测试需要准备好:
1、操作系统ubuntu 14.04 LTS 64位
2、caffe环境的安装
3、python环境安装,采用anaconda版本,
4、Opencv 2.4.13版本
5、下载imagenet对应的预先训练好的caffenet模型及相关数据文件。
6、待识别的图片文件。
图像目标分类识别
caffe的官方完美的支持Python语言的兼容,提供了pycaffe的接口,用起来很方便。
1、加载numpy以及matplotlib等模块
@alex_starsky#安装Python环境、numpy、matplotlibimportnumpyasnpimportmatplotlib.pyplotasplt#设置默认显示参数plt.rcParams['figure.figsize'] = (10,10)# 图像显示大小plt.rcParams['image.interpolation'] ='nearest'# 最近邻插值: 像素为正方形plt.rcParams['image.cmap'] ='gray'# 使用灰度输出而不是彩色输出

2、 加载Load caffe
# caffe模块要在Python的路径下;# 这里我们将把caffe 模块添加到Python路径下.importsyscaffe_root ='/home/xxx/caffe/'#该文件要从路径{caffe_root}/examples下运行,否则要调整这一行。sys.path.insert(0, caffe_root +'python')importcaffe# 如果你看到"No module named _caffe",那么要么就是你没有正确编译pycaffe;要么就是你的路径有错误。

3、加载网络并设置输入预处理
将Caffe设置为CPU模式,并将预下载的网络数据文件从硬盘加载网络。
caffe.set_mode_cpu()model_def = caffe_root +'models/bvlc_reference_caffenet/deploy.prototxt'model_weights = caffe_root +'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'net = caffe.Net(model_def,# 定义模型结构model_weights,# 包含了模型的训练权值caffe.TEST)# 使用测试模式

4、设置图像输入参数配置
设置输入预处理,我们将用Caffe’s caffe.io.Transformer来进行预处理。
# 加载ImageNet图像均值 (随着Caffe一起发布的)mu = np.load(caffe_root +'python/caffe/imagenet/ilsvrc_2012_mean.npy')mu = mu.mean(1).mean(1)#对所有像素值取平均以此获取BGR的均值像素值# 对输入数据进行变换transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})transformer.set_transpose('data', (2,0,1))#将图像的通道数设置为outermost的维数transformer.set_mean('data', mu)#对于每个通道,都减去BGR的均值像素值transformer.set_raw_scale('data',255)#将像素值从[0,255]变换到[0,1]之间transformer.set_channel_swap('data', (2,1,0))#数据通道交换,从RGB变换到BGR

5、图片加载与识别
加载图像并进行预处理
# 设置输入图像大小net.blobs['data'].reshape(50,# batch 大小3,# 3-channel (BGR) images227,227)# 图像大小为:227x227image = caffe.io.load_image(caffe_root +'examples/images/cat.jpg')transformed_image = transformer.preprocess('data', image)plt.imshow(image)# 将图像数据拷贝到为net分配的内存中net.blobs['data'].data[...] = transformed_image

接下来,开始进行识别分类
# 将图像数据拷贝到为net分配的内存中net.blobs['data'].data[...] = transformed_image### 执行分类output = net.forward() output_prob = output['prob'][0]#batch中第一张图像的概率值 print'predicted class is:', output_prob.argmax()>>> predictedclassis:281

281是什么鬼?别慌。
网络输出的是一个概率向量;最可能的类别是第281个类别。这个类别是啥?让我们来查看一下ImageNet的标签。
# 加载ImageNet标签labels_file = caffe_root +'data/ilsvrc12/synset_words.txt'ifnotos.path.exists(labels_file):print'labels file ilsvrc12/synset_words.txt not exist.'labels = np.loadtxt(labels_file, str, delimiter='\t')print'output label:', labels[output_prob.argmax()]>>> output label: n02123045 tabby, tabby cat
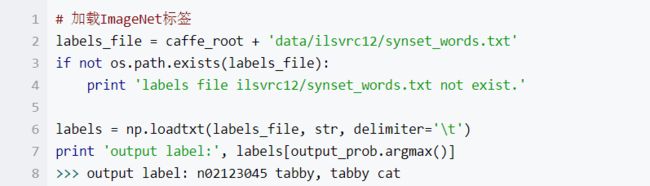
咱们输入的不就是一个猫咪么,”Tabby cat”结果是正确的。
好了,图片识别出来了,是一只猫,在imagenet上叫做“Tabby cat”。达到预期结果。
如有需要,请参考完整程序:
python程序样例下载路径:http://download.csdn.net/detail/alex_starsky/9692957
End.