impala&hive大数据平台数据血缘与数据地图(一)-解析impala与hive的血缘日志
impala数据血缘与数据地图系列:
1. 解析impala与hive的血缘日志
2. 实时采集impala血缘日志推送到kafka
---------------------------------解析impala与hive血缘日志-------------------------------------------------------------
Impala血缘:
CDH官方文档impala数据血缘:
https://docs.cloudera.com/documentation/enterprise/latest/topics/impala_lineage.html
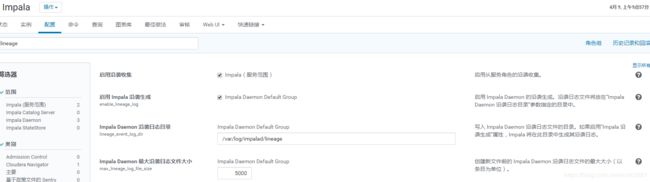
在CM中找到该参数:
开启impala血缘,以及配置血缘日志路径及文件最大限制。
参数:lineage_event_log_dir
目录:每个impala daemon节点下 /var/log/impalad/lineage
需要注意的是这里只记录执行成功的脚本。
我这里使用的是CDH6.2版本,与CDH5的版本在日志记录的结构上有所区别,但区别不大。
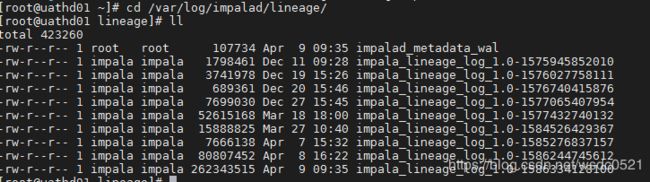
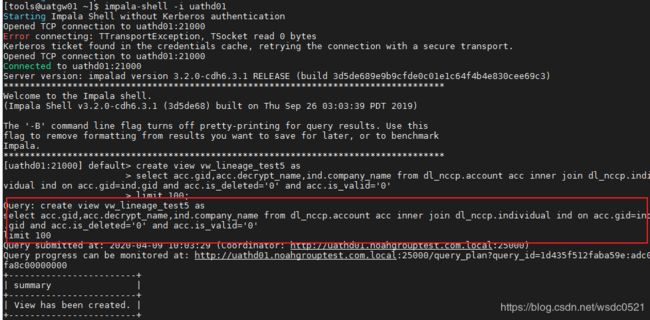
测试:使用impala-shell 指定impala daemon节点启动命令行,执行SQL命令,然后查看该daemon节点最新日志。
impala-shell -i uathd01
这里我创建一个视图:
然后到uathd01的节点看最新血缘日志:
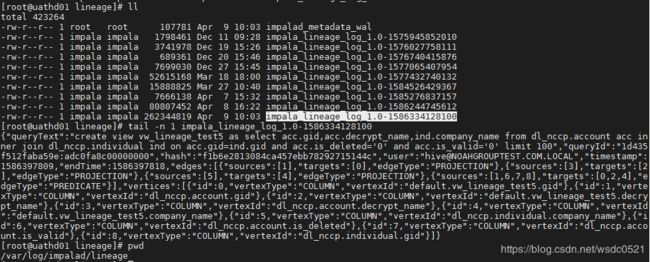
把这段json串拿出来格式化一下看看:
queryText:执行的命令
queryId : impala的执行ID
hash: sql的hash
user:执行该命令的用户
timestamp: 开始时间戳
endTime:结束时间戳
edges: 记录每个source到target的映射关系,edgeType为PREDICATE的部分是所有source字段到所有的target字段id的映射,edgeType为PROJECTION的是每个source字段到每个target字段的映射,这里是多对一的关系,即如果有一个目标字段是由两个源字段处理得来的话,这里的sourceid和targetid就是一个多对一的关系,但如果是一个源字段处理出了两个目标字段,在这里仍旧是两个代码块。
vertices: 该SQL内所有的源和目标字段,与edges中的id一一对应。
{
"queryText": "create view vw_lineage_test5 as select acc.gid,acc.decrypt_name,ind.company_name from dl_nccp.account acc inner join dl_nccp.individual ind on acc.gid=ind.gid and acc.is_deleted='0' and acc.is_valid='0' limit 100",
"queryId": "1d435f512faba59e:adc0fa8c00000000",
"hash": "f1b6e2813084ca457ebb78292715144c",
"user": "[email protected]",
"timestamp": 1586397809,
"endTime": 1586397818,
"edges": [
{
"sources": [
1
],
"targets": [
0
],
"edgeType": "PROJECTION"
},
{
"sources": [
3
],
"targets": [
2
],
"edgeType": "PROJECTION"
},
{
"sources": [
5
],
"targets": [
4
],
"edgeType": "PROJECTION"
},
{
"sources": [
1,
6,
7,
8
],
"targets": [
0,
2,
4
],
"edgeType": "PREDICATE"
}
],
"vertices": [
{
"id": 0,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.gid"
},
{
"id": 1,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.gid"
},
{
"id": 2,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.decrypt_name"
},
{
"id": 3,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.decrypt_name"
},
{
"id": 4,
"vertexType": "COLUMN",
"vertexId": "default.vw_lineage_test5.company_name"
},
{
"id": 5,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.individual.company_name"
},
{
"id": 6,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.is_deleted"
},
{
"id": 7,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.account.is_valid"
},
{
"id": 8,
"vertexType": "COLUMN",
"vertexId": "dl_nccp.individual.gid"
}
]
}Hive:
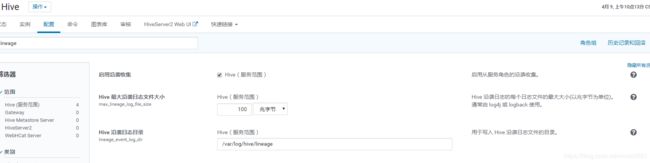
同impala类似,不再赘述,区别仅仅是日志的json格式以及记录的详细程度的区别。
应用:
接下来就是如何使用这些血缘的日志,我们已经分析了impala血缘日志的结构,接下来只要使用日志采集工具filebeat或flume,logstash等工具采集每个impala daemon节点上的日志,然后对每个json串进行解析即可,后面的文章会演示如何实时采集impala血缘到kafka,消费kafka里的血缘数据处理后写入neo4j数据库内进行数据血缘数据地图的展示。