Python写网络爬虫:requests 模块的高级用法
文章目录
- 1. 文件上传
- 2. 获取和设置Cookies
- 3. SSL 证书验证
- 4. 代理设置
- 5. 超时设置
- 6. 身份验证
1. 文件上传
import requests
filename = '1.txt'
files = {'file':open(filename)}
x = requests.post('http://httpbin.org/post',files=files)
print(x.text)
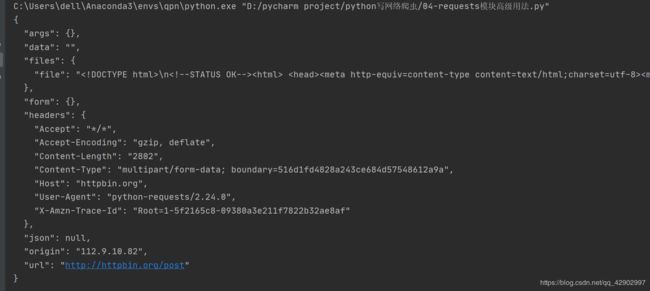
通过测试服务器 httpbin.org 返回的结果来看,post 能够上传的文件和格式都写得很清楚:
- data : 字符串的形式
- files: 字典的形式 (一个files 里面可以上传多个file)
- form: 字典形式
- headers:与 get 方法中的 headers一样,包含了请求报文的请求头信息
2. 获取和设置Cookies
import requests
import requests
r = requests.get('http://www.zhihu.com')
print(r.cookies) # cookie信息包含在 get 获取的服务器信息中
print(type(r.cookies))
for key,value in r.cookies.items():
print(key+'='+value)
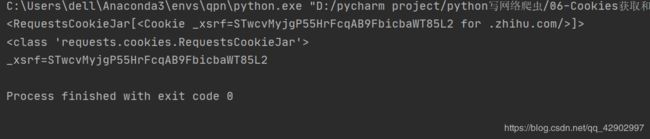
cookies 的类型是 RequestsCookieJar,用 items() 方法将其转化成元组组成的列表,遍历输出每一个Cookie 的名称和值,实现 Cookie 的遍历和解析。
如果希望使用自己的cookie来访问这些网页,也可以在发送请求的时候把自己的cookie 放到 headers 里面,然后发送请求。
下面的程序是在登录网站之后拷贝的网页的 Cookie 值,这样的话可以直接用这个 Cookie 来访问网页数据。
import requests
string = '_zap=3719d565-9bca-44de-9b02-ed714258e599; d_c0="AMCf599-hhGPTltrHaZ91mg1vjF3HaLikx4=|1593863623"; _ga=GA1.2.1482983231.1593863637; _xsrf=47112a4a-9751-4136-85d4-4cd0ff3e57fc; _gid=GA1.2.1072146028.1596031364; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1595839169,1595921642,1595932793,1596031375; capsion_ticket="2|1:0|10:1596031378|14:capsion_ticket|44:NTcwOGNkOGNhNTY2NDc0NTgwMzgwNjQ2NGY0YTg2MWQ=|02d6f4cf78555e932a8cb7f79c159935ce9373a7e2546e0be63971e288846bfc"; SESSIONID=DtgOvBScEJCX7GFsKvFtxNzXrnYijTajpqfaPx7kkMk; JOID=Vl4QA0oG8CXIhPNMIALX_xtO4NkwQIdHhvezHEZGuGWVsrEIUJN3AJOD8kokJZhEeW5Qs7PiMlIcjk_5S3UHixE=; osd=UlwcBkIC8inNjPdOLAff-xlC5dE0QotCjvOxEENOvGeZt7kMUp9yCJeB_k8sIZpIfGZUsb_nOlYegkrxT3cLjhk=; l_n_c=1; r_cap_id="N2FlYjU3Y2Q3YjQ1NDEzYTk5MmJkMWE4NmU2ZTVjNjA=|1596031386|902835602a8c71f45ed7564e15947880c55b5a26"; cap_id="MTgzMDNiYjU0NzZhNGQ0ODg5OWY2ZjBmNTlkZDc2Njg=|1596031386|456383a04b6c02f6d2318a0b387af57b17cc77b5"; l_cap_id="ZDA5ZjNiMmYyN2NhNDg1ZmFmZmU5NTZmZjk4MTgwM2M=|1596031386|5395222721c6cd25d5feb6651ed585079e59f6bc"; n_c=1; z_c0=Mi4xeVJrX0JBQUFBQUFBd0pfbjMzNkdFUmNBQUFCaEFsVk5zTThPWUFDTkc5R2R5QmRQRDBBWUZnNEpLQlVNSTdYS1NR|1596031408|a2b2c9b741d3e389e979e5ce8d34068430a9d105; tst=r; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1596031411; KLBRSID=4843ceb2c0de43091e0ff7c22eadca8c|1596031433|1596031372'
string = string.replace('\"',"") # cookie 中出现双引号等特殊符号的时候,消除掉
print(string)
headers = {
'Host':'www.zhihu.com',
'Cookie':string,
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36' #这条一定不能漏,否则请求不到数据,因为服务器会发现是非人为操作
}
r = requests.get('http://www.zhihu.com',headers=headers)
print(r.text)
3. SSL 证书验证
import requests
response = requests.get('https://www.12306.cn',verify=False) #设置verify项
print(response.text)
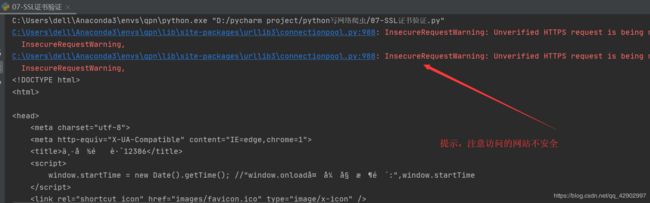
因为 verify 设置成了 True ,所以对一些没有 SSL 证书的网站也能访问,但是会给予 warning
4. 代理设置
当大规模爬取数据的时候,固定的 IP 会被服务器检测到,从而不能再请求到数据,这个时候,我们要使用代理,因为使用代理服务器去爬取某个网站的时候,在对方的网站上,显示的不是我们真实的IP地址,而是代理服务器的IP地址。这就需要使用proxies参数。
import requests
proxies = {
'http':'http://123.54.52.206:8828', #代理服务器的 ip 和端口号
'https':'http://117.69.13.96:8128'
}
response = requests.get('https://www.12306.cn',proxies=proxies)
print(response.text)
代理服务器有免费的,也有花钱的,总之,只需要提供端口号和ip就可以成功地使用代理服务器了
在HTTP中,基本认证(Basic access authentication)是一种用来允许网页浏览器或其他客户端程序在请求时提供用户名和口令形式的身份凭证的一种登录验证方式。
如果代理需要使用 HTTP basic auth, 提供代理服务器的时候就要写成如下形式:
http://user:passworld @ host_ip:port ,实例如下:
proxies = {
'http':'http://user:[email protected]:8828/'
'http':'http://user:[email protected]:8128/'
}
当然,代理服务器的协议也不只一种,还可以使用SOCKS协议的代理
需要首先安装socks库:
pip install 'requests[socks]'
然后形式与http协议的代理是一样的:
proxies = {
'http':'socks5://user:passworld@host_ip:port/',
'https':'socks5://user:passworld@host_ip:port/'
}
5. 超时设置
超时设置的时间一旦超过,程序运行停止
超时设置可以设置以下形式的参数
response = requests.get('https://www.12306.cn',timeout=5)#总时间
response = requests.get('https://www.12306.cn',timeout=(5,11,30)) #连接时间、读取时间
response = requests.get('https://www.12306.cn',timeout=None) #无限等待
response = requests.get('https://www.12306.cn') #无限等待
6. 身份验证
如果遇到认证页面,则需要使用 requests 自身带的认证功能;启用这个功能会自动使用 HTTPBasicAuth 这个类来认证
response = requests.get('https://www.12306.cn',auth=('username','password'))
也可以使用OAuth认证,要先安装 oauth 的包
pip install requests_oauthlib
认证方式如下:
import requests
from requests_oauthlib import OAuth1
url = 'http://api.twitter.com/1.1/account/verify_credentials.json'
auth = OAuth1('YOUR_APP_KEY','YOUR_APP_SECRET',
'USER_OAUTH_TOKEN','USER_OAUTH_TOKEN_SECRET')
requests.get(url,auth)