Java爬虫技术
Jsoup解析html方法,通常被人称之为爬虫技术。(个人认为可能是返回的数据,只有一小部分是我们需要的,造成了数据
的冗余,和网络延迟)。
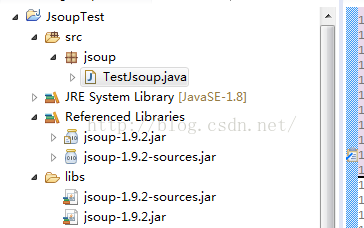
1,下载Jsoup架包,小编在网上找了一个资源下载jsoup架包。(添加到libs后,add to path,其中jsoup-1.9.2-sources.jar的
作用是,当我们需要查看源码的时候,指定到这个包就可以了)
2,Jsoup的应用Api
2.1生成Document文件(本身继承Element)。
A,html字符串转换成一个Document对象:
String html = "First parse "
+ "Parsed HTML into a doc.
";
Document doc = Jsoup.parse(html); Document doc1 = Jsoup.parse(new URL("http://www.baidu.com"), 5000); Document doc = Jsoup.connect("http://jingyan.baidu.com/article/e2284b2b60aceee2e6118d3b.html").get();//也有post方法,基本雷同 File file = new File("C:/Users/songbinwang/webspace/web/WebContent/index/index.html");
Document doc1 = Jsoup.parse(file, "UTF-8");2.2,遍历一个文档Document。
A,DOM方法
查找元素
getElementById(String id)getElementsByTag(String tag)getElementsByClass(String className)getElementsByAttribute(String key)(and related methods)- Element siblings:
siblingElements(),firstElementSibling(),lastElementSibling();nextElementSibling(),previousElementSibling() - Graph:
parent(),children(),child(int index)
元素数据
attr(String key)获取属性attr(String key, String value)设置属性attributes()获取所有属性id(),className()andclassNames()text()获取文本内容text(String value)设置文本内容html()获取元素内HTMLhtml(String value)设置元素内的HTML内容outerHtml()获取元素外HTML内容data()获取数据内容(例如:script和style标签)tag()andtagName()
B,选择器语法查找数据(其实如果只是抓取数据,掌握前面几种就够用了,但小编还是全粘贴了出来,万一真用上了呢哈)
Selector选择器概述
tagname: 通过标签查找元素,比如:ans|tag: 通过标签在命名空间查找元素,比如:可以用fb|name语法来查找#id: 通过ID查找元素,比如:#logo.class: 通过class名称查找元素,比如:.masthead[attribute]: 利用属性查找元素,比如:[href][^attr]: 利用属性名前缀来查找元素,比如:可以用[^data-]来查找带有HTML5 Dataset属性的元素[attr=value]: 利用属性值来查找元素,比如:[width=500][attr^=value],[attr$=value],[attr*=value]: 利用匹配属性值开头、结尾或包含属性值来查找元素,比如:[href*=/path/][attr~=regex]: 利用属性值匹配正则表达式来查找元素,比如:img[src~=(?i)\.(png|jpe?g)]*: 这个符号将匹配所有元素
Selector选择器组合使用
el#id: 元素+ID,比如:div#logoel.class: 元素+class,比如:div.mastheadel[attr]: 元素+class,比如:a[href]- 任意组合,比如:
a[href].highlight ancestor child: 查找某个元素下子元素,比如:可以用.body p查找在"body"元素下的所有p元素parent > child: 查找某个父元素下的直接子元素,比如:可以用div.content > p查找p元素,也可以用body > *查找body标签下所有直接子元素siblingA + siblingB: 查找在A元素之前第一个同级元素B,比如:div.head + divsiblingA ~ siblingX: 查找A元素之前的同级X元素,比如:h1 ~ pel, el, el:多个选择器组合,查找匹配任一选择器的唯一元素,例如:div.masthead, div.logo
伪选择器selectors
:lt(n): 查找哪些元素的同级索引值(它的位置在DOM树中是相对于它的父节点)小于n,比如:td:lt(3)表示小于三列的元素:gt(n):查找哪些元素的同级索引值大于n,比如:div p:gt(2)表示哪些div中有包含2个以上的p元素:eq(n): 查找哪些元素的同级索引值与n相等,比如:form input:eq(1)表示包含一个input标签的Form元素:has(seletor): 查找匹配选择器包含元素的元素,比如:div:has(p)表示哪些div包含了p元素:not(selector): 查找与选择器不匹配的元素,比如:div:not(.logo)表示不包含 class=logo 元素的所有 div 列表:contains(text): 查找包含给定文本的元素,搜索不区分大不写,比如:p:contains(jsoup):containsOwn(text): 查找直接包含给定文本的元素:matches(regex): 查找哪些元素的文本匹配指定的正则表达式,比如:div:matches((?i)login):matchesOwn(regex): 查找自身包含文本匹配指定正则表达式的元素
- 要取得一个属性的值,可以使用
Node.attr(String key)方法 - 对于一个元素中的文本,可以使用
Element.text()方法 - 对于要取得元素或属性中的HTML内容,可以使用
Element.html(), 或Node.outerHtml()方法
Element.id()Element.tagName()Element.className()andElement.hasClass(String className)
3,Jsoup应用实例:
实例一:
try {
Document doc = Jsoup.connect("http://www.baidu.com").get();
System.out.println("Document:\n" + doc);//打印整个百度首页的html
Element form = doc.getElementById("form");//通过id找到元素form
System.out.println("form:\n" + form);
Elements es = form.getAllElements();
System.out.println("Elements:");
for(Element e: es){//遍历整个元素
System.out.println("tag:"+e.tagName() + ",type:"+e.attr("type")+",name:"+e.attr("name") + ",value:"+e.attr("value"));
}
} catch (Exception e) {
// TODO: handle exception
}实例二:
try {
Document doc = Jsoup.connect("http://www.baidu.com").get();
System.out.println(doc);
// Element form = doc.select("form[name]").first();
Element form = doc.select("#form").first();
System.out.println(form);
// Elements es = doc.select(".s_ipt");
// Elements es = doc.select("[^hr]");
// System.out.println(es);
// Elements es = form.getAllElements();
// for(Element e: es){
// System.out.println("tag:"+e.tagName() + ",type:"+e.attr("type")+",name:"+e.attr("name") + ",value:"+e.attr("value"));
// }
Element img = doc.select("img").first();
System.out.println(img.attr("abs:src"));//获得绝对地址
} catch (Exception e) {
// TODO: handle exception
} 由于篇幅原因,只给出实例一的结果(相信大家多试几遍,很快就能掌握的):
Document:

form:
Elements:
tag:form,type:,name:f,value:
tag:input,type:hidden,name:bdorz_come,value:1
tag:input,type:hidden,name:ie,value:utf-8
tag:input,type:hidden,name:f,value:8
tag:input,type:hidden,name:rsv_bp,value:1
tag:input,type:hidden,name:rsv_idx,value:1
tag:input,type:hidden,name:tn,value:baidu
tag:span,type:,name:,value:
tag:input,type:,name:wd,value:
tag:span,type:,name:,value:
tag:input,type:submit,name:,value:百度一下