原文链接: http://www.crazygaze.com/blog/2016/03/17/how-strands-work-and-why-you-should-use-them/
如果你使用过Boost Asio,一般情况下你都使用过或者了解过strands。
使用strands最显著的好处就是简化我们的代码,因为通过strand来维护handler不需要显式地同步线程。strands保证同属于一个strand的两个handler不会同时执行(在两个线程同时执行)。
如果你只使用一个IO线程(在Boost里面只有一个线程调用io_service::run),那么你不需要做任何的同步,此时已经是隐式的strand。但是如果你想提高性能,因此使用多个IO线程,那么你有两种选择,一种是在不同的handler进行显式的同步,另一种就是使用strand。
显式同步handler会提升代码的复杂度,从而导致bug产生。显式同步的另外一个负面影响就是会给线程产生没有必要的阻塞。
strands通过在你的应用代码和handler执行代码之间插入一层,从而避免工作线程直接执行你的handler,而是将handler插入队列,strand控制handler的执行顺序,就像下面这张图:
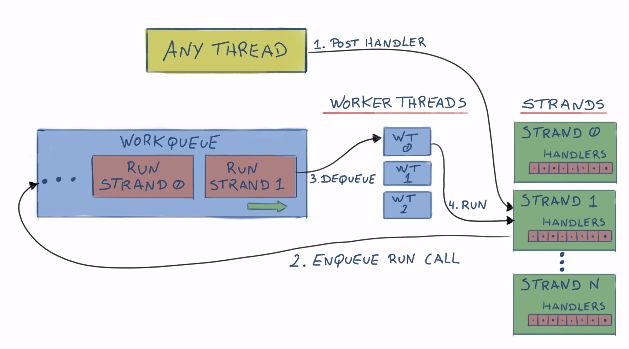
可能发生的情况
为了可视化地说明IO线程和handlers之间发生了什么,我使用了Remotery。
测试代码模拟4个工作线程和8个连接。对于一个连接,handler会产生一个随机的工作时间(5ms到15ms之间),实际上你不需要随机设置这些工作时间,这只是为了更容易地说明问题。另外,我没有使用Boost Asio,我自己定制了一个strand。
那么,来看一下每一个工作线程的情况:

Conn N是我们的连接实例(每一个连接都运行在一个工作线程里面)。每一个连接有不同的颜色,现在让我们看一下每一个时间片,每一个Conn都在做什么。

上面的情况是各个工作线程并不关心每一个handler在做什么,一个线程尝试执行一个Conn,它发现在另外一个工作线程中Conn也在执行,因此第二个工作线程就阻塞了。
在这个案例中19%的时间浪费在阻塞和其他的负载中,也就是说工作线程只有81%的时间在做真正的工作:

注意:计算的结果是线程的总共运行时间减去线程工作时间,剩下的时间也就是线程用于同步的时间。
让我们看看使用strand的结果:


非常少的时间用于线程的内部同步。
Cache局部性
另一个使用strand的好处就是提高CPU的Cache利用率,一个工作线程会使用等多的时间处理数量少的handler。
不使用strand的情况:

使用strand的情况:

实现strands
作为练习,我自己实现一个strand,虽然没有达到产品的标准,但却可以用于实验。
首先,让我们思考一下strands具有哪些功能:
- 没有handler可以同时执行
- 这要求我们检测是否有工作线程正在使用strand,如果有使用,strand处于running状态
- 为了避免阻塞,strand需要一个handler队列,以至于如果strand正运行在其他线程上,此handler将会进入队列稍后执行
- handler仅仅执行于工作线程
- 这通常也指明了strand的handler队列的任务,如果在一个非工作线程中加入一个handler,handler将会进入队列
- handler的执行顺序是不保证的
- 因为我们尝试从不同的线程中将handler加入strand,所以我们无法保证handler的执行顺序
strand的实现围绕着三个方法:
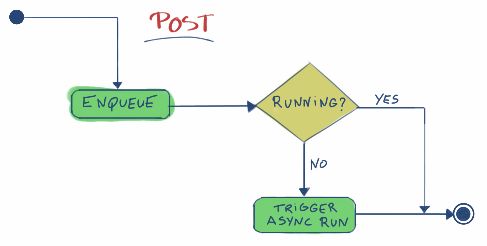
- post
- 添加一个handler,此handler将会在稍后执行。此函数不会立即执行。
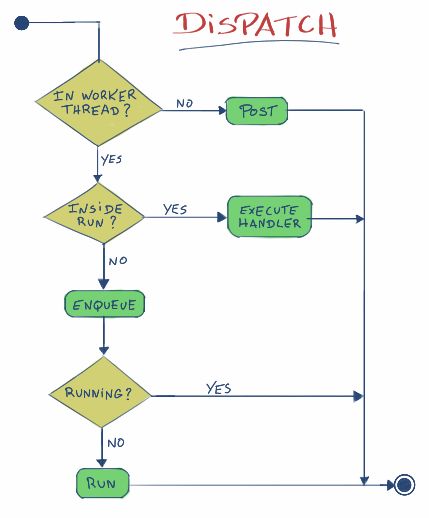
- dispatch
- 如果所有条件都达到了,立即执行此handler,否则调用post
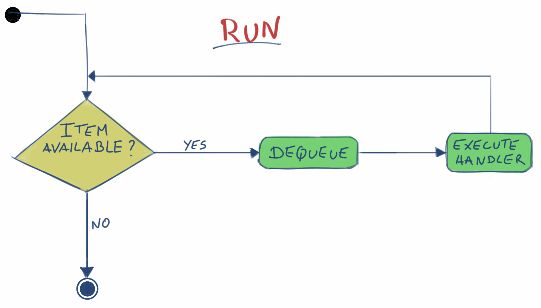
- run
- 执行任意一个handler,此函数并不是公共(public)函数
现在我们可以画出这三个方法的流程图:
为了实现strands,我们需要使用到我先去讲到的两个类:
- CallStack
- 在当前的调用栈做标记,用于检测是否在当前线程执行给定的函数
- WorkQueue
- 简单的生产者/消费者模型
另外还有Monitor,允许你对一个类型T的对象进行强制同步,你可以在这个视频中看到更详细的信息,我将使用下面的实现:
- 简单的生产者/消费者模型
template
class Monitor {
private:
mutable T m_t;
mutable std::mutex m_mtx;
public:
using Type = T;
Monitor() {}
Monitor(T t_) : m_t(std::move(t_)) {}
template
auto operator()(F f) const -> decltype(f(m_t)) {
std::lock_guard hold{m_mtx};
return f(m_t);
}
};
strand的实现与上图的描述基本一致,但是为了说明内部的同步机制,我在代码里面还是做了很多注释:
#pragma once
#include "Callstack.h"
#include "Monitor.h"
#include
#include
#include
//
// A strand serializes handler execution.
// It guarantees the following:
// - No handlers executes concurrently
// - Handlers are only executed from the specified Processor
// - Handler execution order is not guaranteed
//
// Specified Processor must implement the following interface:
//
// template void Processor::push(F w);
// Add a new work item to the processor. F is a callable convertible
// to std::function
//
// bool Processor::canDispatch();
// Should return true if we are in the Processor's dispatching function in
// the current thread.
//
template
class Strand {
public:
Strand(Processor& proc) : m_proc(proc) {}
Strand(const Strand&) = delete;
Strand& operator=(const Strand&) = delete;
// Executes the handler immediately if all the strand guarantees are met,
// or posts the handler for later execution if the guarantees are not met
// from inside this call
template
void dispatch(F handler) {
// If we are not currently in the processor dispatching function (in
// this thread), then we cannot possibly execute the handler here, so
// enqueue it and bail out
if (!m_proc.canDispatch()) {
post(std::move(handler));
return;
}
// NOTE: At this point we know we are in a worker thread (because of the
// check above)
// If we are running the strand in this thread, then we can execute the
// handler immediately without any other checks, since by design no
// other threads can be running the strand
if (runningInThisThread()) {
handler();
return;
}
// At this point we know we are in a worker thread, but not running the
// strand in this thread.
// The strand can still be running in another worker thread, so we need
// to atomically enqueue the handler for the other thread to execute OR
// mark the strand as running in this thread
auto trigger = m_data([&](Data& data) {
if (data.running) {
data.q.push(std::move(handler));
return false;
} else {
data.running = true;
return true;
}
});
if (trigger) {
// Add a marker to the callstack, so the handler knows the strand is
// running in the current thread
Callstack::Context ctx(this);
handler();
// Run any remaining handlers.
// At this point we own the strand (It's marked as running in
// this thread), and we don't release it until the queue is empty.
// This means any other threads adding handlers to the strand will
// enqueue them, and they will be executed here.
run();
}
}
// Post an handler for execution and returns immediately.
// The handler is never executed as part of this call.
template
void post(F handler) {
// We atomically enqueue the handler AND check if we need to start the
// running process.
bool trigger = m_data([&](Data& data) {
data.q.push(std::move(handler));
if (data.running) {
return false;
} else {
data.running = true;
return true;
}
});
// The strand was not running, so trigger a run
if (trigger) {
m_proc.push([this] { run(); });
}
}
// Checks if we are currently running the strand in this thread
bool runningInThisThread() {
return Callstack::contains(this) != nullptr;
}
private:
// Processes any enqueued handlers.
// This assumes the strand is marked as running.
// When there are no more handlers, it marks the strand as not running.
void run() {
Callstack::Context ctx(this);
while (true) {
std::function handler;
m_data([&](Data& data) {
assert(data.running);
if (data.q.size()) {
handler = std::move(data.q.front());
data.q.pop();
} else {
data.running = false;
}
});
if (handler)
handler();
else
return;
}
}
struct Data {
bool running = false;
std::queue> q;
};
Monitor m_data;
Processor& m_proc;
};
用例
一个简单的用例:
#include "Strand.h"
#include "WorkQueue.h"
#include
#include
#include
#include
// http://stackoverflow.com/questions/7560114/random-number-c-in-some-range
int randInRange(int min, int max) {
std::random_device rd; // obtain a random number from hardware
std::mt19937 eng(rd()); // seed the generator
std::uniform_int_distribution<> distr(min, max); // define the range
return distr(eng);
}
struct Obj {
explicit Obj(int n, WorkQueue& wp) : strand(wp) {
name = "Obj " + std::to_string(n);
}
void doSomething(int val) {
printf("%s : doing %dn", name.c_str(), val);
}
std::string name;
Strand strand;
};
void strandSample() {
WorkQueue workQueue;
// Start a couple of worker threads
std::vector workerThreads;
for (int i = 0; i < 4; i++) {
workerThreads.push_back(std::thread([&workQueue] { workQueue.run(); }));
}
// Create a couple of objects that need strands
std::vector> objs;
for (int i = 0; i < 8; i++) {
objs.push_back(std::make_unique(i, workQueue));
}
// Counter used by all strands, so we can check if all work was done
std::atomic doneCount(0);
// Add work to random objects
const int todo = 20;
for (int i = 0; i < todo; i++) {
auto&& obj = objs[randInRange(0, objs.size() - 1)];
obj->strand.post([&obj, i, &doneCount] {
obj->doSomething(i);
++doneCount;
});
}
workQueue.stop();
for (auto&& t : workerThreads) {
t.join();
}
assert(doneCount == todo);
}
输出:
Obj 2 : doing 0
Obj 1 : doing 1
Obj 1 : doing 3
Obj 1 : doing 4
Obj 3 : doing 6
Obj 5 : doing 2
Obj 4 : doing 5
Obj 6 : doing 11
Obj 3 : doing 8
Obj 5 : doing 10
Obj 5 : doing 12
Obj 6 : doing 17
Obj 3 : doing 9
Obj 3 : doing 13
Obj 5 : doing 18
Obj 0 : doing 14
Obj 2 : doing 15
Obj 3 : doing 16
Obj 5 : doing 19
Obj 1 : doing 7
小结
- handler间不存在显式的同步
- 较少的线程阻塞
- Cache局部性