 , y 2 , . . . , y M ) , y = (y_1, y_2, ..., y_M), y=(y1,y2,...,yM),
它可以等价于词语从左到右依次产生的过程。此时,生成序列 y 的概率可以通过条件概率链式法则分解为:
P ( Y = y ) = ∏ t P ( Y t = y t ∣ Y < t = y < t ) , P(Y = y) = \prod_{t}P(Y_t=y_t|Y_{
其中 y < t y_{
在一个由M个采样的多分类问题(M为目标序列的长度)中,令 h i h_i hi表示softmax层前的隐藏层,它同时可以被看作 i = 1 , 2 , . . . , M i=1, 2, ..., M i=1,2,...,M的输入特征。在没有损失泛化性的情况下,我们假设 h i h_i hi是一个非零向量。令 N N N表示为词表大小, y i ∈ { 1 , . . . , N } y_i\in\{1, ..., N\} yi∈{1,...,N}的条件概率可以通过softmax方程进行计算:
P ( Y i = y i ∣ h i ) = e x p ( < h i , w y i > ) ∑ l = 1 N e x p ( < h i , w l > ) , P(Y_i=y_i|h_i)=\frac{exp(
其中 w l w_l wl代表了词嵌矩阵(视为分类问题时,类别为 l , l = 1 , 2 , . . . , N l, l=1, 2, ..., N l,l=1,2,...,N)。
4.1 极端情况:从未出现的词(Extreme Case: Non-Appeared Word Tokens)
注意到,在NLP任务中,生僻词的词频比一般词更低,而这样的词并不在少数。在随机训练模型中,将某一个生僻词采样进入训练需要的mini-batch的概率是极低的,因此,在优化过程中,这些生僻词会表现出与从 未出现过的词 一样的相似性(因为几乎不会被训练到)。所以我们首先考虑这样一种极端情况,分析从未出现过的词,进而在下一节中延展出一个更普适,现实的场景。
我们假设,对所有i,有 y i ≠ N y_i \not= N yi=N。也就是说,第词嵌矩阵中,第N个词(词嵌为 w N w_N wN)从未出现在语料库中。这也就是我们所说的生僻词的极限情况。我们来关注词嵌 w N w_N wN的优化情况,并且假设所有其他的参数都已经固定,且优化完成了。那么在最大似然下,我们有:
max w N 1 M ∑ i = 1 M l o g e x p ( ⟨ h i , w y i ⟩ ) ∑ i = 1 N e x p ( ⟨ h i , w l ⟩ ) . (1) \displaystyle\max_{w_N}\frac{1}{M}\sum_{i=1}^M log\frac{exp(\langle h_i, w_{y_i}\rangle)}{\sum_{i=1}^Nexp(\langle h_i, w_l\rangle)}. \tag{1} wNmaxM1i=1∑Mlog∑i=1Nexp(⟨hi,wl⟩)exp(⟨hi,wyi⟩).(1)
解释:这里对每一个输入我们都想要正确答案的似然最大,由于其他参数固定,我们只训练 w N w_N wN这一个参数。
由于所有其他参数都已经固定了,则等价于:
min w N 1 N ∑ i = 1 M l o g ( e x p ( ⟨ h i , w N ⟩ ) + C i ) , (2) \displaystyle\min_{w_N}\frac{1}{N}\sum_{i=1}^Mlog(exp(\langle h_i, w_N\rangle) + C_i),\tag{2} wNminN1i=1∑Mlog(exp(⟨hi,wN⟩)+Ci),(2)
解释:这里对同上一样,由于其他参数固定,而 w N w_N wN又从未出现过,故我们希望其对任意标签的似然都取最小。
其中 C i = ∑ l = 1 N − 1 e x p ( < h i , w l > ) C_i=\sum_{l=1}^{N-1}exp(
定义 1 向量 v v v 是 h i , i = 1 , 2 , . . . , M , i f ⟨ v , h i ⟩ < 0 h_i, i=1, 2, ..., M, if\langle v, h_i\rangle < 0 hi,i=1,2,...,M,if⟨v,hi⟩<0 的单位负向量。
下面的定理为词嵌 w N w_N wN在优化中逼近无穷提供了一个充分条件。
定理 1
A.如果负单位向量的集合不为空,则其为凸型。
B. 如果存在一个 v v v为 h i h_i hi的单位负向量,则公式(2)的优化解应满足 ∣ ∣ w N ∗ ∣ ∣ = ∞ ||w_N^*||=\infty ∣∣wN∗∣∣=∞,其满足条件为 w N ∗ = l i m k → + ∞ k ⋅ v w_N^*=lim_{k \rightarrow+\infty}k\cdot v wN∗=limk→+∞k⋅v。
从以上定理,我们可以看出,如果存在一组单位负向量,则词嵌 w N w_N wN会在优化过程中向任意一个负向量优化至无穷。当单位负向量的集合是凸型时, w N w_N wN可以很有可能就落在了凸性的锥形区域,并且在优化的过程中向无穷迭代。接下来,我们提出了一组充要条件,以证明单位负向量的存在。
定理 2
当且仅当凸包的隐藏层不包含原点时,存在 v v v为隐层的单位负向量。
实现过程中条件成立的讨论:从以上定理可知,隐层的向量结构与是否存在单位负向量紧密相关,随即影响了词嵌的优化。注意到,我们在训练神经网络时有一个常用的技巧,是 layer normalization,这种归一化方法会将每个隐层向量归一化为一个标准向量(均值和方差符合标准正态分布),然后再进行尺度/偏置变化。在附录中,我们展示了在不同的温和条件下(mild conditions),隐层几乎都不会包含原点。
4.2 对生僻词的延展(Extension to Rarely Appeared Word Tokens)
在上一节中,我们展示了,在可靠假设下,词嵌向量中所有未出现词都会向单位负向量的方向优化至无穷。但是,在L2正则化约束下,词嵌权重趋于无穷是不现实的,同时未出现词也是十分极端的假设。在这一节中,我们将会把上节的分析延展至更实际的应用中。我们想知道的关键在于生僻词的优化过程是否与未出现词相似。沿用上述的符号表示,我们令 w N w_N wN代表生僻词的词嵌,并且固定其他参数。我们通过负指数似然损失 (Negative log-likelihood loss function)对这一输入的优化进行了研究。
为了更好的表征 w N w_N wN在损失函数里的特性,我们将损失函数分为了两部分。第一部分为 A w N A_{w_N} AwN,它表示了不包含生僻词的句子,即所有句子的隐层都与 w N w_N wN相互独立,且这些词的真实标签( w h ∗ w_h^* wh∗)都不是 w N w_N wN。 这样一来,我们可以在 A w N A_{w_N} AwN中将生僻词看作未出现词。我们可以将其中隐藏层张成的向量空间表示为 H A w N \mathcal{H}_{A_{w_N}} HAwN,其概率分布为 P A w N P_{A_{w_N}} PAwN,而这两个参数都是连续的。则在 A w N A_{w_N} AwN段的损失函数:
L A w N ( w N ) = − ∫ H A w N l o g e x p ( ⟨ h , w h ∗ ⟩ ) ∑ l = 1 N e x p ( ⟨ h , w l ⟩ ) d P A w N ( h ) , (3) L_{A_{w_N}}(w_N) = - \int_{\mathcal{H}_{A_{w_N}}}{log\frac{exp(\langle h, w_h^*\rangle)}{\sum_{l=1}^Nexp(\langle h, w_l\rangle)}}dP_{A_{w_N}}(h) , \tag3 LAwN(wN)=−∫HAwNlog∑l=1Nexp(⟨h,wl⟩)exp(⟨h,wh∗⟩)dPAwN(h),(3)
可由式(1)得出此式。而 B w N B_{w_N} BwN段表示了包含生僻词的句子,即 w N w_N wN在 B w N B_{w_N} BwN段的每一句中都曾出现。接着,在 B w N B_{w_N} BwN段中,隐层的计算某些是基于 w N w_N wN的,即当隐层用于预测 w N w_N wN的下一个词时。在其他情况中,也存在隐层被用作预测 w N w_N wN的情况。我们可以将其中隐藏层张成的向量空间表示为 H B w N \mathcal{H}_{B_{w_N}} HBwN,其概率分布为 P B w N P_{B_{w_N}} PBwN,而这两个参数都是连续的。则在
B w N B_{w_N} BwN段的损失函数:
L B w N ( w N ) = − ∫ H B w N l o g e x p ( ⟨ h , w h ∗ ⟩ ) ∑ l = 1 N e x p ( ⟨ h , w l ⟩ ) d P B w N ( h ) , (4) L_{B_{w_N}}(w_N) = - \int_{\mathcal{H}_{B_{w_N}}}{log\frac{exp(\langle h, w_h^*\rangle)}{\sum_{l=1}^Nexp(\langle h, w_l\rangle)}}dP_{B_{w_N}}(h) , \tag4 LBwN(wN)=−∫HBwNlog∑l=1Nexp(⟨h,wl⟩)exp(⟨h,wh∗⟩)dPBwN(h),(4)
基于这种表示而言,我们可以将整体的损失函数定义为:
L ( w N ) = P ( s e n t e n c e s i n A w N ) L A w N ( w N ) + P ( s e n t e n c e s i n B w N ) L B w N ( w N ) . (5) L(w_N) = P(sentence\ s\ in\ A_{w_N})L_{A_{w_N}}(w_N) + P(sentence\ s\ in\ B_{w_N})L_{B_{w_N}}(w_N). \tag5 L(wN)=P(sentence s in AwN)LAwN(wN)+P(sentence s in BwN)LBwN(wN).(5)
其中损失函数中 A w N A_{w_N} AwN段是凸型的,而 B w N B_{w_N} BwN段较为复杂,通常是非凸的。处理这个损失函数的通常想法是根据 L A w N ( w N ) L_{A_{w_N}}(w_N) LAwN(wN)的凸方程性质,如果 P ( s e n t e n c e s i n A w N ) P(sentence\ s\ in\ A_{w_N}) P(sentence s in AwN)足够大,即大于 1 − ϵ 1-\epsilon 1−ϵ,而 L B w N ( w N ) L_{B_{w_N}}(w_N) LBwN(wN)是一个有边界的光滑方程。对 L ( w N ) L(w_N) L(wN)的优化可以近似看作对 L A w N ( w N ) L_{A_{w_N}}(w_N) LAwN(wN)的解(此解在明显凸型的情况下可以是唯一解)。以下定理给出了更详细的解释。
定理 3
给定一个 α \alpha α级凸函数 f ( x ) f(x) f(x)和函数 g ( x ) g(x) g(x)满足其海森矩阵(Hessian Matrix) H ( g ( x ) ) ≻ − β I H(g(x)) \succ -\beta I H(g(x))≻−βI, 其中 I I I表示单位矩阵, ∣ g ( x ) ∣ < B |g(x)| < B ∣g(x)∣<B。对给定的 ϵ > 0 \epsilon > 0 ϵ>0, 令 x ∗ , x ϵ ∗ x^*, x_\epsilon^* x∗,xϵ∗分别表示 f ( x ) , ( 1 − ϵ ) f ( x ) + ϵ g ( x ) f(x), (1-\epsilon)f(x) + \epsilon g(x) f(x),(1−ϵ)f(x)+ϵg(x)的最佳优化解。则如果 ϵ < α α + β \epsilon < \frac{\alpha}{\alpha + \beta} ϵ<α+βα,则 ∣ ∣ x ∗ − x ϵ ∗ ∣ ∣ 2 2 ≤ 4 ϵ B α − ϵ ( α + β ) ||x^* - x_\epsilon^*||_2^2 \leq \frac{4\epsilon B}{\alpha - \epsilon(\alpha + \beta)} ∣∣x∗−xϵ∗∣∣22≤α−ϵ(α+β)4ϵB。
我们对这个定理的结果做了更深入的讨论。在自然语言生成问题中,对两个低频词汇 w , w ′ w, w' w,w′来说,其对应的 A w , A w ′ A_{w}, A_{w'} Aw,Aw′段会很大程度重叠。接着,其对应的损失函数 L A w ( w ) , L A w ′ ( w ′ ) L_{A_{w}}(w), L_{A_{w'}}(w') LAw(w),LAw′(w′)十分相似,并有相近的最优解。由上讨论,训练得到的词嵌矩阵 w , w ′ w, w' w,w′很可能彼此相似,这也与经验分析相符合。
5 解决问题(Addressing the Problem)
在这一节中,我们提出了一种算法用于解决表达退化问题。在之前的章节中,训练得到的词嵌矩阵在欧氏空间中分布陷入了一个窄锥形区域,限制了其表达能力。在这种情况中,一种非常直白的解决方式就是提升锥形区域的顶点部分,即放大锥形顶点处,由两条边界构成的角度。为了简化优化过程,我们通过减小两词之间的余弦相似性以提升词嵌的表达能力。
我们仍然通过与上节相似的定义,令方向向量 w w w的归一化向量为 w ^ \hat w w^,即 w ^ = w ∣ ∣ w ∣ ∣ \hat w = \frac{w}{||w||} w^=∣∣w∣∣w。接着,我们的目标就变成最小化 ∑ i ∑ j ≠ i w ^ i T w ^ j \sum_i \sum_{j \not= i} \hat w_i^T \hat w_j ∑i∑j=iw^iTw^j,和前述的损失方程。通过引入超参数 γ \gamma γ 来进行log似然损失与正则项之间的权衡,则最终我们的整体目标函数为:
L = L M L E + γ 1 N 2 ∑ i N ∑ j ≠ i N w ^ i T w ^ j . (6) L = L_{MLE} + \gamma \frac{1}{N^2}\sum_i^N\sum_{j \not= i}^N \hat w_i^T \hat w_j. \tag6 L=LMLE+γN21i∑Nj=i∑Nw^iTw^j.(6)
我们将更新后的损失函数称为MLE with Cosine Regularization (MLE-CosReg),之后,我们会对这个正则项做出进一步解释:
如果我们令正则项为 R = ∑ i ∑ j ≠ i w ^ i T w ^ j R = \sum_i \sum_{j \not= i} \hat w_i^T \hat w_j R=∑i∑j=iw^iTw^j,令归一化后的词嵌矩阵为 W ^ = [ w ^ 1 , w ^ 2 , . . . , w ^ N ] T \hat W = [\hat w_1, \hat w_2, ..., \hat w_N]^T W^=[w^1,w^2,...,w^N]T。 则可以将正则化的矩阵形式表达为: R = ∑ i N ∑ j ≠ i N w ^ i T w ^ j = ∑ i N ∑ j N w ^ i T w ^ j − ∑ i N ∣ ∣ w ^ ∣ ∣ 2 = S u m ( W ^ W ^ T ) − N R = \sum_i^N\sum_{j \not=i}^N \hat w_i^T\hat w_j = \sum_i^N\sum_j^N \hat w_i^T \hat w_j - \sum_i^N||\hat w||^2 = Sum(\hat W\hat W^T) - N R=∑iN∑j=iNw^iTw^j=∑iN∑jNw^iTw^j−∑iN∣∣w^∣∣2=Sum(W^W^T)−N,其中 Sum(·)操作计算了矩阵中所有元素。由于N是一个常数,所以我们可以只关注第一项 S u m ( W ^ W ^ T ) Sum(\hat W\hat W^T) Sum(W^W^T)。
而由于 W ^ W ^ T \hat W\hat W^T W^W^T是一个正定矩阵,其所有的特征值都是非负的。考虑到 w ^ i \hat w_i w^i是归一化向量,则矩阵 W ^ W ^ T \hat W\hat W^T W^W^T的对角线上每一个元素都是1。则 W ^ W ^ T \hat W\hat W^T W^W^T的迹(矩阵的迹为其主对角线元素之和)为N。
由于词嵌的余弦相似性均为正值。根据定理 4,当 W ^ W ^ T \hat W\hat W^T W^W^T是一个正矩阵,我们可由 S u m ( W ^ W ^ T ) Sum(\hat W\hat W^T) Sum(W^W^T),得知其最大绝对特征值的上限。那么最小化 R R R就等价于最小化最大特征值的上限。又由于所有的特征值之和为一个常数,我们最小化最大绝对特征值的上限,就导致了其他特征值的增大,因此提升了词嵌矩阵的表达能力。
定理 4
(Merikoski, 1984) 对任意矩阵 A 为实数非负的 n × n矩阵,其谱半径 (Spectral radius),即矩阵 A 的最大绝对特征值小于等于 Sum(A)。
6 实验(Experiment)
6.1 语言模型/机器翻译 (Language Model/ Machine Translation)
这两部分包括了本模型在实验中的设置,可以查阅原文,不做额外解释。只放上关于词嵌结果的一张图:
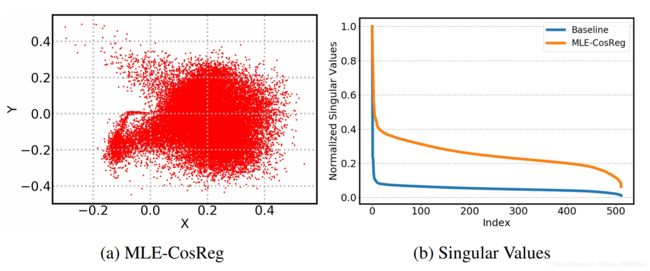
6.2 实验结果(Experiment Result)
对于语言模型来说,我们从三个不同设置对比了我们的方法与AWD-LSTM的原型模型:无微调(Finetuning),有微调和连续缓存指针。我们的结果最终在Perplexity上以0.8/1.7/2.0的提升超越了它。在机器翻译中,我们选择了Transformer的原型模型,并且保持了其默认设置。在英德翻译任务中我们分别取得了1.08/0.93的提升。而在big Transformer模型上也有0.54的提升。
注意到,对所有的任务来收,我们只增加了一个简单的正则项,而没有其他的模型改变,因此,准确度的提升单纯的来源于我们提出的方法。这证实了对词嵌进行相似性正则化的有效之处,我们提出的MLE-CosReg损失函数可以获得一个更好的结果。
6.4 结果讨论(Discussion)
以上的研究证实了我们方法的有效性。但是,还不能说明我们的方法是否提升了词嵌的表达能力。在这一节,我们提供了一个更细致的说明。
对于第三节提到的经验学习,我们分析了本模型在英德翻译任务上的词嵌矩阵。我们将其映射在二维平面上(图 2(a)),发现词嵌距原点呈现了均匀分布,并没有形成锥形区。同时我们也对矩阵的奇异值进行了比较,结果在图 2(b)中展示。通过图中的结果,我们可以发现,在Transformer原型的训练后,少数的奇异值占据了主导地位;而我们训练得到的词嵌矩阵奇异值相较其更为均匀,这再次验证了我们方法在词嵌表达方面的多样性。
7 总结与展望(Conclusion and Future Work)
在这项工作中,我们分析了神经网络训练中的表达退化问题,并提出了一个新型的正则项以缓解这种问题,提升了词嵌矩阵的表达能力。在语言模型和机器翻译的实验中都证实了我们方法的有效性。
在未来,我们将尝试将这种方法与更多的语言模型结合。我们提出的正则项主要基于余弦相似性,然而可能存在更好的正则方法。另外,可以考虑把我们的方法与(Gong et al., 2018)提出的方法进行结合,以丰富词嵌的表达能力。