转载请以链接形式标明出处:
本文出自:103style的博客
base on jdk_1.8.0_77
数据结构源码分析汇总
目录
-
WeakHashMap简介 -
WeakHashMap的常量、成员变量介绍 -
WeakHashMap的构造函数 -
WeakHashMap相关的函数 - 小结
- 参考文章
WeakHashMap简介
WeakHashMap继承于AbstractMap,实现了Map接口。
和 HashMap 一样,
WeakHashMap也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和值都可以是null。
不过
WeakHashMap的键是“弱键”。在WeakHashMap中,当某个键不再正常使用时,会被从WeakHashMap中被自动移除。更精确地说,对于一个给定的键,其映射的存在并不阻止垃圾回收器对该键的丢弃,这就使该键成为可终止的,被终止,然后被回收。某个键被终止时,它对应的键值对也就从映射中有效地移除了。
这个“弱键”的原理呢?大致上就是,通过WeakReference和ReferenceQueue实现的。
WeakHashMap的key是“弱键”,即是WeakReference类型的;ReferenceQueue是一个队列,它会保存被GC回收的“弱键”。实现步骤是:
- 新建
WeakHashMap,将“键值对”添加到WeakHashMap中。
实际上,WeakHashMap是通过数组table保存Entry(键值对);每一个Entry实际上是一个单向链表,即Entry是键值对链表。- 当某“弱键”不再被其它对象引用,并被GC回收时。在GC回收该“弱键”时,这个“弱键”也同时会被添加到ReferenceQueue(queue)队列中。
- 当下一次我们需要操作
WeakHashMap时,会先同步table和queue。table中保存了全部的键值对,而queue中保存被GC回收的键值对;同步它们,就是删除table中被GC回收的键值对。
这就是“弱键”如何被自动从WeakHashMap中删除的步骤了。
和 HashMap 一样,
WeakHashMap是不同步的。可以使用Collections.synchronizedMap方法来构造同步的WeakHashMap。
WeakHashMap的常量、成员变量介绍
和 HashMap 一样得常量:
-
private static final int DEFAULT_INITIAL_CAPACITY = 16;默认初始化的
tab长度 -
private static final int MAXIMUM_CAPACITY = 1 << 30;最大得容量值
-
private static final float DEFAULT_LOAD_FACTOR = 0.75f;默认的加载因子
WeakHashMap的全局变量:
-
Entry保存链表的数组
-
private int size;当前
WeakHashMap中键值对的数量 -
private int threshold;扩容阈值
-
private final float loadFactor;当前
WeakHashMap的加载因子 -
private final ReferenceQueue被清除的
entry引用队列 -
int modCount;修改的次数
-
private static final Object NULL_KEY = new Object();空键
-
private static class Entry继承自
WeakReference的
WeakHashMap的构造函数
public WeakHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public WeakHashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public WeakHashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Initial Capacity: "+
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load factor: "+
loadFactor);
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
table = newTable(capacity);
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
}
public WeakHashMap(Map m) {
this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,
DEFAULT_INITIAL_CAPACITY),
DEFAULT_LOAD_FACTOR);
putAll(m);
}
通过下面的代码计算合适的table长度(大于指定容量的最小的2的指数幂)。其他和 HashMap 类似。
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
WeakHashMap相关的函数
int hash(Object k)//计算key的hash
int indexFor(int h, int length)//计算key再table上的索引
void expungeStaleEntries()//删除引用队列中entry
Entry[] getTable()//获取当前table
void clear()
V get(Object key)
V put(K key, V value)
void putAll(Map map)
V remove(Object key)
boolean isEmpty()
int size()
void resize(int newCapacity)
boolean containsKey(Object key)
boolean containsValue(Object value)
void transfer(Entry[] src, Entry[] dest)
hash(Object k)
函数中注释的解释大致是:
此函数确保在每个位位置仅由常数倍数相差的哈希码具有有限数量的冲突
final int hash(Object k) {
int h = k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
indexFor(int h, int length)
计算对应hash在table的索引位置。
private static int indexFor(int h, int length) {
return h & (length-1);
}
expungeStaleEntries()
删除table中有的 queue中的entry。
private void expungeStaleEntries() {
for (Object x; (x = queue.poll()) != null; ) {
synchronized (queue) {
Entry e = (Entry) x;
int i = indexFor(e.hash, table.length);
Entry prev = table[i];
Entry p = prev;
while (p != null) {
Entry next = p.next;
if (p == e) {
if (prev == e)
table[i] = next;
else
prev.next = next;
e.value = null; // Help GC
size--;
break;
}
prev = p;
p = next;
}
}
}
}
getTable()
获取当前的数组table,并在返回前删除引用队列中entry
private Entry[] getTable() {
expungeStaleEntries();
return table;
}
clear()
先清空引用队列queue中的元素,然后将table中的数据全部设置为null,然后再次清空引用队列queue中的元素。
public void clear() {
// clear out ref queue. We don't need to expunge entries
// since table is getting cleared.
while (queue.poll() != null)
;
modCount++;
Arrays.fill(table, null);
size = 0;
// Allocation of array may have caused GC, which may have caused
// additional entries to go stale. Removing these entries from the
// reference queue will make them eligible for reclamation.
while (queue.poll() != null)
;
}
get(Object key)
通过key的hash找到索引,然后遍历链表找到对应的值。
public V get(Object key) {
Object k = maskNull(key);
int h = hash(k);
Entry[] tab = getTable();
int index = indexFor(h, tab.length);
Entry e = tab[index];
while (e != null) {
if (e.hash == h && eq(k, e.get()))
return e.value;
e = e.next;
}
return null;
}
put(K key, V value)
和 get类似,通过key的hash找到索引,然后检查链表是否有对应的key,有个话更新对应的值。
没有的话就通过new Entry<>(k, value, queue, h, e)构建一个新的节点添加到之前的链表前面。然后再判断是否要扩容。
public V put(K key, V value) {
Object k = maskNull(key);
int h = hash(k);
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
for (Entry e = tab[i]; e != null; e = e.next) {
if (h == e.hash && eq(k, e.get())) {
V oldValue = e.value;
if (value != oldValue)
e.value = value;
return oldValue;
}
}
modCount++;
Entry e = tab[i];
tab[i] = new Entry<>(k, value, queue, h, e);
if (++size >= threshold)
resize(tab.length * 2);
return null;
}
putAll(Map map)
用if (numKeysToBeAdded > threshold)判断是为了避免 m中有重复的key.
public void putAll(Map m) {
int numKeysToBeAdded = m.size();
if (numKeysToBeAdded == 0)
return;
if (numKeysToBeAdded > threshold) {
int targetCapacity = (int)(numKeysToBeAdded / loadFactor + 1);
if (targetCapacity > MAXIMUM_CAPACITY)
targetCapacity = MAXIMUM_CAPACITY;
int newCapacity = table.length;
while (newCapacity < targetCapacity)
newCapacity <<= 1;
if (newCapacity > table.length)
resize(newCapacity);
}
for (Map.Entry e : m.entrySet())
put(e.getKey(), e.getValue());
}
remove(Object key)
和put类似,put是添加或者修改节点,remove则为删除节点。
public V remove(Object key) {
Object k = maskNull(key);
int h = hash(k);
Entry[] tab = getTable();
int i = indexFor(h, tab.length);
Entry prev = tab[i];
Entry e = prev;
while (e != null) {
Entry next = e.next;
if (h == e.hash && eq(k, e.get())) {
modCount++;
size--;
if (prev == e)
tab[i] = next;
else
prev.next = next;
return e.value;
}
prev = e;
e = next;
}
return null;
}
resize(int newCapacity)
扩容操作,如果忽略null元素并处理引用队列导致大量收缩,则恢复旧表。
void resize(int newCapacity) {
Entry[] oldTable = getTable();
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = newTable(newCapacity);
transfer(oldTable, newTable);
table = newTable;
if (size >= threshold / 2) {
threshold = (int)(newCapacity * loadFactor);
} else {
expungeStaleEntries();
transfer(newTable, oldTable);
table = oldTable;
}
}
transfer(Entry[] src, Entry[] dest)
删除src中的null key元素,并将其他元素放到dest中的对应位置。
private void transfer(Entry[] src, Entry[] dest) {
for (int j = 0; j < src.length; ++j) {
Entry e = src[j];
src[j] = null;
while (e != null) {
Entry next = e.next;
Object key = e.get();
if (key == null) {
e.next = null; // Help GC
e.value = null; // " "
size--;
} else {
int i = indexFor(e.hash, dest.length);
e.next = dest[i];
dest[i] = e;
}
e = next;
}
}
}
小结
-
WeakHashMap也是一个数组+单链表的结构。 - 相比
HashMap,WeakHashMap在每次操作时基本上都有去移除被gc回收的key. -
WeakHashMap没有实现HashMap的树化操作 - 在原有链表添加数据时,
HashMap添加在尾端,而WeakHashMap添加在前端。
通过下图我们发现基本所有的数据操作都调用了expungeStaleEntries()来移除被gc回收的key.
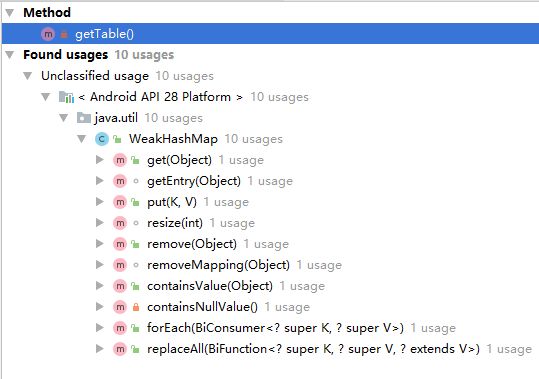
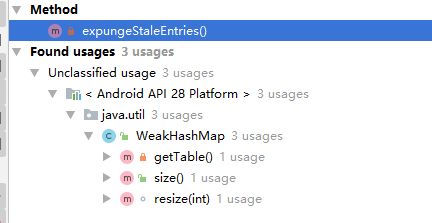
参考文章
- WeakHashMap详细介绍
- WeakHashMap和HashMap的区别
如果觉得不错的话,请帮忙点个赞呗。
以上
扫描下面的二维码,关注我的公众号 Android1024, 点关注,不迷路。
