推荐问题中ID类特征的处理办法
ID类特征处理办法
- 什么是id类特征
- onehot
- tfidf
- ID类特征embedding
- embedding直接嵌入到模型中
- ids通过上下文关系转化为embedding
什么是id类特征
举腾讯2020年的广告大赛为例子
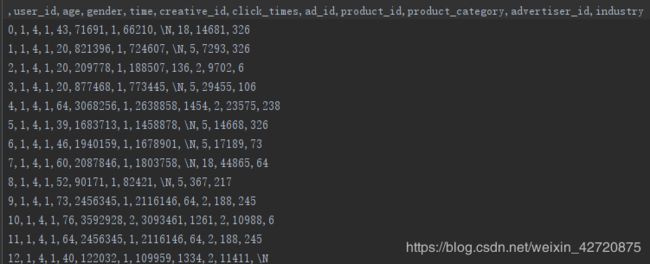
如上图所示:原始数据经过脱敏之后是一些id数字类的特征,这些每一个creative_id代表一种广告,若将id类特征onehot之后将会得到很大的类矩阵,接近300万维,这是不可能做后续工作的。因此需要通过id2embedding方法将id类特征变成低维稠密的embedding向量。
onehot
非正常人做法QAQ
tfidf
首先什么是tfidf:
词频 (term frequency, TF) 指的是某一个给定的词语在该文件中出现的次数。这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词频,而不管该词语重要与否。)
t f w , i = 文 本 i 中 词 w 出 现 的 次 数 文 本 i 中 所 有 词 的 个 数 tf_{w,i}=\frac{文本i中词w出现的次数}{文本i中所有词的个数} tfw,i=文本i中所有词的个数文本i中词w出现的次数
i d f w = 文 本 的 总 数 包 含 词 w 的 文 本 总 数 + 1 : + 1 是 为 了 避 免 分 母 为 0 − 平 滑 idf_{w}=\frac{文本的总数}{包含词w的文本总数+1}:+1是为了避免分母为0-平滑 idfw=包含词w的文本总数+1文本的总数:+1是为了避免分母为0−平滑
t f − i d f w , i = t f w , i ∗ i d f w tf-idf_{w,i}=tf_{w,i}*idf_{w} tf−idfw,i=tfw,i∗idfw
ID类特征embedding
embedding直接嵌入到模型中
代表方法deepfm
ids通过上下文关系转化为embedding
代表方法w2v,w2v方法有两种做法:1、cbow。2、skip-gram
w2v方法通过将一个user_id所有按顺序点击过的creative_id或者ad_id看作一篇传统意义上的文章,接着按照w2v的做法学出embedding矩阵代表词向量嵌入。
import pandas as pd
#用户数据
user = pd.read_csv('./train_preliminary/user.csv',sep=',')
print(user.head())
#用户点击数据
click_log=pd.read_csv('./train_preliminary/click_log.csv',sep=',')
print(len(click_log))
print(click_log.head())
#广告数据
ad=pd.read_csv('./train_preliminary/ad.csv',sep=',')
print(len(ad))
print(ad.head())
#拼接数据
df = pd.merge(user,click_log, on=['user_id'], how='left')
print(len(df))
df = pd.merge(df,ad, on=['creative_id'], how='left')

从上图可以按照user_id和creative_看到拼接后的矩阵‘mergerd’
df=df.sort_values(by='time')
print('sort by time')
print(df)

ad_id_trace=df.groupby('user_id').apply(lambda x:" ".join(x['ad_id'].astype(str))).rename('ad_id_trace').reset_index()
print(ad_id_trace.head())

这样就得到了每一个user在91天里面按时间顺序点击的所有广告。将这样的一个user所包含的信息看作nlp里面的句子,之后通过w2v就得到对应的稠密的embedding了。
文本分词
from gensim.models import KeyedVectors,word2vec,Word2Vec
sentence=list(word2vec.LineSentence('sentence.txt'))
print(len(sentence))
