pytorch + visdom 应用神经网络、CNN 处理手写字体分类
运行环境
系统:win10
cpu:i7-6700HQ
gpu:gtx965m
python : 3.6
pytorch :0.3
普通神经网络
class Nueralnetwork(nn.Module):
def __init__(self,in_dim,hidden1,hidden2,out_dim):
super(Nueralnetwork, self).__init__()
self.layer1 = nn.Linear(in_dim,hidden1)
self.layer2 = nn.Linear(hidden1,hidden2)
self.layer3 = nn.Linear(hidden2,out_dim)
def forward(self,x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
return x
net = Nueralnetwork(28*28,200,100,10)
optimizer = optim.Adam(net.parameters(), lr=LEARNING_RATE)
loss_f = nn.CrossEntropyLoss()第一层200个神经元,第二层100个,运行2个epochs。
gpu运行结果如下:

cpu运行结果如下:

结论:简单的神经网络计算量比简单的逻辑回归大了不少,gpu运算话费时间已经和cpu相仿。
接下来,我们把神经网络换成卷积神经网络(convolution neural network)再来看看gpu和cpu运行的差距,以及准确率的差别。
CNN
代码如下:
import torch
from torch import nn, optim # nn 神经网络模块 optim优化函数模块
from torch.utils.data import DataLoader
from torch.autograd import Variable
from torchvision import transforms, datasets
from visdom import Visdom # 可视化处理模块
import time
import numpy as np
# 可视化app
viz = Visdom()
# 超参数
BATCH_SIZE = 40
LR = 1e-3
EPOCH = 2
# 判断是否使用gpu
USE_GPU = True
if USE_GPU:
gpu_status = torch.cuda.is_available()
else:
gpu_status = False
# 数据引入
train_dataset = datasets.MNIST('./mnist', True, transforms.ToTensor(), download=False)
test_dataset = datasets.MNIST('./mnist', False, transforms.ToTensor())
train_loader = DataLoader(train_dataset, BATCH_SIZE, True)
# 为加快测试,把测试数据从10000缩小到2000
test_data = torch.unsqueeze(test_dataset.test_data, 1)[:1500]
test_label = test_dataset.test_labels[:1500]
# visdom可视化部分数据
viz.images(test_data[:100], nrow=10)
# 为防止可视化视窗重叠现象,停顿0.5秒
time.sleep(0.5)
if gpu_status:
test_data = test_data.cuda()
test_data = Variable(test_data, volatile=True).float()
# 创建线图可视化窗口
line = viz.line(np.arange(10))
# 创建cnn神经网络
class CNN(nn.Module):
def __init__(self, in_dim, n_class):
super(CNN, self).__init__()
self.conv = nn.Sequential(
# channel 为信息高度 padding为图片留白 kernel_size 扫描模块size(5x5)
nn.Conv2d(in_channels=in_dim, out_channels=16,kernel_size=5,stride=1, padding=2),
nn.ReLU(),
# 平面缩减 28x28 >> 14*14
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(16, 32, 3, 1, 1),
nn.ReLU(),
# 14x14 >> 7x7
nn.MaxPool2d(2)
)
self.fc = nn.Sequential(
nn.Linear(32*7*7, 120),
nn.Linear(120, n_class)
)
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
net = CNN(1,10)
if gpu_status :
net = net.cuda()
print("#"*26, "使用gpu", "#"*26)
else:
print("#" * 26, "使用cpu", "#" * 26)
# loss、optimizer 函数设置
loss_f = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=LR)
# 起始时间设置
start_time = time.time()
# 可视化所需数据点
time_p, tr_acc, ts_acc, loss_p = [], [], [], []
# 创建可视化数据视窗
text = viz.text("convolution Nueral Network
")
for epoch in range(EPOCH):
# 由于分批次学习,输出loss为一批平均,需要累积or平均每个batch的loss,acc
sum_loss, sum_acc, sum_step = 0., 0., 0.
for i, (tx, ty) in enumerate(train_loader, 1):
if gpu_status:
tx, ty = tx.cuda(), ty.cuda()
tx = Variable(tx)
ty = Variable(ty)
out = net(tx)
loss = loss_f(out, ty)
sum_loss += loss.data[0]*len(ty)
pred_tr = torch.max(out,1)[1]
sum_acc += sum(pred_tr==ty).data[0]
sum_step += ty.size(0)
# 学习反馈
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 每40个batch可视化一下数据
if i % 40 == 0:
if gpu_status:
test_data = test_data.cuda()
test_out = net(test_data)
# 如果用gpu运行out数据为cuda格式需要.cpu()转化为cpu数据 在进行比较
pred_ts = torch.max(test_out, 1)[1].cpu().data.squeeze()
acc = sum(pred_ts==test_label)/float(test_label.size(0))
print("epoch: [{}/{}] | Loss: {:.4f} | TR_acc: {:.4f} | TS_acc: {:.4f} | Time: {:.1f}".format(epoch+1, EPOCH,
sum_loss/(sum_step), sum_acc/(sum_step), acc, time.time()-start_time))
# 可视化部分
time_p.append(time.time()-start_time)
tr_acc.append(sum_acc/sum_step)
ts_acc.append(acc)
loss_p.append(sum_loss/sum_step)
viz.line(X=np.column_stack((np.array(time_p), np.array(time_p), np.array(time_p))),
Y=np.column_stack((np.array(loss_p), np.array(tr_acc), np.array(ts_acc))),
win=line,
opts=dict(legend=["Loss", "TRAIN_acc", "TEST_acc"]))
# visdom text 支持html语句
viz.text("epoch:{}
Loss:{:.4f}
"
"TRAIN_acc:{:.4f}
TEST_acc:{:.4f}
"
"Time:{:.2f}
".format(epoch, sum_loss/sum_step, sum_acc/sum_step, acc,
time.time()-start_time),
win=text)
sum_loss, sum_acc, sum_step = 0., 0., 0.
gpu运行结果:

可视化:

cpu运行结果:

可视化:
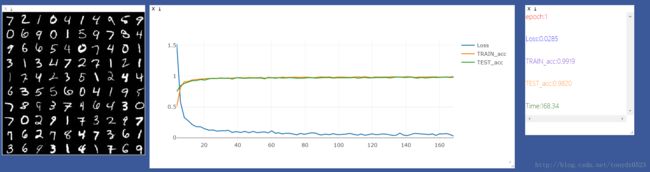
哈哈…… gpu终于翻身把歌唱了,在运行卷积神经网络过程gpu变化不是很大,但是cpu确比之前慢了7倍 。
从准确率上来看,cnn的准确率能达到98%多,而普通神经网络只能达到92%,由于图形很简单,这个差距并没有特别的大,而且我们用的cnn也是最简单的模式。