Android AudioRecord和AudioTrack介绍
Android音频收集和播放(一)
一、文章说明
这篇文章主要讲述的是Android中使用AudioRecord类和AudioTrack类来进行语音采集和播放相关的知识,在这篇文章中首先介绍的是有关声音的一些概念性知识,然后介绍声音的采集,之后再讲述Android上回声消除的相关步骤,最后介绍的是声音的播放。
二、概念性知识点
在这里关于声音的定义和产生就不再赘述了,如果有对这个感兴趣的朋友可以去了解一下,下面介绍几个听过但是不是很清楚的概念。
麦克风降噪
大集都知道,在现在这个科技盛行的年代,在打电话时,即使一方的环境有些嘈杂,而在电话的另一方也能听的清清楚楚,这主要靠的就是手机降噪技术的发展。目前所使用的手机不仅仅有一个麦克风,而是有2个甚至是3个(iPhone),这多出的麦克风就是降噪的关键。手机麦克风降噪图请看图一:

下面以两个麦克风的情况来说一下麦克风降噪,顶部和底部都各有一个。这两个麦克风都很小,但是两者的作用是有着非常明显的区别,其中底部的麦克风是保证清晰通话的,而顶部的麦克风是用来消除噪音的。
由于顶部和底部在通话时和音源(发出声音的源头)的距离不同,所以两个麦克风拾取的音量大小也是有不同的,利用这个差别,我们就可以过滤掉噪声保留人声了。在打电话时,两个麦克风所拾取的背景噪声音量是基本相同的,而记录的人声会有6dB左右的音量差。顶端麦收集噪声后,通过解码生成补偿信号后就可以用来消除噪音了。
回声
当声投射到距离声源有一段距离的大面积上时,声能的一部分被吸收,而另一部分声能要反射回来,如果听者听到由声源直接发来的声和由反射回来的声的时间间隔超过十分之一秒(在15℃空气中,距声源至少17米处反射),它就能分辨出两个声音这种反射回来的声叫“回声”。如果声速已知,当测得声音从发出到反射回来的时间间隔,就能计算出反射面到声源之间的距离。例如在室温(20℃)时空气中的声速是343米每秒,所以站在声源处的人要听到回声需要障碍物到声源的距离至少17米。
回声消除
很多时候在收集语音的同时也会播放着声音,这就要在语音收集的时候就需要对采集的声音进行回声消除。当在语音收集的时候,如果还同时播放着声音的话,就不能保证采集的声音不包括正在播放的声音,在这种情况下采集的语音即包括原声又包括回声,在这样的恶性循环下,就会使得回声越来越多,最后出现嗡鸣声。
回声消除就是在麦克风录制外音的时候去除掉手机自身播放出来的声音,这样就将播放的声音从采集的声音中过滤出去,从而就避免了回声的产生。图二很好展示了回声消除的机制。
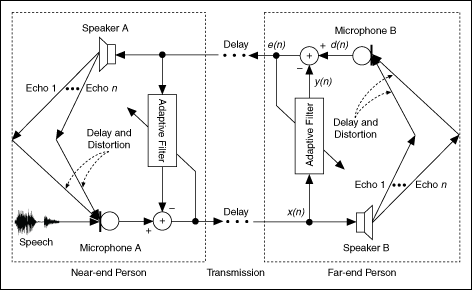
在近端,麦克风会采集到扬声器播放出来的远端声音,假设这路声音为y(n),当然由于需要将远端传来播放出来,我们当然能得到远端传来的声音信号,假设这路声音为x(n)。不难发现x(n)经过扬声器的播放,然后经过空气的传播,最后被麦克风采集,然后变为y(n),x(n)和y(n)具有明显的相关性。假设麦克风采集到的总声音信号为z(n),这时候需要通过自适应滤波器根据x(n)找出z(n)中的y(n),然后从z(n)中过滤掉y(n)。
三、声音采集
麦克风的原理是将将采集的声音转换为模拟电信号,之后将模拟电信号数字化,也就是用高低电平表示的信号(计算机能识别的信号),在Android中有一个AudioRecord类就能录制语音,并将语音转换为PCM数据,声音在经过麦克风转换为模拟电信号并最终又转换为PCM数据,在转换为PCM数据时就要依赖于三个参数,分别是:声道数、采样位数和采样频率。
声道数
很好理解,有单声道和立体声之分,单声道的声音只能使用一个喇叭发声(有的也处理成两个喇叭输出同一个声道的声音),立体声的PCM可以使两个喇叭都发声(一般左右声道有分工) ,更能感受到空间效果。
采样位数
即采样值或取样值(就是将采样样本幅度量化)。它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
在计算机中采样位数一般有8位和16位之分,但有一点请大家注意,8位不是说把纵坐标分成8份,而是分成2的8次方即256份; 同理16位是把纵坐标分成2的16次方65536份。
采样频率
即取样频率,指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。在16位声卡中有22KHz、44KHz等几级,其中,22KHz相当于普通FM广播的音质,44KHz已相当于CD音质了,目前的常用采样频率都不超过48KHz。
既然知道了以上三个概念,就可以由下边的公式得出PCM文件所占容量:
存储量= (采样频率 · 采样位数 · 声道 · 时间)/8 (单位:字节数)。
四、Android声音录制
Android中使用AudioRecord和MediaRecorder进行音频的录制,这里介绍AudioRecord类的使用,有朋友对MediaRecorder感兴趣的就去学习一下。根据上边的介绍可知,需要给AudioRecord传入采样频率、采样位数和声道数,除此之外还需要传入两个参数,一个是声音源,一个是缓冲区大小。在这里缓冲区大小不能小于最小缓冲区大小(下面有介绍)。
权限
在Android中进行音频的录制是需要相应的权限的。在Android 6.0及以上要动态的申请权限。
音频源
下面是Android所支持的音频源:
/**默认声音**/
public static final int DEFAULT = 0;
/**麦克风声音*/
public static final int MIC = 1;
/**通话上行声音*/
public static final int VOICE_UPLINK = 2;
/**通话下行声音*/
public static final int VOICE_DOWNLINK = 3;
/**通话上下行声音*/
public static final int VOICE_CALL = 4;
/**根据摄像头转向选择麦克风*/
public static final int CAMCORDER = 5;
/**对麦克风声音进行声音识别,然后进行录制*/
public static final int VOICE_RECOGNITION = 6;
/**对麦克风中类似ip通话的交流声音进行识别,默认会开启回声消除和自动增益*/
public static final int VOICE_COMMUNICATION = 7;
/**录制系统内置声音*/
public static final int REMOTE_SUBMIX = 8;
在我的项目中音频源来自于麦克风声音。
缓冲区大小
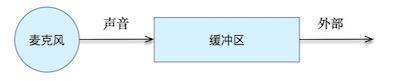
设置完音频源接下来就要设置缓冲区大小。麦克风采集到的音频数据先放置在一个缓冲区里面,之后我们再从这个缓冲区里面读取数据,从而获取到麦克风录制的音频数据。在Android中不同的声道数、采样位数和采样频率会有不同的最小缓冲区大小,当AudioRecord传入的缓冲区大小小于最小缓冲区大小的时候则会初始化失败。大的缓冲区大小可以打开更为平滑的录制效果,相应的也会带来更大一点的延时。如下图所示展示了缓冲区在音频录制和获取中所处的位置:
这里提到的最小缓冲区的大小可以由下边的代码来获得:
AudioRecord.getMinBufferSize(frequency, channelConfiguration,audioEncoding);
当获取最小缓冲区大小失败的时候,会返回相应的负数错误码。
AudioRecord的初始化
下面的代码是AudioRecord的初始化处理
public AudioRecord(int audioSource, int sampleRateInHz, intchannelConfig, int audioFormat, int bufferSizeInBytes) throwsIllegalArgumentException
这个构造方法中的参数上边已经有了讲解。当初始化失败时也就是传入的参数不匹配时就会抛出异常。如果想知道是否初始化成功的话可以获取一下AudioRecord的一个状态量,通过getState()方法可以获取,当返回为STATE_UNINITIALIZED表示未成功初始化,当返回为STATE_INITIALIZED表示已经成功初始化了,初始化成功后就可以进行读取缓冲区中的音频数据的操作了。
读取数据
AudioRecord使用read()方法进行数据的读取操作,正如下面的这个方法:
public int read(@NonNull byte[] audioData, int offsetInBytes,int sizeInBytes) {
returnread(audioData, offsetInBytes, sizeInBytes, READ_BLOCKING);
}
当从缓冲区获取音频数据失败时,会返回负数的错误码。
参数选择
众所周知Android的厂商非常多,这就给开发者们制造了很多的麻烦,最为迫切解决的也就是兼容性的问题,在这方面Android推荐在录音时使用的参数为:
sampleRateInHz = 44100;//采样率
channelConfig = AudioFormat.CHANNEL_CONFIGURATION_MONO;//音道数
audioFormat = AudioFormat.ENCODING_PCM_16BIT//采样位数
五、Android回声消除
在Android中回声消除可以通过三种方式进行处理:1、通过VOICE_COMMUNICATION模式进行录音,自动实现回声消除;2、利用Android自身带的AcousticEchoCanceler进行回声消除处理;3、使用第三方库(Speex、Webrtc)进行回声消除处理(在项目中我所使用的就是Speex进行回声处理的)。
通过第一种方式进行回声消除,需要将AudioManager设置模式为MODE_IN_COMMUNICATION,还需要将麦克风打开。有一点需要特别注意,音频采样率必须设置8000或者16000,通道数必须设为1个(别问为什么,这就是规定)。
AudioManager audioManager =(AudioManager)mContext.getSystemService(Context.AUDIO_SERVICE);
audioManager.setMode(AudioManager.MODE_IN_COMMUNICATION);
audioManager.setSpeakerphoneOn(true);
使用AcousticEchoCanceler过程比较简单,录制声音的时候可以通过AudioRecord得到AudioSessionId,在创建AudioTrack的时候也可以传入一个AudioSessionId,这时候将这个统一的AudioSessionId传入AcousticEchoCanceler,那么AcousticEchoCanceler将根据之前讲过的回声消除的原理进行回声消除。代码如下:

当使用Speex或者Webrtc第三方库进行回声消除的时候,需要将采集到的音频数据传入作为源数据,需要将此刻播放的音频数据传入作为参考数据,然后还需要传入一个延时间隔,这样第三方库就能工作,从而得到回声消除后的声音。因为播放的声音需要传播,而且麦克风采集声音还有相应的缓冲区,因此需要传入一个延时间隔。关于Speex和Webrtc在github上能找到相应的Android ndk库。有兴趣的朋友可以实际动手进行测试一下。
六、Android声音播放
前面介绍了Android的音频录制,下面介绍一下音频的播放,同样Android有两个音频播放的类MediaPlayer和AudioTrack,这里介绍AudioTrack类,其实MediaPlayer在framwork层也实例化了AudioTrack来进行解码生成PCM,然后代理给AudioTrack。
StreamType(指定在流的类型)
这个在构造AudioTrack的第一个参数中使用。这个参数和Android中的AudioManager有关系,涉及到手机上的音频管理策略。Android将系统的声音分为以下几类常见的:
STREAM_ALARM:警告声
STREAM_MUSCI:音乐声,例如music等
STREAM_RING:铃声
STREAM_SYSTEM:系统声音
STREAM_VOCIE_CALL:电话声音
模式类型
这个在构造AudioTrack的最后一个参数中使用。AudioTrack中有MODE_STATIC和MODE_STREAM两种分类。STREAM方式表示由用户通过write方式把数据一次一次得写到audiotrack中。这种方式的缺点就是JAVA层和Native层不断地交换数据,效率损失较大。而STATIC方式表示是一开始创建的时候,就把音频数据放到一个固定的buffer,然后直接传给audiotrack,后续就不用一次次得write了。AudioTrack会自己播放这个buffer中的数据。这种方法对于铃声等体积较小的文件比较合适。
AudioTrack的初始化
下面的代码是AudioTrack的初始化处理
public AudioTrack(int streamType,int sampleRateInHz, int channelConfig,
int audioFormat,int bufferSizeInBytes,int mode)throws IllegalArgumentException
{}这个构造方法中的参数上边已经有了讲解。当初始化失败时也就是传入的参数不匹配时就会抛出异常。
写入数据
AudioTrack使用write()方法将数据写入到audiotrack中,正如下面的这个方法:
public int write(byte[] audioData,int offsetInBytes, int
sizeInBytes) {}offsetInBytes是指要播放的数据是从参数audioData的哪个地方开始。
七、总结
好了,这个第一篇就写到这里了,希望朋友们能对Android录音和播放有一定的了解。后续还会更新。