造轮子系列 —— 方法插桩
今天推荐一个群友开源的插桩框架 —— Mamba ,想学习 Gradle Plugin 和 ASM 的朋友们可以关注一波。
原文作者:codelang
原文地址:https://juejin.im/post/5f0094305188252e851c53c5
开源地址:https://github.com/MRwangqi/Mamba
市面上已经有很多实现方法插桩的框架了,为什么我们还要重复造轮子呢?由于业务拓展时刻在变化,我们不得不去造一个适应业务的轮子,在造轮子之前,我们先列几个比较热门的框架进行比较,列出优缺点,然后再总结自己实现的轮子
方案比较
| 框架 | 性能 | 技术实现 | 方法参数获取 | 混淆 | 范围 |
|---|---|---|---|---|---|
| hugo | 差 | aspectJ | 支持 | 不支持 | java 类 |
| costTime | 好 | asm | 不支持 | 支持 | app 模块 |
| matrix | 好 | asm | 不支持 | 支持 | 所有模块 |
| Mamba | 好 | asm | 支持 | 支持 | 所有模块 |
1、hugo
hugo 是利用 aspectJ 实现的方法插桩,使用很简单,只需要给方法添加 @DebugLog 注解即可获取方法的执行耗时。由于使用的是 aspectJ,只能作用于 java 文件,对于 aar 文件不起作用,并且,获取方法和参数的整个过程非常耗时,具体可以看 enterMethod 和 exitMethod 方法。hugo 也不支持混淆,codeSignature.getName 拿到的是混淆后的方法,无法拿到原函数名,这也就无法做收集统计。可能 hugo 的定位仅仅只是 debug 阶段的统计,从注解 DebugLog 就可以看出。
2、costTime
这是巴神写的一个统计方法耗时的框架,使用的是 asm 进行方法插桩,使用也很简单,只需要给方法添加 @Cost 注解即可,插件会扫描类下面的所有方法是否有添加 @Cost 注解,如果有的话,则对方法进行插桩,插桩效果如下:
System.out.println("========start=========");
TimeUtil.setsStartTime("newFunc", System.nanoTime());
// 原方法执行体
TimeUtil.setEndTime("newFunc", System.nanoTime());
System.out.println(TimeCache.getCostTime("newFunc"));
System.out.println("========end=========");
但探究了一下源码,costTime 仅支持对当前 app module 有效,具体可以看 transfrom 的部分,对于 library 生成的 jar 部分是不做插桩的。
3、Matrix
Matrix 是腾讯的一款 APM 框架,在 matrix-gradle-plugin 模块中实现了对方法的插桩,具体原理可以参考我的文章《Matrix 之 TraceCanary 源码分析》。Matrix 并不会记录方法的名称,而是给每个插桩的方法生成唯一的 methodId,并且生成一份方法与 methodId 映射的配置文件,在做数据上报的时候,只需要上传 methodId 即可,云端只需要通过配置文件解析出 methodId 对应的方法名,即可查看到整个方法调用链,优点当然是不言而喻,数据大小和内存优化做的非常极致,缺点也有,methodId 会随着版本的变化而变化,需要维护每个版本的配置文件,在做数据分析时,需要根据版本号来调整。
4、Mamba
Mamba 的实现类似于 Matrix,但插桩的内容不是 methodId,而是当前的类、方法名和方法参数,插桩效果如下:
public void test() {
long start = System.currentTimeMillis();
Class cls = Test.class;
Mamba.i(cls, "test");
// 原方法体
Mamba.i(cls, "test");
}
Mamba 本身不做逻辑,只将方法体的开始和结束交给实现 IMambaLoader 类来实现。Mamba 还提供了使用 @Track 注解来捕捉方法信息的功能,用于辅助无痕埋点方案参数值的获取功能,插桩效果如下:
// 原方法
@Track
private void open(String t, float a, double b, long c) {
Toast.makeText(this, "What can I say?Mamba out", Toast.LENGTH_SHORT).show();
}
// 插桩之后效果
private void open(String str, float f, double d, long j) {
Class cls = TrackActivity.class;
Mamba.i(cls, "open", str, Float.valueOf(f), Double.valueOf(d), Long.valueOf(j));
Toast.makeText(this, "What can I say?Mamba out", 0).show();
}
缺点就是,基础类型需要装箱成引用类型,存储到 Object 数组中
Mamba 实现
Mamba 采用 gradle-plugin 和 asm 实现的方法插桩,Mamba 会遍历 full project 的 class,并利用 asm 在方法的开始和结束插入字节码。
Mamba 插入的字节码为什么是 Class、MethodName、Method Params 呢?
插入 Class 的主要目的是为了更好的定位方法执行过程,由于各个类会存在相同方法名,会导致调用链不清晰
MethodName 是必要的,由于在插桩时就已记录好方法的名称,即使应用包被混淆,也能正常记录调用链
Method Params 的记录,主要是为了对方法更进一步的捕捉
细说 Method Params 的记录
在业务实践中,想要做到无痕埋点方案是不可能的,有的埋点部分会依赖上下文环境,并且还要记录当前的变量值,所以,我们不得不在业务代码中进行硬编埋点。
为了解决硬编问题,我想到的一个解决方案就是:将需要埋点的地方写成函数调用,然后将需要记录的变量作为函数的参数,然后给函数标记 @Track,然后 Mamba 会根据 @Track 注解自动去实现方法和参数的插桩,我们只需要在 Mamba 的实现类中进行埋点的数据即可。
下面给一份操作示例,需求是:在点击事件中记录 userName 变量
public class MyActivity{
public void onClick(View view){
String userName = editUserName.getText().toString();
updateUser(userName);
// 一般来说,我们可能会直接进行硬编,比如 TrackManager.get().logEvent("获取用户名称",userName)
}
/*
* 更新用户名称
*/
private void updateUser(String userName){
...
}
}
我们来改造一下:
public class MyActivity{
public void onClick(View view){
String userName = editUserName.getText().toString();
updateUser(userName)
}
// 给更新用户添加一个 Track 注解即可
@Track
private void updateUser(String userName){
...
}
}
生成字节码后的结果为:
public class MyActivity{
public void onClick(View view){
String userName = editUserName.getText().toString();
updateUser(userName)
}
@Track
private void updateUser(String userName){
Class cls = MyActivity.class;
Mamba.i(cls, "updateUser", userName);
...
}
}
我们只需要在 Mamba 的实现类中对 class 为 MyActivity,method 为 updateUser 的方法进行判断,并取出 params 值即可,例如:
override fun methodEnter(clazz: Class<*>?, methodName: String?, args: Array?) {
when (clazz) {
MyActivity::class.java -> {
trackMyActivity(methodName, args)
}
}
}
private fun trackMyActivity(methodName: String?, args: Array?){
when(methodName){
"updateUser"->{
// 获取 userName 值
val userName = args!![0] as String
// 使用 TrackManager 进行埋点操作
}
}
}
虽然 @Track 仍然需要在业务代码中进行编辑,但已经是尽量小的侵入业务代码,即使以后不需要记录用户名,我们也无需去删除 @Track 注解,只需要移除 Mamba 实现类中对 updateUser 的判断即可。
那么读者可能会问了,为啥你不直接做自动化收集方法参数,而是使用注解的方式侵入业务?其实,我也想过这种方案,但对于基础类型参数非常的不友好,如果我想统一收集方法参数,就必须使用一个大家都有的父类容器来存,所以,这里定义了 Object 数组来存储参数,但问题又来了,基础类型没有父类你怎么办,只能将基础类型包装成引用类型,也就是将 float 包装成 Float.valueOf() 存进 Object 数组,这种包装会消耗内存,试想,如果对所有的方法参数都进行包装收集,性能就成了问题。所以,这里采用 @Track 注解自己认为要收集的方法。
性能
大家可能会比较关心插桩后的性能问题,我这里列一下测试用例和结果:
1、方法插桩,多次测试耗时为 0 毫秒
2、方法参数插桩,多次测试,耗时大约在 2 毫秒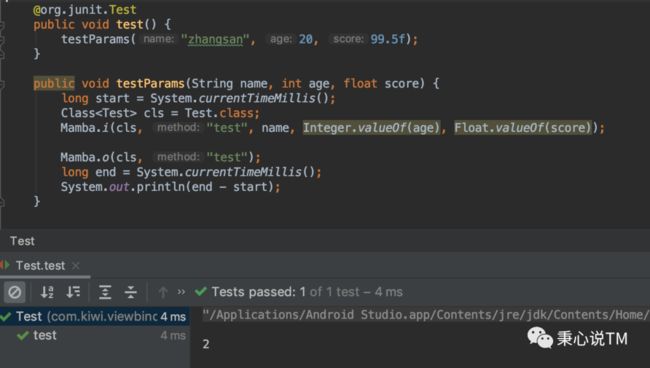
注意
方法的参数收集目前只支持最多 5 个参数。
插桩时还需要为 Mamba 实现类配置 exclude,避免插桩导致方法循环调用
总结
总的来说,各个方案实现都差不多,略微的差异在于业务的不同实现。
Mamba 也提供了两个默认的实现类:
CostTimeLoader : 统计方法耗时
TrackLoader : 捕捉方法信息
具体使用可以查看 Mamba README:https://github.com/MRwangqi/Mamba