深度神经网络经典模型介绍
经典模型的特点介绍
VGG,GoogleNet,ResNet,Inception-ResNet-v2
1. VGG模型
VGG又分为VGG16和VGG19, 分别在AlexNet的基础上将层数增加到16和19层, 它除了在识别方面很优秀之外, 对图像的目标检测也有很好的识别效果, 是目标检测领域的较早期模型。
2. GoogLeNet模型
GoogLeNet除了层数加深到22层以外, 主要的创新在于它的Inception, 这是一种网中网(Network In Network) 的结构, 即原来的节点也是一个网络。 用了Inception之后整个网络结构的宽度和深度都可扩大, 能够带来2到3倍的性能提升。
3. ResNet模型
ResNet直接将深度拉到了152层, 其主要的创新在于残差网络, 其实这个网络的提出本质上是要解决层次比较深时无法训练的问题。 这种借鉴了Highway Network思想的网络, 相当于旁边专门开个通道使得输入可以直达输出, 而优化的目标由原来的拟合输出H(x) 变成输出和输入的差H(x) -x, 其中H(x) 是某一层原始的期望映射输出, x是输入。
4. Inception-ResNet-v2模型
Inception-ResNet-v2: 是目前比较新的经典模型, 将深度和宽带融合到一起, 在当下ILSVRC图像分类基准测试中实现了最好的成绩, 是将Inception v3与ResNet结合而成的。接下来主要对当前比较前沿的GoogLeNet、 ResNet、 Inception-ResNet-v2几种网络结构进行详细介绍。
GoogLeNet模型介绍
前面已经介绍过GoogLeNet, 其中最核心的亮点就是它的Inception, GoogLeNet网络最大的特点就是去除了最后的全连接层, 用全局平均池化层(即使用与图片尺寸相同的过滤器来做平均池化) 来取代它。
这么做的原因是: 在以往的AlexNet和VGGNet网络中, 全连接层几乎占据90%的参数量, 占用了过多的运算量内存使用率, 而且还会引起过拟合。
GoogLeNet的做法是去除全连接层, 使得模型训练更快并且减轻了过拟合。
之后GoogLeNet的Inception还在继续发展, 目前已经有v2、 v3和v4版本, 主要针对解决深层网络的以下3个问题产生的。
(1)·参数太多, 容易过拟合, 训练数据集有限。
(2)·网络越大计算复杂度越大, 难以应用。
(3)·网络越深, 梯度越往后传越容易消失(梯度弥散) , 难以优化模型。
Inception的核心思想是通过增加网络深度和宽度的同时减少参数的方法来解决问题。Inception v1有22层深, 比AlexNet的8层或者VGGNet的19层更深。 但其计算量只有15亿次浮点运算, 同时只有500万的参数量, 仅为AlexNet参数量(6000万) 的1/12, 却有着更高的准确率。下面沿着Inception的进化来一步步了解Inception网络。 Inception是在一些突破性的研究成果之上推出的, 所以有必要从Inception的前身理论开始介绍。 下面先介绍MLP卷积层。
MLP卷积层
MLP卷积层(Mlpconv) 源于2014年ICLR的一篇论文《Network In Network》 。 它改进了传统的CNN网络, 在效果等同的情况下, 参数只是原有的Alexnet网络参数的1/10。卷积层要提升表达能力, 主要依靠增加输出通道数, 每一个输出通道对应一个滤波器,同一个滤波器共享参数只能提取一类特征, 因此一个输出通道只能做一种特征处理。 所以在传统的CNN中会使用尽量多的滤波器, 把原样本中尽可能多的潜在的特征提取出来, 然后再通过池化和大量的线性变化在其中筛选出需要的特征。 这样的代价就是参数太多, 运算太慢, 而且很容易引起过拟合。
MLP卷积层的思想是将CNN高维度特征转成低维度特征, 将神经网络的思想融合在具体的卷积操作当中。 直白的理解就是在网络中再放一个网络, 即, 使每个卷积的通道中包含一个微型的多层网络, 用一个网络来代替原来具体的卷积运算过程(卷积核的每个值与样本对应的像素点相乘, 再将相乘后的所有结果加在一起生成新的像素点的过程) 。 其结构如图1所示。图1 MLP结构图1中a为传统的卷积结构, 图1 b为MLP结构。 相比较而言, 利用多层MLP的微型网络, 对每个局部感受野的神经元进行更加复杂的运算, 而以前的卷积层, 局部感受野的运算仅仅只是一个单层的神经网络。 在MLP网络中比较常见的是使用一个三层的全连接网络结构, 这等效于普通卷积层后再连接1∶1的卷积和ReLU激活函数。
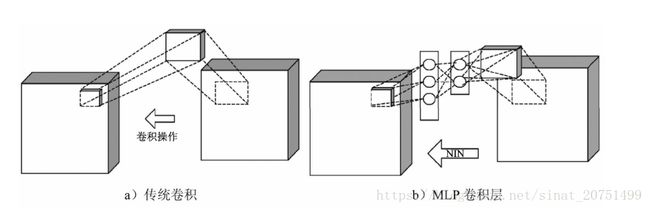
图1
Inception 原始模型
Inception的原始模型是相对于MLP卷积层更为稀疏, 它采用了MLP卷积层的思想, 将中间的全连接层换成了多通道卷积层。 Inception与MLP卷积在网络中的作用一样, 把封装好的Inception作为一个卷积单元, 堆积起来形成了原始的GoogLeNet网络。Inception的结构是将1×1、 3×3、 5×5的卷积核对应的卷积操作和3×3的滤波器对应的池化操作堆叠在一起, 一方面增加了网络的宽度, 另一方面增加了网络对尺度的适应性, 如图2所示。
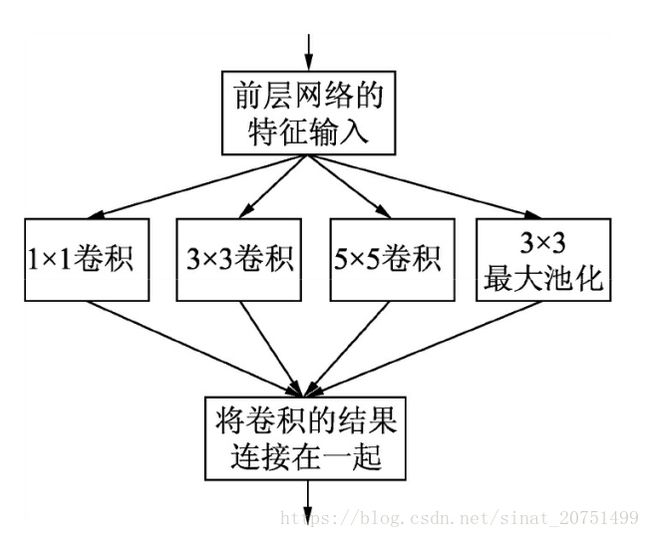 图2
图2
Inception模型中包含了3种不同尺寸的卷积和一个最大池化, 增加了网络对不同尺度的适应性, 这和Multi-Scale的思想类似。 早期计算机视觉的研究中, 受灵长类神经视觉系统的启发, Serre使用不同尺寸的Gabor滤波器处理不同尺寸的图片, Inception v1借鉴了这种思想。Inception v1的论文中指出, Inception模型可以让网络的深度和宽度高效率地扩充, 提升了准确率且不致于过拟合。形象的解释就是Inception模型本身如同大网络中的一个小网络, 其结构可以反复堆叠在一起形成更大网络。
Inception v1模型
Inception v1模型在原有的Inception模型基础上做了一些改进, 原因是由于Inception的原始模型是将所有的卷积核都在上一层的所有输出上来做, 那么5×5的卷积核所需的计算量就比较大, 造成了特征图厚度很大。为了避免这一现象, Inception v1模型在3×3前、 5×5前、 最大池化层后分别加上了1×1的卷积核, 起到了降低特征图厚度的作用(其中1×1卷积主要用来降维) , 网络结构如图3所示。图3 Inception v1模型Inception v1模型中有以下4个分支:
第1个分支对输入进行1×1的卷积, 这其实也是NIN中提出的一个重要结构。 1×1的卷积可以跨通道组织信息, 提高网络的表达能力, 同时可以对输出通道升维和降维。
第2个分支先使用了1×1卷积, 然后连接3×3卷积, 相当于进行了两次特征变换。·
第3个分支与第2个分支类似, 先是1×1的卷积, 然后连接5×5卷积。
第4个分支则是3×3最大池化后直接使用1×1卷积。
可以发现4个分支都用到了1×1卷积, 有的分支只使用1×1卷积, 有的分支在使用了其他尺寸的卷积的同时会再使用1×1卷积, 这是因为1×1卷积的性价比很高, 增加一层特征变换和非线性转化所需的计算量更小。Inception v1模型的4个分支在最后再通过一个聚合操作合并(使用tf.concat函数在输出通道数的维度上聚合) 。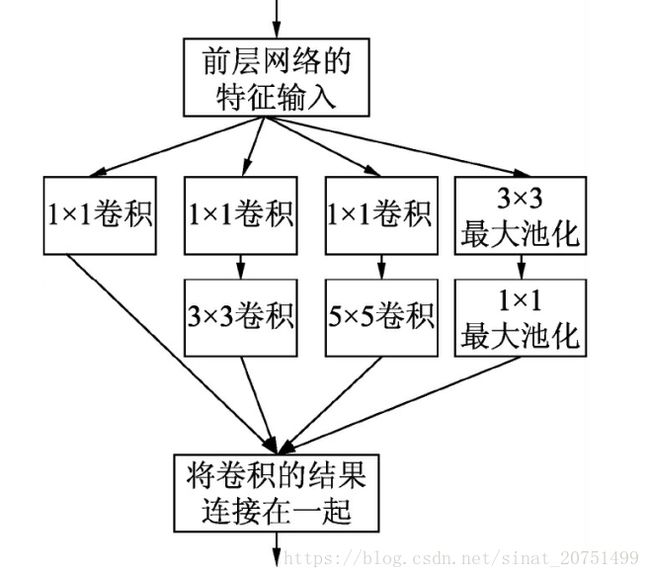 图3
图3
Inception v2模型
Inception v2模型在Inception v1模型基础上应用当时的主流技术, 在卷积之后加入了BN层, 使每一层的输出都归一化处理, 减少了内变协变量的移动问题; 同时还使用了梯了度截断技术, 增加了训练的稳定性。另外, Inception学习了VGG, 用2个3×3的conv替代inception模块中的5×5, 这既降低了参数数量, 也提升了计算速度。 其结构如图4所示

图4
Inception v3模型
Inception v3模型没有再加入其他的技术, 只是将原有的结构进行了调整, 其最重要的一个改进是分解, 将图5中的卷积核变得更小。具体的计算方法是: 将7×7分解成两个一维的卷积(1×7, 7×1) , 3×3的卷积操作也一样(1×3, 3×1) 。 这种做法是基于线性代数的原理, 即一个[n, n]的矩阵, 可以分解成矩阵[n,
1]×矩阵[1, n], 得出的结构如图5所示。

图5
假设有256个特征输入, 256个特征输出, 如果Inception 层只能执行3×3的卷积, 即总共要完成256×256×3×3的卷积(将近589 000次乘积累加运算) 。
如果需要减少卷积运算的特征数量, 将其变为64(即256/4) 个。 则需要先进行256→64 1×1的卷积, 然后在所有Inception的分支上进行64次卷积, 接着再使用一个来自64→256的特征的1×1卷积, 运算的公式如下:
256×64 × 1×1 = 16 000s
64×64 × 3×3 = 36 000s
64×256 × 1×1 = 16 000s
相比于之前的60万, 现在共有7万的计算量, 几乎原有的1/10。
在实际测试中, 这种结构在前几层处理较大特征数据时的效果并不太好, 但在处理中间状态生成的大小在12~20之间的特征数据时效果会非常明显, 也可以大大提升运算速度。 另外, Inception v3还做了其他的变化, 将网络的输入尺寸由224×224变为了299×299, 并增加了卷积核为35×35/17×17/8×8的卷积模块。
Inception v4模型
Inception v4是在Inception模块基础上, 结合残差连接(Residual Connection) 技术的特点进行了结构的优化调整。 Inception-ResNet v2网络与Inception v4网络, 二者性能差别不大, 结构上的区别在于Inception v4中仅仅是在Inception v3基础上做了更复杂的结构变化(从Inception v3的4个卷积模型变为6个卷积模块等) , 但没有使用残差连接。