android .dex文件探究
在我们写Java代码的时候,生成的文件是.java文件,但是JVM并不识别这个,所以会先转成class文件,而在Android端,Android上的Davlik虚拟机能运行.dex。所以dex文件中包含了所有的app代码,可利用反编译工具获取java代码。
即dex文件就是Android Dalvik虚拟机运行的程序。
为了能够加深印象,我们先构造一个dex文件。
public class DEX {
int a = 0;
static String b = "HelloDalvik";
public int getNumber(int i,int j){
int e = 3;
return e+i+j;
}
public static void main(String[] args){
int c= 1;
int d = 2;
DEX dex = new DEX();
String sayNumber = String.valueOf(dex.getNumber(c,d));
System.out.println("HelloDalVik "+sayNumber);
}
}
先执行 javac DEX.java
这样会生成一个.class文件,然后在SDK中找到dx.bat,
执行 xx\xxx\xxx\dx --dex --output=DEX.java DEX.class
这样就会生成DEX.dex文件,如果出现does not match path 的错误,就,这样执行:
D:\SDK\build-tools\27.0.1\dx --dex --output=DEX.dex com\example\asus1\rexiufu\DEX.class
然后我们使用010 Editor来打开这个DEX.dex文件
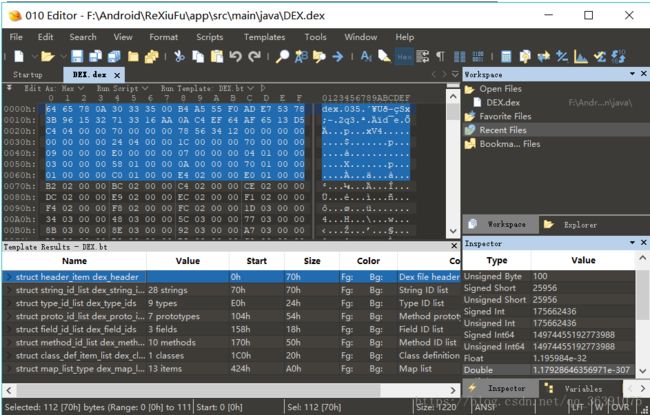
DEX文件结构
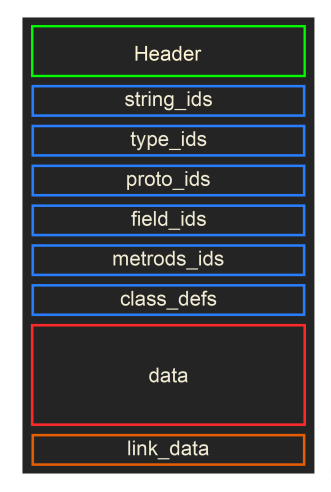
我们先看Header:
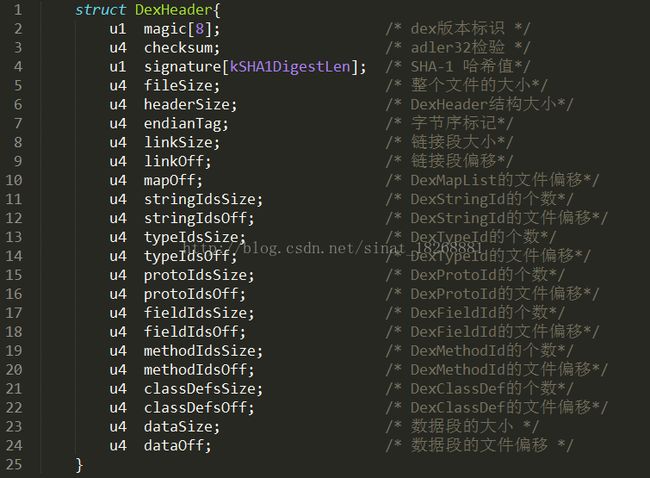
文件头包含了dex文件的信息,所有数据的大致分布情况
然后我们看看Header的数据图:在Editor中查看:
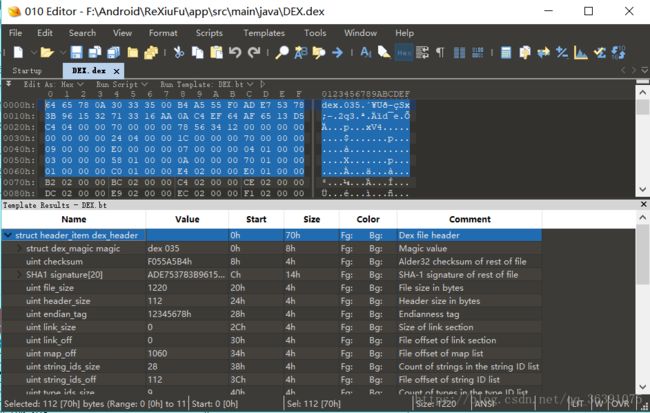
可以看到第一个,magic[8],它代表dex文件中的文件标识,一般被称为魔数。是用来识别dex这种文件的,它可以判断当前的dex文件是否有效,可以看到它用来8个1字节的无符号数来表示,我们在Editor中可以看到是“64 65 78 0A 30 33 35 00”这8个字节,这些字节都是16进制表示的。这8个字节用ASCII码转换为dex.035(“.”不是转换来的)。目前,dex的魔数固定为dex.035
然后第二个,checksum,它是dex文件的校验和,通过它可以判断dex文件是否被损坏或者被篡改。它占用4个字节
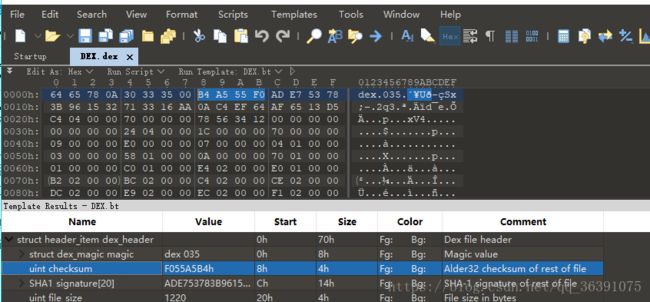
我们可以看到它的值和它对应的四个字节,刚好是反着的。这是由于dex文件中采用的是小字节序的编码方法,也就是低位上存储的就是低字节的内容。
第三个是SHA1 signature[20],signature字段用于检验dex文件,其实就是把整个dex文件用SHA-1签名得到的一个值。这里占用了20个字节。
第四个是fileSize,表示整个文件的大小,占用4个字节
第五个是headerSize,表示DexHeader头结构的大小,占用4个字节。
第六个是endianTag,代表字节序标记,用于执行dex运行环境的cpu,预设值为0x12345678,对应在101Editor中为“78 56 34 12”
接下来两个分别是linkSize和linkOff,这连个字段,分别指定了链接段的大小和文件偏移,通常情况下它们都为0,。linkSize为0的话表示静态连接。
再下来就是mapOff字段,它指定了DexMapList的文件偏移,就是dex文件结构图中的最后一层。
接下来的两个StringIdsSize和StringIdsOff:这两个字段指定了dex文件中所有用到的字符串的个数和位置偏移。我们先看StringIdsSize,现在它的是十进制值为28,也就是说我们这个dex文件一共有28个字符串,StringIdsOff的值为“70 00 00 00”,表示字符串的偏移位置为70h,然后我们找到70h的地方:
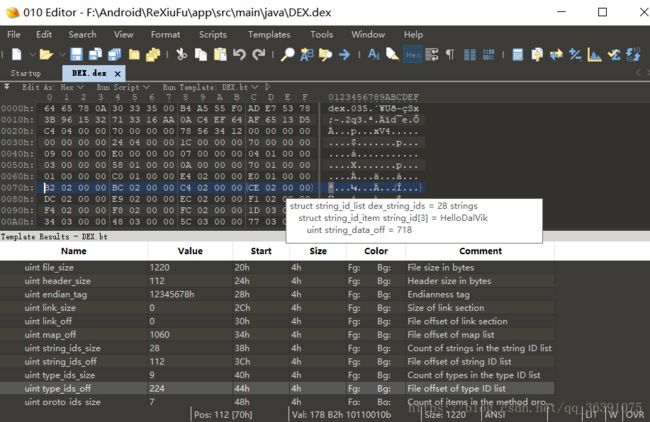
在第4个中,显示的字符串是“HelloDalVik”,
然后我们再看看dex的结构图:
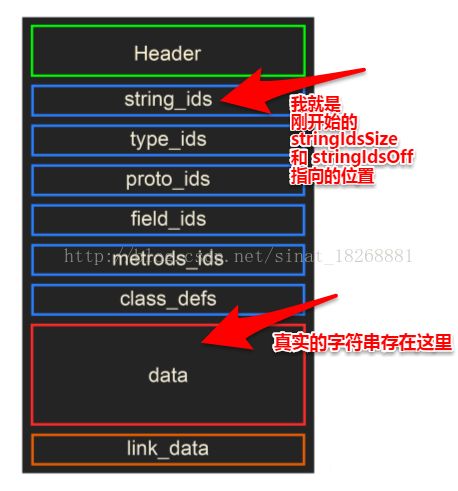
然后我们继续看
接下来是typeIdsSize和typeIdsOff,它们代表类的类型的数量和位置偏移,都占4个字节,typeIdsSize的的值为9,表示dex文件中用到的类的类型一共有9个,typeIdsOff的值为“E0 00 00 00 ”,即偏移位置在E0:
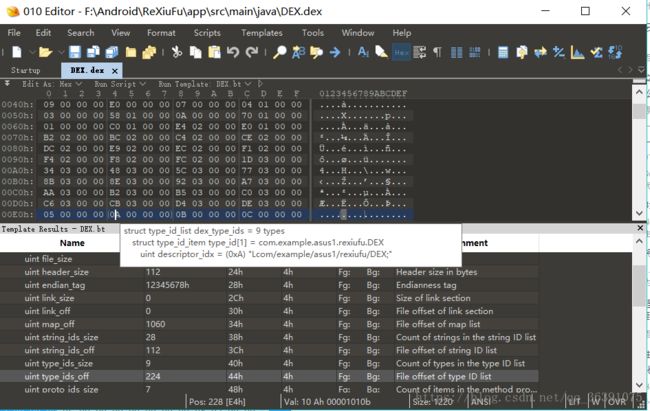
接下来两个是protoIdsSize和protoIdsOff,它们表示dex文件中方法原型的个数和位置偏移,现在protoIdsSize的值为7,说明有7个方法原型,然后位置偏移是104h
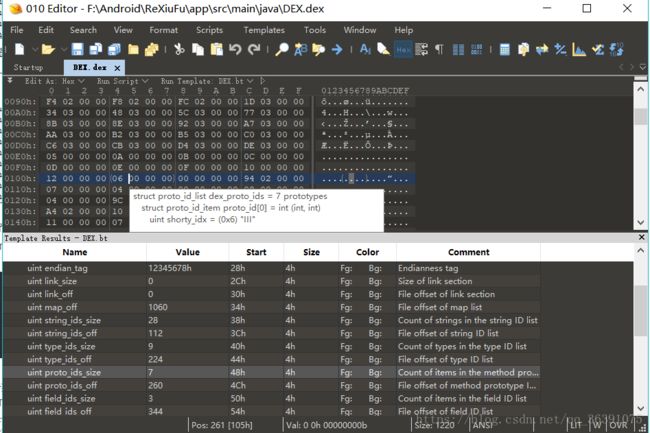
这里涉及到一个数据结构:
struct DexProtoId{
u4 shortyIdx; /*指向DexStringId列表的索引*/
u4 returnTypeIdx; /*指向DexTypeId列表的索引*/
u4 parametersOff; /*指向DexTypeList的位置偏移*/
}
可以看到,这个数据结构由三个变量组成。第一个shortyIdx,它指向我们上面分析的DexStringId列表的索引,代表的是方法声明字符串。第二个returnTypeIdx它指向的是我们上班分析的DexTypeId列表索引,代表的是方法返回类型字符串。第三个parameterOff指向的是DexTypeList的位置索引,这又是一个新的数据结构,这里面存储的是方法的参数类别。
可以看到这三个参数,方法声明字符串,返回类型,参数列表,这基本上确定了我们一个方法的大体内容。
struct DexTypeList{
u4 size; /*DexTypeItem的个数*/
DexTypeItem list[1]; /*DexTypeItem结构*/
}
struct DexTypeItem{
u2 typeIdx; /*指向DexTypeId列表的索引*/
}
这样的话,我们可以看到,第一个方法为 int(int,int)
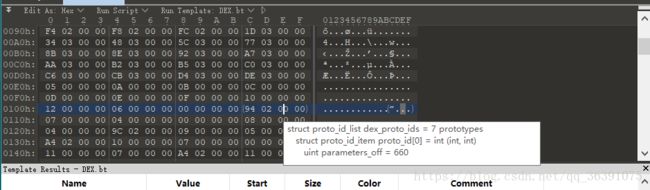
我们继续看下面的两个,fieldIdsSize和fieldIdsOff,指向的是dex文件中字段名的信息。这里fieldIdsSize的大小为3,fieldIdsOff的值为“58 01 00 00 ”:
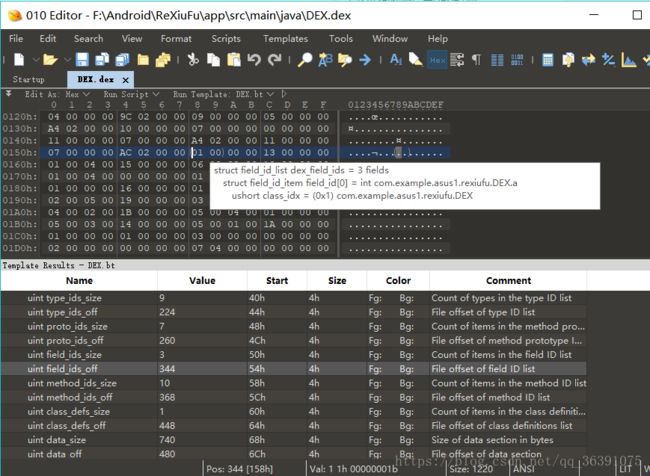
又涉及到有个数据结构:
struct DexFieldId{
u2 classIdx; /*类的类型,指向DexTypeId列表的索引*/
u2 typeIdx; /*字段类型,指向DexTypeId列表的索引*/
u4 nameIdx; /*字段名,指向DexStringId列表的索引*/
}
我们可以看到第一个DexFieldId是Dex中的a
继续继续,methodIdsSize和methodIdsOff,指明了方法所在的类,方法的声明以及方法名,现在methodIdsSize的值为10,methodIdsOff的值为“70 01 00 00”,
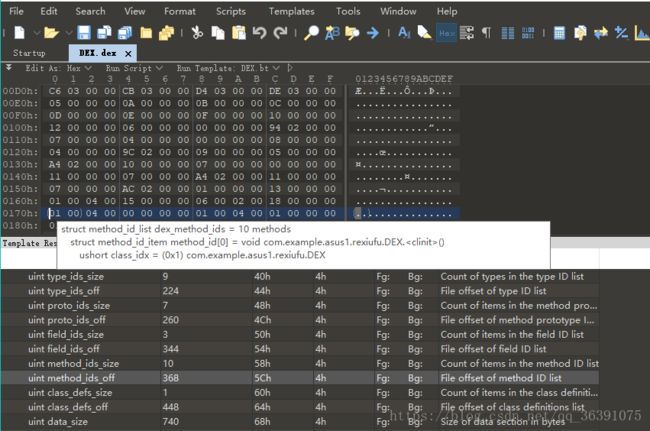
它涉及到的数据结构:
struct DexMethodId{
u2 classIdx; /*类的类型,指向DexTypeId列表的索引*/
u2 protoIdx; /*声明类型,指向DexProtoId列表的索引*/
u4 nameIdx; /*方法名,指向DexStringId列表的索引*/
}
分析可以得到,第一个方法为 void DEX.
接下来是classDefsSize和classDefsOff,这两个字段指明的是dex文件中类的定义的相关信息,在这里,classDefsSize的值是1,classDefsOff的是“C0 01 00 00”,
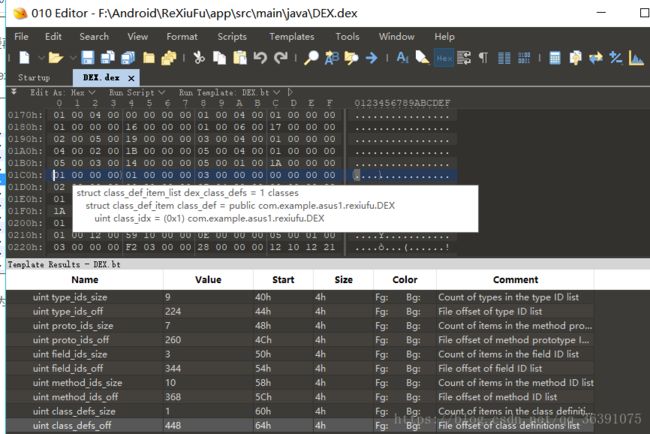
这里涉及的数据结构:
struct DexClassDef{
u4 classIdx; /*类的类型,指向DexTypeId列表的索引*/
u4 accessFlags; /*访问标志*/
u4 superclassIdx; /*父类类型,指向DexTypeId列表的索引*/
u4 interfacesOff; /*接口,指向DexTypeList的偏移*/
u4 sourceFileIdx; /*源文件名,指向DexStringId列表的索引*/
u4 annotationsOff; /*注解,指向DexAnnotationsDirectoryItem结构*/
u4 classDataOff; /*指向DexClassData结构的偏移*/
u4 staticValuesOff; /*指向DexEncodedArray结构的偏移*/
}
我们可以看到,这个找到的类是DEX
接下来是DataSize和DataOff,这里DataOff的值是“E0 01 00 00 ”,找到01E0h,这里存放的是DexCode。
dex文件的加载流程
https://blog.csdn.net/jsqfengbao/article/details/52103439
https://www.jianshu.com/p/c9fd64e0b934
参考:
https://blog.csdn.net/sinat_18268881/article/details/55832757