LeNet-5进行MNIST数据识别
近来翻看经典网络补基础知识,写下这篇博客,本实验的源码是基于Tensorflow框架来写的,采用GPU完成训练,找本实验代码的小伙伴可以去这里下载,实验的数据是转化为png格式的MNIST数据集,小伙伴们可以从这里下载到。笔者不才,不正之处,欢迎斧正。^o^
基于梯度的学习算法可用于合成复杂的决策表面,该表面可以对诸如手写字符之类的高维模式进行分类,并且具有最少的预处理。相较于很多传统的用于进行MNIST数据识别的算法,卷积神经网络在处理多变的2D形状上呈现出了较好的效果。

虽然LeNet是一个小的网络,但却包含了卷积神经网络的基本模块:卷积层、池化层、全连接层。LeNet-5共有7层 ,每层都包含着可训练的参数,每层都有着如图片标注数目的feature map,其中,每个feature map通过一种卷积滤波器提取对应的一种特征。
一、输入层的数据处理
输入图像的尺寸统一归一化为32×32(原始的MNIST中图像的大小是28×28的)。这里的实验数据是.png形式的图片,可以从这里下载。首先加载训练样本和测试样本,在这里还进行了打乱数据的预处理操作。
# 加载数据
train_path = "./mnist/train/"
test_path = "./mnist/test/"
# 读取图片及其标签
def read_image(path):
label_dir = [path+x for x in os.listdir(path) if os.path.isdir(path+x)]
images = []
labels = []
for index,folder in enumerate(label_dir):
for img in glob.glob(folder+'/*.png'):
print("reading the image:%s"%img)
image = io.imread(img)
image = transform.resize(image,(w,h,c))
images.append(image)
labels.append(index)
return np.asarray(images,dtype=np.float32),np.asarray(labels,dtype=np.int32)
train_data,train_label = read_image(train_path) # 训练样本
test_data,test_label = read_image(test_path) # 测试样本
# 打乱训练数据及测试数据
train_image_num = len(train_data)
train_image_index = np.arange(train_image_num)
np.random.shuffle(train_image_index) # 乱序排序
train_data = train_data[train_image_index]
train_label = train_label[train_image_index]
test_image_num = len(test_data)
test_image_index = np.arange(test_image_num)
np.random.shuffle(test_image_index)
test_data = test_data[test_image_index]
test_label = test_label[test_image_index]二、模型构建
1、第一层(卷积层)
输入图片大小:32×32×1
卷积核:5×5×5
输出特征图的大小:28×28×6
# 第一层:卷积层,过滤器的尺寸为5×5,深度为6,不使用全0补充,步长为1。
# 尺寸变化:32×32×1 -> 28×28×6
with tf.variable_scope('layer1-conv1'):
conv1_weights = tf.get_variable('weight',[5,5,c,6],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable('bias',[6],initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor,conv1_weights,strides=[1,1,1,1],padding='VALID')
relu1 = tf.nn.relu(tf.nn.bias_add(conv1,conv1_biases))2、第二层(最大池化层)
输入图片大小:28×28×6
卷积核:2×2
输出特征图的大小:14×14×6
# 第二层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
# 尺寸变化:28×28×6->14×14×6
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')3、第三层(卷积层)
输入图片大小:14×14×6
卷积核:5×5×6
输出特征图的大小:10×10×6
# 第三层:卷积层,过滤器的尺寸为5×5,深度为16,不使用全0补充,步长为1。
# 尺寸变化:14×14×6 -> 10×10×16
with tf.variable_scope('layer3-conv2'):
conv2_weights = tf.get_variable('weight',[5,5,6,16],initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias',[16],initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1,conv2_weights,strides=[1,1,1,1],padding='VALID')
relu2 = tf.nn.relu(tf.nn.bias_add(conv2,conv2_biases))4、第四层(最大池化层)
输入图片大小:10×10×6
卷积核:2×2
输出特征图的大小:5×5×16
# 第四层:池化层,过滤器的尺寸为2×2,使用全0补充,步长为2。
# 尺寸变化:10×10×6->5×5×16
with tf.variable_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
5、第五层(全连接层)
输入特征向量大小:batchsize×400
输出特征图的大小:batchsize×120
在这里,为了预防过拟合,在进行relu函数之前,对参数W加了L2正则化操作,与此同时,在relu函数之后加了Dropout来预防过拟合。
# 第五层:全连接层,nodes=5×5×16=400,400->120的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×400->64×120
# 训练时,引入dropout,dropout在训练时会随机将部分节点的输出改为0,dropout可以避免过拟合问题。
# 这和模型越简单越不容易过拟合思想一致,和正则化限制权重的大小,使得模型不能任意拟合训练数据中的随机噪声,以此达到避免过拟合思想一致。
# 本文最后训练时没有采用dropout,dropout项传入参数设置成了False,因为训练和测试写在了一起没有分离,不过大家可以尝试。
with tf.variable_scope('layer5-fc1'):
fc1_weights = tf.get_variable('weight',[nodes,120],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias',[120],initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped,fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1,0.5)6、第六层(全连接层)
输入特征向量大小:batchsize×120
输出特征图的大小:batchsize×84
在这里,为了预防过拟合,在进行relu函数之前,对参数W加了L2正则化操作,与此同时,在relu函数之后加了Dropout来预防过拟合。
# 第六层:全连接层,120->84的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×120->64×84
with tf.variable_scope('layer6-fc2'):
fc2_weights = tf.get_variable('weight',[120,84],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias',[84],initializer=tf.truncated_normal_initializer(stddev=0.1))
fc2 = tf.nn.relu(tf.matmul(fc1,fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2,0.5)7、第七层(全连接层)
输入特征向量大小:batchsize×84
输出特征图的大小:batchsize×10
在这里,为了预防过拟合,在进行relu函数之前,对参数W加了L2正则化操作,与此同时,在relu函数之后加了Dropout来预防过拟合。
在这里由于最终的分类是10分类问题,所以最终的全连接层的输出是10。
# 第七层:全连接层(近似表示),84->10的全连接
# 尺寸变化:比如一组训练样本为64,那么尺寸变化为64×84->64×10。最后,64×10的矩阵经过softmax之后就得出了64张图片分类于每种数字的概率,
# 即得到最后的分类结果。
with tf.variable_scope('layer7-fc3'):
fc3_weights = tf.get_variable('weight',[84,10],initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None:
tf.add_to_collection('losses',regularizer(fc3_weights))
fc3_biases = tf.get_variable('bias',[10],initializer=tf.truncated_normal_initializer(stddev=0.1))
logit = tf.matmul(fc2,fc3_weights) + fc3_biases三、为了最小化损失函数从而选择的优化算法
# 对网络最后一层的输出做softmax,并针对softmax的输出向量和样本的真值做交叉熵运算
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y,labels=y_)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算损失函数
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 为了最小化损失函数选择的优化策略(Adam)
train_op = tf.train.AdamOptimizer(0.001).minimize(loss)
correct_prediction = tf.equal(tf.cast(tf.argmax(y,1),tf.int32),y_)
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
# 每次获取batch_size个样本进行训练或测试
def get_batch(data,label,batch_size):
for start_index in range(0,len(data)-batch_size+1,batch_size):
slice_index = slice(start_index,start_index+batch_size)
yield data[slice_index],label[slice_index]四、算法执行
1、设置epoch和batchsize
# Main
with tf.Session() as sess:
# 初始化所有变量(权值,偏置等)
sess.run(tf.global_variables_initializer())
# 将所有样本训练10次,每次训练中以64个为一组训练完所有样本。
# train_num可以设置大一些。
epoch = 10 # 迭代次数
batch_size = 64 # BatchSize2、训练与测试
在训练的过程中,每一个Batch都先将训练样本通过切片操作进行取出,然后再进行模型的训练。每一个epoch都会输出当前训练的结果(精度和损失)
for i in range(epoch):
# 训练
train_loss,train_acc,batch_num = 0, 0, 0
for train_data_batch,train_label_batch in get_batch(train_data,train_label,batch_size):
_,err,acc = sess.run([train_op,loss,accuracy],feed_dict={x:train_data_batch,y_:train_label_batch})
train_loss+=err;train_acc+=acc;batch_num+=1
print("train loss:",train_loss/batch_num)
print("train acc:",train_acc/batch_num)
# 测试
test_loss,test_acc,batch_num = 0, 0, 0
for test_data_batch,test_label_batch in get_batch(test_data,test_label,batch_size):
err,acc = sess.run([loss,accuracy],feed_dict={x:test_data_batch,y_:test_label_batch})
test_loss+=err;test_acc+=acc;batch_num+=1
print("test loss:",test_loss/batch_num)
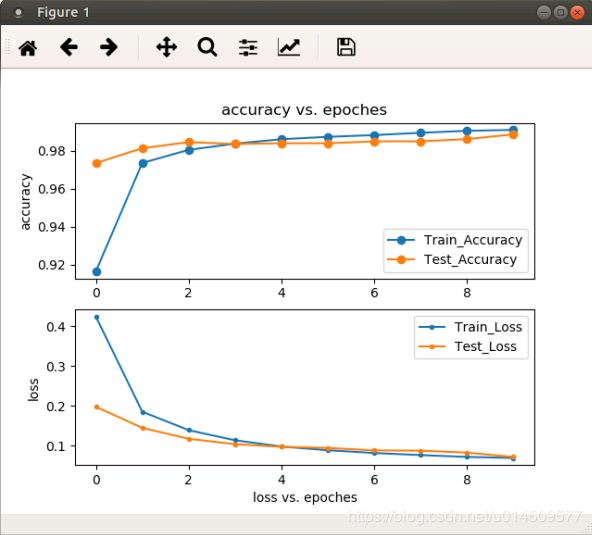
print("test acc:",test_acc/batch_num)3、执行结果
可以看得出当epoch采用10的时候,测试集的准确率一直低于训练集的准确率,说明这个模型是欠拟合的,因此,更应该探索具有更多学习参数的模型,来解决目前的欠拟合的问题。