【Python】selenium 库的安装与基础操作(使用Chrome)
刚开始接触 selenium,顺便记录一下入门过程。
我用 selenium 只是为了达成一个目的:我有几个账号,每天需要到某网页上逐个登录几次。我想把这个过程自动化一下,所以学习 selenium 模拟我自己的操作。因为需求挺简单,很容易就实现了。所以这篇博客只是入门,并不深入。
开始之前默认你已经安装了 Python 环境,并会使用 pip 命令。 我这里使用 Windows系统,PyCharm 作为编程环境, Chrome 浏览器进行操作。有兴趣可以看我另一篇博客:
Anaconda 创建和管理不同 Python 环境以及 PyCharm 中不同环境的切换
什么是 selenium
selenium 是一个用于Web应用程序测试的工具,直接运行在浏览器中,模拟真正的用户操作。现在 selenium 还被用来作为模拟真人操作的爬虫爬取网页数据。
安装 selenium
selenium可以直接可以用 pip 安装。如果你有多个环境注意安装到你使用的环境中。
pip install selenium
安装chromedriver
chromedriver 是用来操控 Chrome 浏览器的工具。注意下载的版本一定要与Chrome的版本一致,不然就不起作用。
首先需要查看你的Chrome版本,在浏览器地址栏中输入
chrome://version/
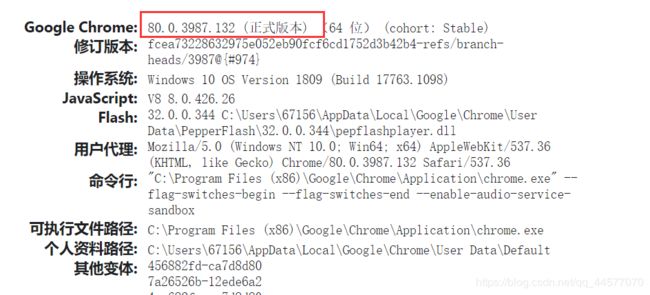
有两个地址可供下载,建议选择第二个淘宝镜像,国内访问速度快很多。
http://chromedriver.storage.googleapis.com/index.html
https://npm.taobao.org/mirrors/chromedriver/
找到浏览器对应的版本,如果没有绝对对应,个人建议下载偏大一点的。

下载后解压压缩包,把 chromedriver.exe 文件复制到 Chrome 的安装目录(其实也可以随便放一个文件夹)。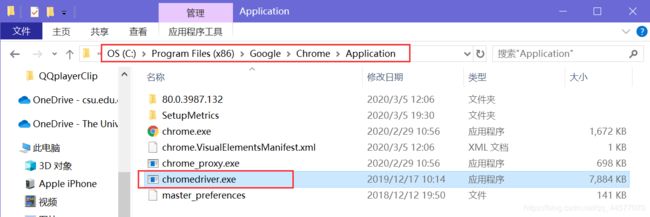
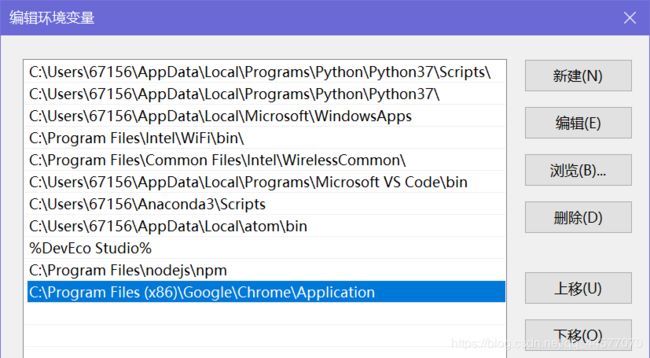
复制这个目录路径,进入环境变量配置页面【右键计算机 - 属性 - 高级系统设置 - 高级 - 环境变量】

编辑 Path 变量,添加刚刚复制的路径,保存。
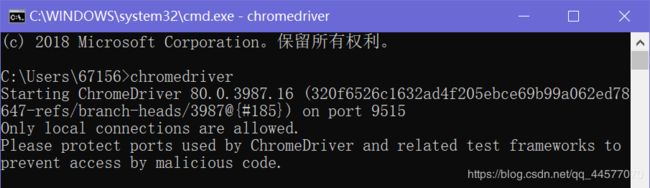
打开 CMD 输入 chromedriver 验证是否安装成功。
如果你没配置环境变量,那么使用的时候每次都要指定路径,建议配置好比较方便。
#未配置变量需指定路径
chrome_driver = 'C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe' #chromedriver的文件位置
b = webdriver.Chrome(executable_path = chrome_driver)
b.get('https://www.baidu.com')
如果运行时出现版本异常,很可能是 chromedriver 的版本不对。
基础操作
打开网页
from selenium import webdriver #导入库
browser = webdriver.Chrome() #使用Chrome浏览器
browser.maximize_window() #窗口最大化
url = 'https://blog.csdn.net/qq_44577070/article/details/104845600'
browser.get(url) #打开网页
如果你以上配置没有问题,四行代码即可打开你指定的网页。但是打开网页后我想要模拟人去输入、点击怎么办?这就要涉及组件的定位了。
组件定位
常用到的有 8 种定位方式,还有其他更多高阶操作不展开说了,大家可以去搜索相关博客教程。
1.id定位:find_element_by_id(self, id_)
2.name定位:find_element_by_name(self, name)
3.class定位:find_element_by_class_name(self, name)
4.tag定位:find_element_by_tag_name(self, name)
5.link定位:find_element_by_link_text(self, link_text)
6.partial_link定位find_element_by_partial_link_text(self, link_text)
7.xpath定位:find_element_by_xpath(self, xpath)
8.css定位:find_element_by_css_selector(self, css_selector)
不懂什么意思?没关系,下面通过实例告诉你怎么用。
百度搜索实例
打开 https://www.baidu.com/,在输入框右键 - 检查,可以看到网页源代码。同样,在百度一下按钮处检查也能看到按钮的源代码。
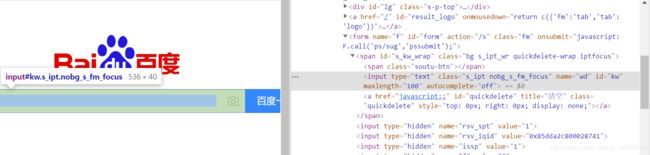
部分关键代码如下:
<span class="bg s_ipt_wr quickdelete-wrap">
<span class="soutu-btn">span>
<input id="kw" class="s_ipt" autocomplete="off" maxlength="255" value="" name="wd">
<a id="quickdelete" class="quickdelete" href="javascript:;" title="清空" style="top: 0px; right: 0px; display: none;">a>
span>
<span class="bg s_btn_wr">
<input id="su" class="bg s_btn" type="submit" value="百度一下">
span>
如果稍懂 html 的朋友这里应该不用多说。
上面那个 span 种是输入框的代码,下面的 span 是按钮的代码。其中 input 组件正是我们需要输入和点击的地方。
组件都会有各种属性,为了方便都会有各种名命。我们定位组件就是利用组件特有的名命,比如 id、class、name 这种只有这个组件特有的。
比如我要找 id="kw" 的,我就找到了这个输入框。我要找 class="s_btn" 的,我就找到了百度一下按钮。这里这个 class 有两个名字,一个 bg 一个 s_btn,中间用空格隔开,两个名字都是指这个按钮,目的是减少代码重复。
这正是通过 id 定位和通过 class 定位的方法:
from selenium import webdriver #导入库
browser = webdriver.Chrome() #使用Chrome浏览器
browser.get("http://www.baidu.com") #打开网页
browser.find_element_by_id("kw").send_keys("Selenium") #id定位,输入值
browser.find_element_by_class_name("s_btn").click() #class定位,点击
以上五行代码,即实现了 打开百度 - 输入 Selenium - 点击搜索 这一连续操作。
在进行更复杂的操作时,考虑到网络延时可以加入异常处理机制,防止一次连接错误导致后续操作也停止运行。也可以加入 time.sleep() 在连续操作之间稍微休眠等待等等。
selenium 作用远不止如此,更多操作大家可以搜一下相关的资料,会讲得更详细,这篇博客只是入门而已。一起学习进步!