PowerBI - 4.系统技术部署架构
- 系统技术部署架构
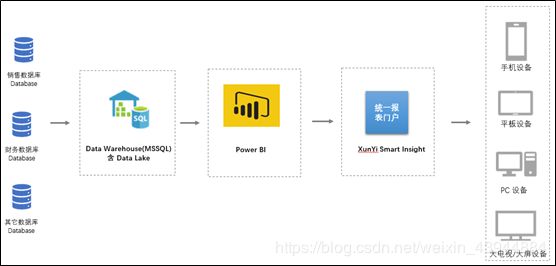
全业务数据管理平台 (ODS,DW)
全业务数据管理平台作为管理从业务系统导入数据查看和调整,导入外部数据,以及查看数据更新历史日志。
负责全业务数据管理平台的数据存储。
BI管理平台多维数据集 (Cube)
负载BI平台数据库,多维数据集、数据仓库数据库。
BI管理平台 (PowerBI Report Server, Smart-Insight web portal)
BI管理平台作为统一的报表查看入口,管理用户和角色权限,以及查看报表使用情况日志。
4.1. 需要的相关系统硬件资源
下面是以5000万行明细销售数据为基础估算的硬件资源评估,最低配置标准:
ODS数据服务器 CPU频率:4核 2.0GHz
内存:8G
硬盘容量:HD 1.1T windows server 2012 r2+ Datacenter
SQLServer2017 源业务系统数据整合、备份,隔离其它业务系统访问
DW数据库服务器 CPU频率:8核 2.0GHz
内存:8G
硬盘容量:HD 1T windows server 2012 r2+ Datacenter
SQLServer2017 存储ETL清洗后干净的数据,提高CUBE读取数据的速度
CUBE服务器 CPU频率:8核 2.0GHz
内存:8G
硬盘容量:HD 200G windows server 2012 r2+ Datacenter
SQLServer2017 多维分析数据库、数据集市
报表平台后端
数据服务器 CPU频率:8核 2.0GHz
内存:16G
硬盘容量:HD 200G windows server 2012 r2+ Datacenter
SQLServer2017
PowerBI Desktop
On-premises data gateway PowerBI 开发,PowerBI本地化部署使用的报表计算引擎服务
报表WEB服务器 CPU频率:8核 2.4GHz
内存:8G
硬盘容量:HD 200G windows server 2016 Datacenter
PowerBI Desktop 运行WEB应用程序,存储WEB单点登录、数据权限等数据,
下面是以5000万行明细销售数据为基础估算的硬件资源评估,建议配置标准:
ODS数据服务器 CPU频率:8核 2.0GHz
内存:8G
硬盘容量:HD 1.1T windows server 2012 r2+ Datacenter
SQLServer2017 源业务系统数据整合、备份,隔离其它业务系统访问
DW数据库服务器 CPU频率:8核 2.0GHz
内存:16G
硬盘容量:HD 1T windows server 2012 r2+ Datacenter
SQLServer2017 存储ETL清洗后干净的数据,提高CUBE读取数据的速度
CUBE服务器 CPU频率:16核 2.0GHz
内存:16G
硬盘容量:HD 500G windows server 2012 r2+ Datacenter
SQLServer2017 多维分析数据库、数据集市
报表平台后端
数据服务器 CPU频率:16核 2.0GHz
内存:16G
硬盘容量:HD 200G windows server 2012 r2+ Datacenter
SQLServer2017
PowerBI Desktop
On-premises data gateway PowerBI 开发,PowerBI本地化部署使用的报表计算引擎服务
报表WEB服务器 CPU频率:8核 2.4GHz
内存:16G
硬盘容量:HD 200G windows server 2016 Datacenter
PowerBI Desktop 运行WEB应用程序,存储WEB单点登录、数据权限等数据,
下面是以5000万行明细销售数据为基础估算的硬件资源评估,高级配置标准:
ODS数据服务器 CPU频率:8核 2.0GHz
内存:8G
硬盘容量:HD 1.1T windows server 2012 r2+ Datacenter
SQLServer2017 源业务系统数据整合、备份,隔离其它业务系统访问
DW数据库服务器 CPU频率:16核 2.0GHz
内存:16G
硬盘容量:HD 1T
(需要双机热备) windows server 2012 r2+ Datacenter
SQLServer2017
(启动SQL Always On) 存储ETL清洗后干净的数据,提高CUBE读取数据的速度
CUBE服务器 CPU频率:32核 2.0GHz
内存:32G
硬盘容量:HD 500G windows server 2012 r2+ Datacenter
SQLServer2017 多维分析数据库、数据集市
报表平台后端
数据服务器 CPU频率:16核 2.0GHz
内存:16G
硬盘容量:HD 200G
(可以做双机分流) windows server 2012 r2+ Datacenter
SQLServer2017
PowerBI Desktop
On-premises data gateway PowerBI 开发,PowerBI本地化部署使用的报表计算引擎服务
报表WEB服务器 CPU频率:8核 2.4GHz
内存:16G
硬盘容量:HD 200G windows server 2016 Datacenter
PowerBI Desktop 运行WEB应用程序,存储WEB单点登录、数据权限等数据,
4.2. 需要的相关系统软件资源
Microsoft Windows Server:(任选之一)



Microsoft SQL Server: (任选之一)
Microsoft SQL Server 2016 Enterprise
Microsoft SQL Server 2017 Enterprise
Microsoft Power BI
按项目开工时间配置对应的SQL版本,一般情况是:
Microsoft Power BI Report Server 2018/9 版
4.3. 关于系统硬件容灾
系统运行架构设计的最主要目的之一,就是保证系统的稳定性。系统须遵循全天候(7×24×365)不间断服务的原则,确保失效事件最少化,并在发生事故时,可继续保证业务的开展。
保障业务的连续性,可通过如下方案实现:
1. 网络结构避免单点故障
本方案的网络结构采用了多层架构,由2台WEB服务器,2台数据库服务器组成,从而从网络该问上避免单点故障。一旦某一网络节点出现故障,其它节点依然可以提供服务,不会导致整个系统出现无法提供服务的情况,从而提高了业务的连续性。
2. 应用结构的良好划分,有效提高业务连续性
根据网站的业务逻辑将应用分布在web服务器等多台服务器上,由于网络的物理架构采用多层设计,因此可以有效缩小应用故障的影响范围,不会因为某一台服务器上的应用出错,而导致整个站点瘫痪。
3. 数据库备份设计
数据服务器对系统数据按照制定的备份策略进行备份,在数据服务器出现故障时,可以对数据进行恢复,以避免各种可能的原因,造成系统数据丢失,产生无法恢复的严重故障。
4. 管理机制是高可用性的保证
采用网络管理、严格的整套监控及远程维护系统,并对系统状态进行24小时实时运行监控,并且在发现故障后能及时发送给系统管理人员,同时能够自己做自我恢复。
制定故障迅速恢复和应急措施,制定数据备份机制,针对故障级别制定不同的处理流程。保证关键设备间可相互替代,对关键服务器,需要建立备份,即可以作为测试之用,也可以作为应急之需。
4.4. 关系系统软件容灾
应用SQL SERVER AlwaysOn实现数据高可用和灾难恢复
在SQL Server中配置和管理一个或多个可用性组的核心AlwaysOn。“可用性组”针对一组离散的用户数据库(称为“可用性数据库”,它们共同实现故障转移)支持故障转移环境。 一个可用性组支持一组主数据库以及一至四组对应的辅助数据库。通过配置使用可用性组实现数据高可用和数据异地容灾。
AlwaysON是一种整库同步的技术,所有的成员服务器都维护一套相同的数据库副本。当主副本上的数据发生变化时,数据会实时同步到辅助副本上。
下图详细描述了AlwaysON数据同步的整个过程。
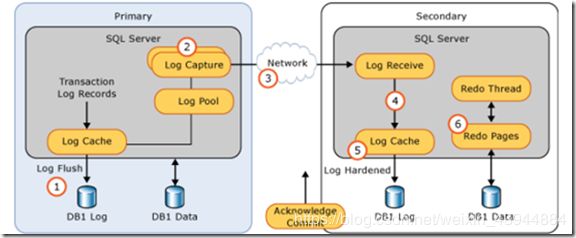
AlwaysOn实施部署架构和收益

4.5. 数据分层结构关系
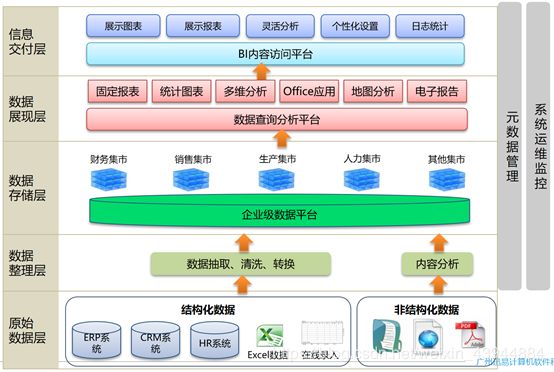
- 数据源层
通过ODBC等通用接口方式按照业务需求的采集频率,采集数据至数据仓库平台中。 - 数据整理层(ODS层,ETL层)
采用主流ETL工具加载传统关系型数据库中的数据至数据仓库中,按照业务主题要求进行数据建模、数据清洗、数据加载工作。
采用主流专用采集工具采集实时设备数据,将数据通过增量或者全量的方式同步至数据仓库层。 - 数据存储层(数据仓库层)
采用主流分布式体系的架构,满足关系型及非关系型数据的接入,并通过分布式架构满足业务的扩展性。 - 数据应用层
基于数据层处理后的数据,建立主题分析模型,为业务用户提供数据决策服务。 - 数据交付层
支持H5架构,满足如Chrome、IE11+、Safari、火狐等多种浏览器终端、移动终端、大屏将数据呈现给最终用户。可以推动业务回归,如设定预警情况触发工作流,导出与导入系统,跳转到采集系统等等。
4.6. 数据接入处理输出整体流程

数据从数据源系统提取,到企业数据仓库,其中数据仓库分为源数据层和干净数据层,源数据层确保按时按量按质归集数据,干净数据层保证数据与数据之间业务逻辑完整性,准确性,无异议性,然后干净数据层数据又提取到多维数据数据集,大大提高访问的速度并降低影响的读写硬件资源要求,再从PowerBI Gateway或PowerBI本地化引擎获取数据最终在PowerBI报表上进行数据展现。
4.6.1. 数据抽取,存储,转化,汇总,降维加维
数据抽取:
因数据来源于多系统与生产,财务,人力,营销系统,而各系统又有不同的数据库类型如SQL,Oracle, Mysql或非结构数据txt, log, csv, xml,程序接口等,为了确保后续逻辑处理更专业化简单化,所以这层的分工解决网络归集数据,跨系统归集数据,跨数据库类型归集数据,统一时间调度安排有序进行。
存储:
归集后的数据量来自很多系统,数据量庞大,一般企业数据情况会在两年里数据量翻一翻,所以需要一系列数据存储技术,如大数据量存储,高访问量数据存储,历史数据冷备,数据具备容灾功能等,这层承担起上述相关责任。
转化:
归集后数据由于来自各系统,各系统数据之间关系不大,或关系各异,或者各系统本身就有一定的缺陷导致数据质量堪忧。所以就需要在这层对数据进行转化,如对默认值填充,补充默认的组织层级,虚拟层级,补充业务逻辑需要的如,是否达标,是否证件号码有错,是否质量过关等判定。对数据关联性,需要对不同系统之间的编码进行转换达到相对一致的情况下进行连接,以能在后续数据统计中进行可用处理。
汇总:
数据存储时为业务数据的最小粒度,在此基础上对数据进行再组织进行统计,包括但不限于:同比,环比,年累计,月累计等等,也包括交叉维度组合方式的统计,如质量有问题过期发货数,某业态逾期未收款等
降维:
对数据最小粒度进行分析由于数据量过于庞大导致决策迷茫,所以会使用降维分析方式,即对低层级组织或事物性质采取更高层级的组织或高层级的属性分类进行统计,以便更节省分析的时间,但最终定位问题仍然需要到最少粒度进行分析。
加维:
对数据高低层次进行分析有时并不能达到效果,而我们会采取更人性化的方式,场景驻入的方式,以场景所需要的数据为条件,可单向或组合方式对数据进行增加类似于是否VIPA级,是否VIPB级,是否最近可能要购买的判定字段,也即为判定标签,也即为新的维度。
4.6.2. 实时/准实时接入接出处理
对准实时数据接入接出处理
对常规关系和非关系数据进行归集,转化再进行输出。中间经过ODS,DW,Cube的方式再到展示层。
对实时数据接入接出处理
对数据进行增量和流式计算,结果的方式存入内存数据库或Hadoop方式。在展示端进行统一提取。
对实时&准实时数据接入接出处理
对准时实时数据归集后以增量和方式和实时数据要求方式一致的方式进行接入,确保计算准确,在展示端进行统一提取。另一种方式是通过展示工具对准实时数据进行缓存,再对实时数据按更高频率进行刷新。
4.7. 数据安全设计
对数据进行统一集成权限控制
对接现有所有系统数据的情况下,以域控为中心的数据权限,参考某一主业务系统一般为财务,OA,营销,生产作为权限参考,进行同样的行级及菜单级数据权限控制。
对数据按某一特定系统权限进行控制
对接现有所有系统数据的情况下,以域控为中心的数据权限或以一个主业务系统一般为财务,OA,营销,生产作为权限依据,进行同样的行级及菜单级数据权限控制。
对数据进行独立特定权限控制
对接现有所有系统数据的情况下,以域控为中心的数据权限或以一个参考的主业务系统一般为财务,OA,营销,生产作为权限参考,综合和所有组织关系,并独立配置BI系统的权限体系,一般在跨业态的集成应用较多,进行同样的行级及菜单级数据权限控制。
4.8. 数量与硬件资源关系
以营销系统为例,生产系统数据量一般是营销系统4倍到10倍之间,主要考虑是大表的数目比营销系统多为基数。目前按数量与硬件资源关系,下面需要全面考虑存储,统计计算,输出时的性能消耗,一般定义为
最大表千万级明细数据
至少需要250G存储,DW计算需要至少需要8G内存,CPU8核以上。
最大表亿级明细数据
至少需要500G存储,DW计算需要至少需要16G内存,CPU16核以上。
最大表十亿级明细数据
至少需要2T存储,DW计算需要至少需要32G内存,CPU32核以上。可以使用分布式负载架构方式。
每天流入千万级明细数据
至少需要2T存储,DW计算需要至少需要64G内存,CPU64核以上。使用分布式负载架构方式。
每天流入亿级明细数据
至少需要200T存储,DW计算需要至少需要128G内存,CPU128核以上。使用分布式负载架构方式。
每天流入十亿级明细数据
至少需要2PB存储,DW计算需要至少需要256G内存,CPU256核以上。使用分布式负载架构方式。
若有什么需要修正请联系我: 林嘉诚, [email protected]