为什么PostgreSQL比MongoDB还快?
PostgreSQL9.4带来了全新的NoSQL特性,并且根据EnterpriseDB的测试,其加载,插入和查询的性能都已经几倍于MongoDB了。
虽然我是PG的铁杆粉丝,但是关系数据库背负了ACID的重型装甲,在性能上居然能打败轻装上阵的NoSQL数据库总觉得有点离谱。
所以我在自己的环境里验证了一下EnterpriseDB的测试结果,并且小探一下PG取胜的原因。
http://www.enterprisedb.com/postgres-plus-edb-blog/marc-linster/postgres-outperforms-mongodb-and-ushers-new-developer-reality
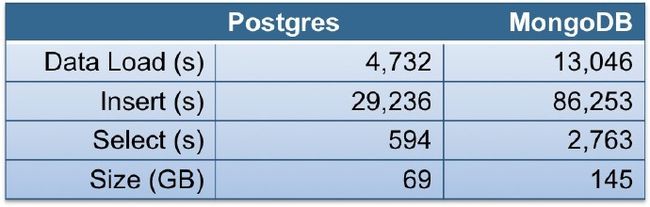
(还可以参考这篇译文: http://blog.jobbole.com/78215/)
为了使测试结果更加单纯,我准备单纯比拼CPU消耗(尽量排除IO和网络的干扰),设定以下测试条件。
1)所有数据都要放进内存
2)C/S都跑在同一台 单机上
所以,只在单机上进行10万条小数据量的测试。
注)EnterpriseDB的测试环境是32G内存的Amazon Web Services M3.2XLARGE实例,总数据量超过内存了。
测试环境
测试环境为个人PC上的VMware虚拟机
PC
CPU:Intel Core i5-3470 3.2G(4核)
MEM:6GB
SSD:OCZ-VERTEX4 128GB(VMware虚拟机所在磁盘,非系统盘)
OS:Win7
VMware虚拟机
CPU:4核
MEM:1GB
OS:CentOS 6.5
PG:PostgreSQL 9.4.0(shared_buffers = 428MB,其他是默认值)
MG: MongoDB 3.0.2
测试步骤
测试步骤非常简单,可以参考:
https://github.com/EnterpriseDB/pg_nosql_benchmark
但是,在测试前,有些东西要改。
1)把数据量减小到10万
pg_nosql_benchmark-master/pg_nosql_benchmark:
declare -a json_rows=(10000000)
==>
declare -a json_rows=(100000)
2)修改 mongo的 一处脚本(注)
pg_nosql_benchmark-master/lib/mongo_func_lib.sh:
collectionsize="$(echo ${output}|awk -F"," '{print $5}'|cut -d":" -f2)"
==>
collectionsize="$(echo ${output}|awk -F"," '{print $ 6}'|cut -d":" -f2)"
注 ) pg_nosql_benchmark原来是基于 MongoDB 2.6设计的,MongoDB 3.0的db.json_tables.stats()输出可能变了,所以这边要修改一下。
测试结果
除了数据加载的性能差距不明显外,其它数据基本和
EnterpriseDB的测试结果一致(MongoDB的
插入时间是PG的4倍,查询时间是PG的2倍多)。
pg_nosql_benchmark:
==>
查看一下数据
点击( 此处 )折叠或打开
查看 数据的总大小,10万条记录共253MB。
点击( 此处 )折叠或打开
3.2 PostgreSQL测试
1)清理旧数据
2)加载数据
执行测试期间的系统负载
注意红色的部分,postgres进程的CPU利用率接近了极限。
3) 建索引
点击( 此处 )折叠或打开
4)查看存储空间大小
PostgreSQL的jsonb存储优化还是不错的,表占了142MB,比原始数据(
253MB)要小。
5)数据查询
点击( 此处 )折叠或打开
看看执行计划
居然是顺序扫描!GIN索引是吃干饭的吗?
仔细一看,原来 EnterpriseDB的测试SQL里把操作符写错了,无法使用GIN索引(想不到PG大牛出没的 EnterpriseDB也会犯这么低级的错误)。下面改下SQL让GIN上场。
效果好了不少啊!
换到外面用psql测。
点击( 此处 )折叠或打开
比以前有数据时快了1倍,但是没有explain (analyze,buffers) 快。原因也很简单,输出结果太多了, 9091条数据在客户端和服务端都要消耗不少资源,而explain (analyze,buffers) 只是简单的在服务端把结果丢弃。
为了排除 处理大量结果数据的干扰,换一个0匹配的查询再试试。
点击( 此处 )折叠或打开
15ms,简直神速啊!
再试试 0匹配的全表扫描。
全表扫描明显慢多了。
6)数据插入
先清数据
插入数据
插入期间的系统负载
postgres进程的CPU利用率达到74.5%。
postgres进程的 CPU利用率为什么还要空这么多?原因也很简单,客户端和服务端是串行处理的,在空闲的时间里,它在等psql。
那么把postgres的psql进程的CPU利用率加起来就是94.1%,确实可以判断达到CPU性能瓶颈了。
等一等!其实这个测试中PG作弊了。
既然是和MongoDB PK普通的插入操作,应该是一个SQL一个事务才对。修改后再测。
查看系统负载。
这次
执行时间也长了1倍,postgres+psql进程的CPU也没用满,才61.5%。CPU的空闲那段时间应该是在等WAL被
刷到磁盘。
(由于这是单并发测试,不可避免会出现CPU空闲;但是在多并发的环境里,只要存储的吞吐和IOPS足够高,是完全可以把CPU撑满的。)
点击( 此处 )折叠或打开
2)加载数据
加载期间的系统负载
值得注意的是系统的瓶颈在mongoimport 进程,而不是mongod进程
,
mongod还有一半的余力。
(数据加载时,执行的单条语句,大量数据,所以 mongoimport 和mongod进程不是串行而是并行执行的关系)
3)建索引
MongoDB建的是btree索引,json中的每个常用的查询属性都要建1个,万一漏了就只能全集合扫描了(在一个无模式的数据模型里却需要建有模式的索引,不是有点讽刺吗?)
。而PostgreSQL的GIN索引确是对整个json建的索引。这样一比较,PostgreSQL的GIN索引简直太牛了(不光
MongoDB,其它数据库也难有能和PG的扩展索引(GIN,GiST,SP-GiST)匹敌的东西吧?)。
4)查看存储空间大小
MongoDB的json存储
比原始数据(
253MB
)稍微大一点,409MB。但是这个409MB是包含预先分配了但还没有使用的空间的,不考虑这部分空间则占了400MB(MongoDB每次扩张的空间量会越来越大,所以有时候单看storageSize不是很精确)。
5)数据查询
点击( 此处 )折叠或打开
查询时间确实长了,比PG慢太多。
但是,不要急,看看资源占用。
看到没,时间都耗在客户端的mongo进程上。因为客户端在处理大量输出结果时消耗了太多的资源。
其实,执行psql时如果不加“-A”选项也会有类似的问题。
这说明什么?说明之前的查询测试结果根本就是误导嘛!(这就好比两个绝顶高手决斗的时候,比拼的却是谁的小弟递枪的速度快。)
为了排除大量数据处理的误导,下面执行一下0匹配的查询。
现在快多了。但是比起PostgreSQL执行相同查询的0.015s还是慢了很多。
再试试0匹配的全表扫描。
MongoDB的全表扫描比PostgreSQL快,
PostgreSQL在相同条件下的执行时间是0.594s
。
6)数据插入
先清数据
插入数据
MongoDB的插入确实挺慢的。
而且如果查看输出的话,还会发现一堆错误,这是由于MongoDB的控制台不允许插入大于4k的文档。
下面看看插入时的系统负载
根据
系统负载,性能瓶颈还是客户端mongo进程。如果要把mongod的负载压满,
MongoDB的性能还可以提升4倍。
http://blog.163.com/digoal@126/blog/static/16387704020151443228780/
http://blog.163.com/digoal@126/blog/static/16387704020151435825593/
http://blog.163.com/digoal@126/blog/static/1638770402015142858224/
http://www.cnblogs.com/lovecindywang/archive/2011/03/02/1969324.html
虽然我是PG的铁杆粉丝,但是关系数据库背负了ACID的重型装甲,在性能上居然能打败轻装上阵的NoSQL数据库总觉得有点离谱。
所以我在自己的环境里验证了一下EnterpriseDB的测试结果,并且小探一下PG取胜的原因。
1. EnterpriseDB的测试结果
以下是EnterpriseDB的测试结果(数据量为5000万)http://www.enterprisedb.com/postgres-plus-edb-blog/marc-linster/postgres-outperforms-mongodb-and-ushers-new-developer-reality
(还可以参考这篇译文: http://blog.jobbole.com/78215/)
2. 我的验证结果
测试观点为了使测试结果更加单纯,我准备单纯比拼CPU消耗(尽量排除IO和网络的干扰),设定以下测试条件。
1)所有数据都要放进内存
2)C/S都跑在同一台 单机上
所以,只在单机上进行10万条小数据量的测试。
注)EnterpriseDB的测试环境是32G内存的Amazon Web Services M3.2XLARGE实例,总数据量超过内存了。
测试环境
测试环境为个人PC上的VMware虚拟机
PC
CPU:Intel Core i5-3470 3.2G(4核)
MEM:6GB
SSD:OCZ-VERTEX4 128GB(VMware虚拟机所在磁盘,非系统盘)
OS:Win7
VMware虚拟机
CPU:4核
MEM:1GB
OS:CentOS 6.5
PG:PostgreSQL 9.4.0(shared_buffers = 428MB,其他是默认值)
MG: MongoDB 3.0.2
测试步骤
测试步骤非常简单,可以参考:
https://github.com/EnterpriseDB/pg_nosql_benchmark
但是,在测试前,有些东西要改。
1)把数据量减小到10万
pg_nosql_benchmark-master/pg_nosql_benchmark:
declare -a json_rows=(10000000)
==>
declare -a json_rows=(100000)
2)修改 mongo的 一处脚本(注)
pg_nosql_benchmark-master/lib/mongo_func_lib.sh:
collectionsize="$(echo ${output}|awk -F"," '{print $5}'|cut -d":" -f2)"
==>
collectionsize="$(echo ${output}|awk -F"," '{print $ 6}'|cut -d":" -f2)"
注 ) pg_nosql_benchmark原来是基于 MongoDB 2.6设计的,MongoDB 3.0的db.json_tables.stats()输出可能变了,所以这边要修改一下。
测试结果
点击(此处)折叠或打开
- -bash-4.1$ sh pg_nosql_benchmark
- PID: 2160 [RUNTIME: 04-12-15 08:15:51] pg_nosql_benchmark: MongoDB Version 3.0.2
- PID: 2160 [RUNTIME: 04-12-15 08:15:51] pg_nosql_benchmark: PostgreSQL Version 9.4.0
- PID: 2160 [RUNTIME: 04-12-15 08:15:51] pg_nosql_benchmark: creating json data.
- PID: 2160 [RUNTIME: 04-12-15 08:17:18] pg_nosql_benchmark: preparing postgresql INSERTs.
- PID: 2160 [RUNTIME: 04-12-15 08:19:02] pg_nosql_benchmark: preparing mongo insert commands.
- PID: 2160 [RUNTIME: 04-12-15 08:20:45] pg_nosql_benchmark: droping database benchmark if exists.
- PID: 2160 [RUNTIME: 04-12-15 08:20:45] pg_nosql_benchmark: creating database benchmark.
- PID: 2160 [RUNTIME: 04-12-15 08:20:46] pg_nosql_benchmark: dropping mongo collection json_tables
- PID: 2160 [RUNTIME: 04-12-15 08:20:46] pg_nosql_benchmark: creating json_tables collection in postgreSQL.
- PID: 2160 [RUNTIME: 04-12-15 08:20:46] pg_nosql_benchmark: loading data in postgresql using sample.json.
- PID: 2160 [RUNTIME: 04-12-15 08:20:57] pg_nosql_benchmark: creating index on postgreSQL collections.
- PID: 2160 [RUNTIME: 04-12-15 08:21:00] pg_nosql_benchmark: testing mongoimport.
- PID: 2160 [RUNTIME: 04-12-15 08:21:14] pg_nosql_benchmark: creating index in mongodb.
- PID: 2160 [RUNTIME: 04-12-15 08:21:19] pg_nosql_benchmark: testing FIRST SELECT in postgresql.
- PID: 2160 [RUNTIME: 04-12-15 08:21:21] pg_nosql_benchmark: testing SECOND SELECT in postgresql.
- PID: 2160 [RUNTIME: 04-12-15 08:21:22] pg_nosql_benchmark: testing THIRD SELECT in postgresql.
- PID: 2160 [RUNTIME: 04-12-15 08:21:22] pg_nosql_benchmark: testing FOURTH SELECT in postgresql.
- PID: 2160 [RUNTIME: 04-12-15 08:21:23] pg_nosql_benchmark: calculating PostgreSQL collection size.
- PID: 2160 [RUNTIME: 04-12-15 08:21:23] pg_nosql_benchmark: testing mongo FIRST SELECT.
- PID: 2160 [RUNTIME: 04-12-15 08:21:27] pg_nosql_benchmark: testing mongo SECOND SELECT.
- PID: 2160 [RUNTIME: 04-12-15 08:21:27] pg_nosql_benchmark: testing mongo THIRD SELECT.
- PID: 2160 [RUNTIME: 04-12-15 08:21:30] pg_nosql_benchmark: testing mongo FOURTH SELECT.
- PID: 2160 [RUNTIME: 04-12-15 08:21:33] pg_nosql_benchmark: calculating the size of mongo collection.
- PID: 2160 [RUNTIME: 04-12-15 08:21:34] pg_nosql_benchmark: dropping mongo collection json_tables
- PID: 2160 [RUNTIME: 04-12-15 08:21:34] pg_nosql_benchmark: testing inserts in mongo
- PID: 2160 [RUNTIME: 04-12-15 08:23:00] pg_nosql_benchmark: droping json object in postgresql.
- PID: 2160 [RUNTIME: 04-12-15 08:23:00] pg_nosql_benchmark: inserting data in postgresql using sample_pg_inserts.json.
- number of rows 100000
- PG COPY (ns) 10886811763
- PG INSERT (ns) 22173081221
- PG SELECT (ns) 1018231815
- PG SIZE (bytes) 148946944
- MONGO IMPORT (ns) 13880183843
- MONGO INSERT (ns) 86577229486
- MONGO SELECT (ns) 2669842035
- MONGO SIZE (bytes) 429092864
3. PostgreSQL真的比MongoDB还快吗
下面模仿
EnterpriseDB的测试方法,单独进行每一项测试。
3.1 测试数据
修改测试脚本后再次执行,将加载和插入的数据文件保留下来。pg_nosql_benchmark:
点击(此处)折叠或打开
- rm -rf ${SAMPLEJSON}*
- rm -rf ${PG_INSERTS}
- rm -rf ${MONGO_INSERTS}
点击(此处)折叠或打开
- #rm -rf ${SAMPLEJSON}*
- #rm -rf ${PG_INSERTS}
- #rm -rf ${MONGO_INSERTS}
查看一下数据
点击( 此处 )折叠或打开
- -bash-4.1$ head -1 sample.json
- { "name" : "AC33929 Phone", "brand" : "ACME1415", "type" : "phone", "price" : 200, "warranty_years" : 1, "available" : true, "description": "Lorem ipsum dolor sit amet, consectetur adipiscing elit. Proin eget elit ut nulla tempor viverra vel eu nulla. Sed luctus porttitor urna, ac dapibus velit fringilla et. Donec iaculis, dolor a vehicula dictum, augue neque suscipit augue, nec mollis massa neque in libero. Donec sed dapibus magna. Pellentesque at condimentum dolor. In nunc nibh, dignissim in risus a, blandit tincidunt velit. Vestibulum rutrum tempus sem eget tempus. Mauris sollicitudin purus auctor dolor vestibulum, vitae pulvinar neque suscipit. Cum sociis natoque penatibus et magnis dis parturient montes, nascetur ridiculus mus. Phasellus lacus turpis, vulputate at adipiscing viverra, ultricies at lectus. Pellentesque ut porta leo, vel eleifend neque. Nunc sagittis metus at ante pellentesque, ut condimentum libero semper. In hac habitasse platea dictumst. In dapibus posuere posuere. Fusce vulputate augue eget tellus molestie, vitae egestas ante malesuada. Phasellus nunc mi, faucibus at elementum pharetra, aliquet a enim. In purus est, vulputate in nibh quis, faucibus dapibus magna. In accumsan libero velit, eu accumsan sem commodo id. In fringilla tempor augue, et feugiat erat convallis et. Sed aliquet eget ipsum eu vestibulum.Curabitur blandit leo nec condimentum semper. Mauris lectus sapien, rutrum a tincidunt id, euismod ac elit. Mauris suscipit et arcu et auctor. Quisque mollis magna vel mi viverra rutrum. Nulla non pretium magna. Cras sed tortor non tellus rutrum gravida eu at odio. Aliquam cursus fermentum erat, nec ullamcorper sem gravida sit amet. Donec viverra, erat vel ornare pulvinar, est ipsum accumsan massa, eu tristique lorem ante nec tortor. Sed suscipit iaculis faucibus. Maecenas a suscipit ligula, vitae faucibus turpis.Cras sed tellus auctor, tempor leo eu, molestie leo. Suspendisse ipsum tellus, egestas et ultricies eu, tempus a arcu. Cras laoreet, est dapibus consequat varius, nisi nisi placerat leo, et dictum ante tortor vitae est. Duis eu urna ac felis ullamcorper rutrum. Quisque iaculis, enim eget sodales vehicula, magna orci dignissim eros, nec volutpat massa urna in elit. In interdum pellentesque risus, feugiat pulvinar odio eleifend sit amet. Quisque congue libero quis dolor faucibus, a mollis nisl tempus." }
查看 数据的总大小,10万条记录共253MB。
点击( 此处 )折叠或打开
- -bash-4.1$ ls -l *.json
- -rw-r--r-- 1 postgres postgres 264993924 Apr 12 08:17 sample.json
- -rw-r--r-- 1 postgres postgres 267493911 Apr 12 08:20 sample_mongo_inserts.json
- -rw-r--r-- 1 postgres postgres 269493962 Apr 12 08:19 sample_pg_inserts.json
3.2 PostgreSQL测试
1)清理旧数据
点击(此处)折叠或打开
- benchmark=# drop table json_tables;
- DROP TABLE
- benchmark=# create table json_tables(data jsonb);
- CREATE TABLE
2)加载数据
点击(此处)折叠或打开
- -bash-4.1$ cat sample.json |time -p psql benchmark -c "copy json_tables from stdin;"
- real 10.00
- user 0.00
- sys 0.35
执行测试期间的系统负载
点击(此处)折叠或打开
- [root@hanode1 ~]# top
- top - 09:12:31 up 1 day, 12:12, 5 users, load average: 0.15, 0.03, 0.01
- Tasks: 160 total, 2 running, 158 sleeping, 0 stopped, 0 zombie
Cpu(s): 14.3%us, 13.3%sy, 0.0%ni, 70.0%id, 1.9%wa, 0.1%hi, 0.4%si, 0.0%st
Mem: 1019320k total, 942632k used, 76688k free, 9768k buffers
Swap: 2064376k total, 80232k used, 1984144k free, 840444k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
30622 postgres 20 0 588m 34m 32m R 93.4 3.5 0:08.00 postgres
30619 postgres 20 0 98.6m 568 464 S 13.3 0.1 0:00.99 cat
17197 postgres 20 0 587m 212m 211m S 10.3 21.3 0:05.91 postgres
17199 postgres 20 0 586m 14m 13m S 5.0 1.4 0:03.26 postgres
30621 postgres 20 0 167m 2496 1984 S 3.3 0.2 0:00.30 psql
22 root 20 0 0 0 0 S 0.3 0.0 1:13.42 events/3
35 root 20 0 0 0 0 S 0.3 0.0 0:01.84 kblock
3) 建索引
点击( 此处 )折叠或打开
- -bash-4.1$ time -p psql benchmark -c "create index json_tables_idx on json_tables using gin(data);"
- CREATE INDEX
- real 2.71
- user 0.00
- sys 0.00
4)查看存储空间大小
点击(此处)折叠或打开
- benchmark=# select pg_relation_size('json_tables');
- pg_relation_size
- ------------------
- 148946944
- (1 row)
-
- benchmark=# select pg_relation_size('json_tables_idx');
- pg_relation_size
- ------------------
- 51134464
- (1 row)
5)数据查询
点击( 此处 )折叠或打开
- -bash-4.1$ time psql -qAt benchmark -c "SELECT data FROM json_tables WHERE (data->>'brand') = 'ACME';" >/dev/null
-
- real 0m0.784s
- user 0m0.044s
- sys 0m0.032s
看看执行计划
点击(此处)折叠或打开
- benchmark=# explain (analyze,buffers) SELECT data FROM json_tables WHERE (data->>'brand') = 'ACME';
- QUERY PLAN
- -------------------------------------------------------------------------------------------------------------------
- Seq Scan on json_tables (cost=0.00..19682.01 rows=500 width=1262) (actual time=0.192..486.710 rows=9091 loops=1)
- Filter: ((data ->> 'brand'::text) = 'ACME'::text)
- Rows Removed by Filter: 90910
- Buffers: shared hit=2304 read=15878
- Planning time: 0.645 ms
- Execution time: 487.951 ms
- (6 rows)
居然是顺序扫描!GIN索引是吃干饭的吗?
仔细一看,原来 EnterpriseDB的测试SQL里把操作符写错了,无法使用GIN索引(想不到PG大牛出没的 EnterpriseDB也会犯这么低级的错误)。下面改下SQL让GIN上场。
点击(此处)折叠或打开
- benchmark=# explain (analyze,buffers) SELECT data FROM json_tables WHERE data @> '{"brand":"ACME"}';
- QUERY PLAN
- ------------------------------------------------------------------------------------------------------------------------------
- Bitmap Heap Scan on json_tables (cost=28.78..407.78 rows=100 width=1262) (actual time=3.612..47.001 rows=9091 loops=1)
- Recheck Cond: (data @> '{"brand": "ACME"}'::jsonb)
- Heap Blocks: exact=9091
- Buffers: shared hit=9110
- -> Bitmap Index Scan on json_tables_idx (cost=0.00..28.75 rows=100 width=0) (actual time=2.162..2.162 rows=9091 loops=1)
- Index Cond: (data @> '{"brand": "ACME"}'::jsonb)
- Buffers: shared hit=19
- Planning time: 0.175 ms
- Execution time: 47.690 ms
- (9 rows)
换到外面用psql测。
点击( 此处 )折叠或打开
- -bash-4.1$ time psql -qAt benchmark -c "SELECT data FROM json_tables WHERE data @> '{\"brand\":\"ACME\"}'" >/dev/null
-
- real 0m0.326s
- user 0m0.047s
- sys 0m0.031s
比以前有数据时快了1倍,但是没有explain (analyze,buffers) 快。原因也很简单,输出结果太多了, 9091条数据在客户端和服务端都要消耗不少资源,而explain (analyze,buffers) 只是简单的在服务端把结果丢弃。
为了排除 处理大量结果数据的干扰,换一个0匹配的查询再试试。
点击( 此处 )折叠或打开
- -bash-4.1$ time psql -qAt benchmark -c "SELECT data FROM json_tables WHERE data @> '{\"brand\":\"ACME111\"}'" >/dev/null
-
- real 0m0.015s
- user 0m0.005s
- sys 0m0.002s
再试试 0匹配的全表扫描。
点击(此处)折叠或打开
- -bash-4.1$ time psql -qAt benchmark -c "set enable_bitmapscan=false;SELECT data FROM json_tables WHERE data @> '{\"brand\":\"ACME111\"}'"
-
- real 0m0.594s
- user 0m0.002s
- sys 0m0.006s
6)数据插入
先清数据
点击(此处)折叠或打开
- benchmark=# truncate json_tables;
- TRUNCATE TABLE
插入数据
点击(此处)折叠或打开
- -bash-4.1$ time -p psql -qAt benchmark --single-transaction -f sample_pg_inserts.json
- real 20.77
- user 1.23
- sys 2.80
插入期间的系统负载
点击(此处)折叠或打开
- [root@hanode1 ~]# top
top - 09:58:31 up 1 day, 12:58, 5 users, load average: 0.23, 0.05, 0.02
Tasks: 161 total, 3 running, 158 sleeping, 0 stopped, 0 zombie
Cpu(s): 17.0%us, 8.0%sy, 0.0%ni, 71.7%id, 3.0%wa, 0.0%hi, 0.3%si, 0.0%st
Mem: 1019320k total, 936824k used, 82496k free, 11420k buffers
Swap: 2064376k total, 80128k used, 1984248k free, 833644k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2891 postgres 20 0 587m 110m 109m R 74.5 11.1 0:07.45 postgres
2890 postgres 20 0 167m 2600 2044 R 19.6 0.3 0:01.87 psql
17197 postgres 20 0 587m 212m 211m S 3.3 21.3 0:06.55 postgres
17199 postgres 20 0 586m 14m 13m S 3.0 1.4 0:03.54 postgres
17198 postgres 20 0 586m 2648 2512 S 0.3 0.3 0:01.09 postgres
25933 root 20 0 15036 1088 804 R 0.3 0.1 3:01.30 top
1 root 20 0 19356 816 648 S 0.0 0.1 0:01.18 init
postgres进程的 CPU利用率为什么还要空这么多?原因也很简单,客户端和服务端是串行处理的,在空闲的时间里,它在等psql。
那么把postgres的psql进程的CPU利用率加起来就是94.1%,确实可以判断达到CPU性能瓶颈了。
等一等!其实这个测试中PG作弊了。
既然是和MongoDB PK普通的插入操作,应该是一个SQL一个事务才对。修改后再测。
点击(此处)折叠或打开
- -bash-4.1$ time -p psql -qAt benchmark -f sample_pg_inserts.json
- real 43.64
- user 0.80
- sys 2.89
查看系统负载。
点击(此处)折叠或打开
- [root@hanode1 ~]# top
top - 11:33:20 up 1 day, 14:33, 5 users, load average: 0.22, 0.05, 0.02
Tasks: 157 total, 2 running, 155 sleeping, 0 stopped, 0 zombie
Cpu(s): 2.1%us, 14.1%sy, 0.0%ni, 71.7%id, 10.2%wa, 0.1%hi, 1.8%si, 0.0%st
Mem: 1019320k total, 947744k used, 71576k free, 8044k buffers
Swap: 2064376k total, 67764k used, 1996612k free, 846260k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
12577 postgres 20 0 587m 89m 88m D 52.9 9.0 0:08.94 postgres
12576 postgres 20 0 167m 2596 2040 S 8.6 0.3 0:01.35 psql
12135 postgres 20 0 586m 48m 47m S 3.0 4.9 0:00.11 postgres
34 root 20 0 0 0 0 S 1.0 0.0 0:02.83 kblockd/0
36 root 20 0 0 0 0 S 0.3 0.0 0:02.63 kblockd/2
59 root 20 0 0 0 0 R 0.3 0.0 0:11.01 kswapd0
(由于这是单并发测试,不可避免会出现CPU空闲;但是在多并发的环境里,只要存储的吞吐和IOPS足够高,是完全可以把CPU撑满的。)
3.3 MongoDB
1)清理旧数据点击( 此处 )折叠或打开
- > db.json_tables.drop()
- true
2)加载数据
点击(此处)折叠或打开
- -bash-4.1$ time -p mongoimport --type json --collection json_tables --db benchmark sample.json >/dev/null 2>/dev/null
- real 10.22
- user 7.44
- sys 5.15
加载期间的系统负载
点击(此处)折叠或打开
- [root@hanode1 ~]# top
top - 10:15:50 up 1 day, 13:15, 5 users, load average: 0.16, 0.03, 0.01
Tasks: 152 total, 1 running, 151 sleeping, 0 stopped, 0 zombie
Cpu(s): 17.4%us, 18.7%sy, 0.0%ni, 57.8%id, 5.3%wa, 0.2%hi, 0.5%si, 0.0%st
Mem: 1019320k total, 895156k used, 124164k free, 1532k buffers
Swap: 2064376k total, 65560k used, 1998816k free, 428380k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
4673 postgres 20 0 694m 222m 3436 S 89.8 22.4 0:05.53 mongoimport
4015 postgres 20 0 2771m 290m 142m S 49.5 29.2 0:04.29 mongod
(数据加载时,执行的单条语句,大量数据,所以 mongoimport 和mongod进程不是串行而是并行执行的关系)
3)建索引
点击(此处)折叠或打开
- -bash-4.1$ echo "db.json_tables.ensureIndex( { \"name\": 1})" |time -p mongo benchmark >/dev/null
- real 1.35
- user 0.03
- sys 0.02
- -bash-4.1$ echo "db.json_tables.ensureIndex( { \"type\": 1})" |time -p mongo benchmark >/dev/null
- real 0.58
- user 0.07
- sys 0.01
- -bash-4.1$ echo "db.json_tables.ensureIndex( { \"brand\": 1})" |time -p mongo benchmark >/dev/null
- real 0.50
- user 0.03
- sys 0.01
4)查看存储空间大小
点击(此处)折叠或打开
- > db.json_tables.stats()
- {
- "ns" : "benchmark.json_tables",
- "count" : 100001,
- "size" : 419640560,
- "avgObjSize" : 4196,
- "numExtents" : 16,
- "storageSize" : 429092864,
- "lastExtentSize" : 114012160,
- "paddingFactor" : 1,
- "paddingFactorNote" : "paddingFactor is unused and unmaintained in 3.0. It remains hard coded to 1.0 for compatibility only.",
- "userFlags" : 1,
- "capped" : false,
- "nindexes" : 4,
- "totalIndexSize" : 12452048,
- "indexSizes" : {
- "_id_" : 3262224,
- "name_1" : 3899952,
- "type_1" : 3442096,
- "brand_1" : 1847776
- },
- "ok" : 1
- }
5)数据查询
点击( 此处 )折叠或打开
- -bash-4.1$ echo "DBQuery.shellBatchSize = 10000000000;db.json_tables.find({ brand: 'ACME'})"|time -p mongo benchmark >/dev/null
- real 3.62
- user 3.53
- sys 0.09
但是,不要急,看看资源占用。
点击(此处)折叠或打开
- [root@hanode1 ~]# top
top - 10:55:46 up 1 day, 13:55, 5 users, load average: 0.13, 0.04, 0.01
Tasks: 152 total, 2 running, 150 sleeping, 0 stopped, 0 zombie
Cpu(s): 24.7%us, 0.4%sy, 0.0%ni, 74.8%id, 0.0%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 1019320k total, 935684k used, 83636k free, 1464k buffers
Swap: 2064376k total, 66976k used, 1997400k free, 615840k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8773 postgres 20 0 752m 67m 9052 R 100.4 6.8 0:03.20 mongo
4015 postgres 20 0 2803m 830m 663m S 0.7 83.4 0:26.46 mongod
1424 root -2 0 85108 1448 1256 S 0.3 0.1 0:19.60 lrmd
1425 hacluste -2 0 89600 1496 1208 S 0.3 0.1 0:25.34 attrd
25911 root 20 0 98.0m 1104 972 S 0.3 0.1 0:40.12 sshd
1 root 20 0 19356 812 660 S 0.0 0.1 0:01.19 init
其实,执行psql时如果不加“-A”选项也会有类似的问题。
点击(此处)折叠或打开
- -bash-4.1$ time psql -qt -p 5433 benchmark -c "SELECT data FROM json_tables WHERE (data->>'brand') = 'ACME';" >/dev/null
-
- real 0m2.124s
- user 0m1.401s
- sys 0m0.066s
这说明什么?说明之前的查询测试结果根本就是误导嘛!(这就好比两个绝顶高手决斗的时候,比拼的却是谁的小弟递枪的速度快。)
为了排除大量数据处理的误导,下面执行一下0匹配的查询。
点击(此处)折叠或打开
- -bash-4.1$ echo "DBQuery.shellBatchSize = 10000000000;db.json_tables.find({ brand: 'ACME111'})"|time -p mongo benchmark >/dev/null
- real 0.06
- user 0.03
- sys 0.01
再试试0匹配的全表扫描。
点击(此处)折叠或打开
- -bash-4.1$ echo "db.json_tables.dropIndexes()"|mongo benchmark
- MongoDB shell version: 3.0.2
- connecting to: benchmark
- {
- "nIndexesWas" : 4,
- "msg" : "non-_id indexes dropped for collection",
- "ok" : 1
- }
- -bash-4.1$ echo "DBQuery.shellBatchSize = 10000000000;db.json_tables.find({ brand: 'ACME111'})"|time -p mongo benchmark >/dev/null
- real 0.24
- user 0.03
- sys 0.02
6)数据插入
先清数据
点击(此处)折叠或打开
- -bash-4.1$ echo "db.json_tables.drop()"|mongo benchmark
- MongoDB shell version: 3.0.2
- connecting to: benchmark
- true
- bye
插入数据
点击(此处)折叠或打开
- -bash-4.1$ time mongo benchmark --quiet sample_mongo_inserts.json >/dev/null
-
- real 1m27.591s
- user 0m29.663s
- sys 0m48.646s
而且如果查看输出的话,还会发现一堆错误,这是由于MongoDB的控制台不允许插入大于4k的文档。
点击(此处)折叠或打开
- 2015-04-12T11:19:08.680+0800 E QUERY SyntaxError: Unexpected token ILLEGAL
- 2015-04-12T11:19:08.681+0800 E QUERY SyntaxError: Unexpected identifier
- WriteResult({ "nInserted" : 1 })
- WriteResult({ "nInserted" : 1 })
- WriteResult({ "nInserted" : 1 })
下面看看插入时的系统负载
点击(此处)折叠或打开
- [root@hanode1 ~]# top
top - 11:20:26 up 1 day, 14:20, 5 users, load average: 0.00, 0.00, 0.00
Tasks: 151 total, 2 running, 149 sleeping, 0 stopped, 0 zombie
Cpu(s): 3.3%us, 1.9%sy, 0.0%ni, 71.1%id, 4.9%wa, 0.0%hi, 18.7%si, 0.0%st
Mem: 1019320k total, 948452k used, 70868k free, 4076k buffers
Swap: 2064376k total, 68296k used, 1996080k free, 632796k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
11269 postgres 20 0 753m 66m 9224 R 89.6 6.7 0:15.23 mongo
4015 postgres 20 0 2803m 534m 371m S 22.6 53.7 0:38.06 mongod
4. 总结
测试数据总结如下(并根据服务端进程CPU的消耗量进行性能对比):
*1)考虑到数据加载经常是单线程操作,不能完全无视mongoimport的瓶颈,这一局应该算是平手。
*2)3个索引的总Size(MB)
这个结果和 EnterpriseDB的测试结果有很大出入。
1)数据加载
从服务端资源消耗的角度看,是 MongoDB的性能是 PostgreSQL的2倍。但是如果数据加载不能很好的并发展开,让mongoimport成为了瓶颈,那应该算打平。
另外, EnterpriseDB的 数据加载的测试结果和我的结果差异比较大,可能是因为EnterpriseDB的测试中,数据量超过了系统内存量,IO对测试结果的影响开始显现。
2)数据插入
从 服务端 资源消耗 的角度看,两者其实相差不大。EnterpriseDB的测试结果被mongo客户端的性能瓶颈绑架了。
3)数据查询
对无匹配数据(或少量匹配数据)的索引查询, PostgreSQL的性能是MongoDB的4倍(这一点也有点令人不解,同样是走索引的单点查询,为什么差距就这么大呢?)。
虽然EnterpriseDB的测试结果也表明PostgreSQL的性能是MongoDB 4倍左右,但EnterpriseDB的测试方法是有问题的。
4)数据大小
MongoDB的数据大小大约是 PostgreSQL的3倍,这和 EnterpriseDB的测试结果是一致的。
PostgreSQL在NoSQL方面的表现确实抢眼。
PostgreSQL不仅是SQL+NoSQL+ACID的完美组合,性能还比
MongoDB技高一筹(分布式集群上MongoDB更有优势)。| PostgreSQL | MongoDB | PK结果 | |||||
| 测试数据 | 服务端进程 CPU利用率 |
服务端进程 CPU占用时间 |
测试数据 | 服务端进程 CPU利用率 |
服务端进程 CPU占用时间 |
||
| Data Load(s) | 10 | 93.40% | 9.34 | 10.22 | 49.50% | 5.06 | MongoDB胜出(*1) |
| Insert(s) | 20.77 | 74.50% | 15.47 | - | - | - | 不具可比性 |
| 每SQL事务Insert(s) | 43.64 | 52.90% | 23.09 | 87.591 | 22.60% | 19.80 | MongoDB胜出 |
| 全表扫描Select(s) | 0.784 | - | - | - | - | - | 不具可比性 |
| Select(s) | 0.326 | - | - | 3.62 | 0.70% | 0.03 | 不具可比性 |
| 0匹配Select(s) | 0.015 | - | - | 0.06 | - | - | PostgreSQL胜出 |
| 0匹配全表扫描Select(s) | 0.594 | - | - | 0.24 | - | - | 不具可比性 |
| Size(MB) | 142 | - | - | 409 | - | - | PostgreSQL胜出 |
| 索引Size(MB) | 49 | - | - | 9(*2) | - | - | 不具可比性 |
*2)3个索引的总Size(MB)
这个结果和 EnterpriseDB的测试结果有很大出入。
1)数据加载
从服务端资源消耗的角度看,是 MongoDB的性能是 PostgreSQL的2倍。但是如果数据加载不能很好的并发展开,让mongoimport成为了瓶颈,那应该算打平。
另外, EnterpriseDB的 数据加载的测试结果和我的结果差异比较大,可能是因为EnterpriseDB的测试中,数据量超过了系统内存量,IO对测试结果的影响开始显现。
2)数据插入
从 服务端 资源消耗 的角度看,两者其实相差不大。EnterpriseDB的测试结果被mongo客户端的性能瓶颈绑架了。
3)数据查询
对无匹配数据(或少量匹配数据)的索引查询, PostgreSQL的性能是MongoDB的4倍(这一点也有点令人不解,同样是走索引的单点查询,为什么差距就这么大呢?)。
虽然EnterpriseDB的测试结果也表明PostgreSQL的性能是MongoDB 4倍左右,但EnterpriseDB的测试方法是有问题的。
4)数据大小
MongoDB的数据大小大约是 PostgreSQL的3倍,这和 EnterpriseDB的测试结果是一致的。
6. 参考
http://www.enterprisedb.com/postgres-plus-edb-blog/marc-linster/edb-makes-open-call-postgres-nosql-performance-benchmarkshttp://blog.163.com/digoal@126/blog/static/16387704020151443228780/
http://blog.163.com/digoal@126/blog/static/16387704020151435825593/
http://blog.163.com/digoal@126/blog/static/1638770402015142858224/
http://www.cnblogs.com/lovecindywang/archive/2011/03/02/1969324.html