(含源码)「自然语言处理(NLP)」RoBERTa&&XLNet&&语言模型&&问答系统训练
来源: AINLPer 微信公众号(每日更新…)
编辑: ShuYini
校稿: ShuYini
时间: 2020-07-27
引言: 本次内容主要包括:稳健优化Bert模型(RoBERTa)、自回归预训练模型(XLNet)、无监督多任务学习语言模型、生成预训练语言理解、深层上下文单词表示、键值记忆网络、大规模问答系统训练等 。。
本次论文获取方式:
1、关注AINLPer 微信公众号(每日更新…)回复:BT002
2、知乎主页–ShuYini
1、TILE: RoBERTa: A Robustly Optimized BERT Pretraining Approach
Author: Yinhan Liu • Myle Ott • Naman Goyal • Jingfei Du • Mandar Joshi
Paper: https://arxiv.org/pdf/1907.11692v1.pdf
Code: https://github.com/brightmart/roberta_zh
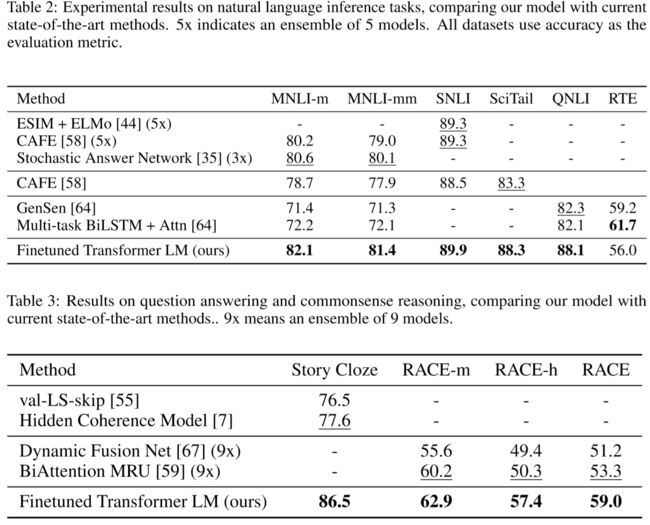
论文简述: 语言模型的预训练使得相关任务在性能表现上有了大幅提升,但仔细对比不同方法你会发现在某些地方还是比较有挑战性的。 比如训练的时候需要昂贵的计算资源、通常在不同大小的私有数据集上进行的,超参数的选择影响最终的结果。我们提出对BERT预训练进行重复研究,该研究仔细衡量了许多关键超参数和训练数据数量的影响,发现之前的BERT训练不足,它本可以匹配或超过它发布的每个模型的性能。 基于对之前Bet模型的讨论研究,本文模型在GLUE,RACE和SQuAD上获得了最先进的结果。


2、TILE: XLNet: Generalized Autoregressive Pretraining for Language Understanding
Author: Zhilin Yang • Zihang Dai • Yiming Yang • Jaime Carbonell • Ruslan Salakhutdinov
Paper: https://arxiv.org/pdf/1906.08237v2.pdf
Code: https://github.com/listenviolet/XLNet
论文简述: 依据双向上下文的建模功能,基于预训练的去噪自动编码(比如bert)相比于基于自回归语言建模具有更好的性能。但是,BERT依赖于使用mask破坏输入,因此忽略了mask位置之间的依赖关系,以及预训练微调的差异。鉴于这些优点和缺点,本文提出XLNet,这是一种广义的自回归预训练方法,该方法(1)通过最大化因子分解的所有排列组合的期望似然性来实现双向上下文的学习,并且(2)由于其自回归性能而克服了BERT的局限性。 此外,XLNet将来自最先进的自动回归模型Transformer-XL的思想整合到预训练中。 实验表明,XLNet在20个任务上的表现要优于BERT,通常包括问答,自然语言推断,情感分析和文档排名等。


3、TILE: Language Models are Unsupervised Multitask Learners
Author: Alec Radford • Jeffrey Wu • Rewon Child • David Luan • Dario Amodei • Ilya Sutskever
Paper: https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
Code: https://github.com/akanyaani/gpt-2-tensorflow2.0
论文简述: 自然语言处理任务通常在特定任务的数据集上通过监督学习来做训练,例如问题解答,机器翻译,阅读理解和摘要。当在一个名为WebText的数百万的网页数据集上训练时,我们发现语言模型在没有任何明确监督的情况下开始学习这些任务。在文档加问题的条件下,语言模型在CoQA数据集上生成的答案F1分数达到55 ,在不使用127,000多个训练示例的情况下,其性能或超过3/4个基线系统。语言模型的容量对于零任务迁移至关重要,增加其容量可以以对数线性的方式提高跨任务性能。GPT-2是一个具有1.5B个参数的Transformer,它可以在zero lens设置的情况下,8个语言模型数据集最终获得了7个最新的结果,但是这并不适用于WebText。模型的样本反映了这些改进,并包含连贯文本段落。这些发现为构建语言处理系统提供了一种很有前景的方法,可以从自然发生的演示中学习执行任务。


4、TILE: Improving Language Understanding by Generative Pre-Training
Author: Alec Radford • Karthik Narasimhan • Tim Salimans • Ilya Sutskever
Paper: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
Code: https://github.com/openai/finetune-transformer-lm
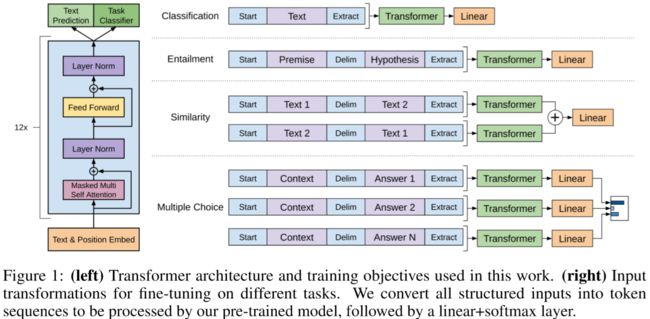
论文简述: 自然语言理解包含各种各样的任务,例如:文本范围、问答、语义相似度评估、文档分类。尽管大型的未标记文本语料库很丰富,但是用于学习这些特定任务的标记数据却很少,这使得经过严格训练的模型难以充分发挥作用。本文验证发现,通过在各种未标记文本的语料库上对语言模型进行生成式预训练,然后对每个特定任务进行区分性微调,可以实现这些任务的巨大增益。与以前的方法相比,我们在微调过程中利用了任务感知的输入转换来实现有效的传输,同时对模型体系结构的更改要求最小。 我们在广泛的自然语言理解基准测试中证明了我们的方法的有效性。
5、TILE: Measuring Compositional Generalization: A Comprehensive Method on Realistic Data
Author: Daniel Keysers • Nathanael Schärli • Nathan Scales • Hylke Buisman
Paper: https://arxiv.org/pdf/1912.09713v2.pdf
Code: https://github.com/google-research/google-research/tree/master/cfq
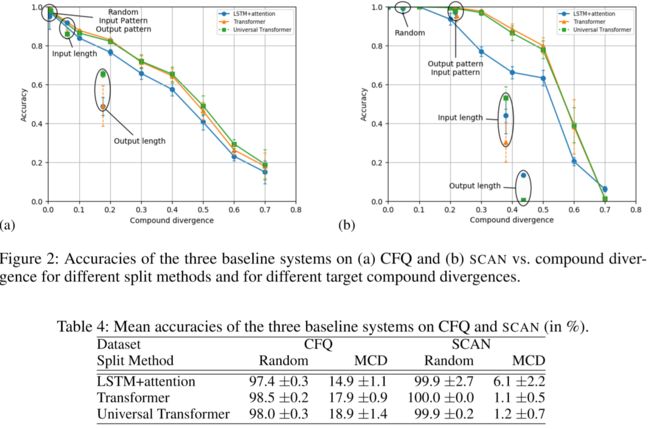
论文简述: 最先进的机器学习方法表现出有限的成分概括性。同时,缺乏实际的基准来全面衡量其能力,这使得改进评估变得颇具挑战性。我们引入了一种新方法来系统地构建此类基准,即通过最大化复合散度,同时保证训练集和测试集之间的较小的原子散度,并定量地将此方法与其他创建成分泛化基准的方法进行比较 。我们提出了一个基于该方法构造的大型真实自然语言问答数据集,并用它分析了三种机器学习体系结构的合成泛化能力。我们发现它们在成分上无法概括,并且复合散度和准确度之间存在惊人的强负相关。我们还演示了如何使用我们的方法在现有扫描数据集的基础上创建新的组合基准,证明了本文方法的有效性。

6、TILE: Deep contextualized word representations
Author: Matthew E. Peters • Mark Neumann • Mohit Iyyer Hedayatnia
Paper: https://arxiv.org/pdf/1802.05365v2.pdf
Code: https://github.com/flairNLP/flair
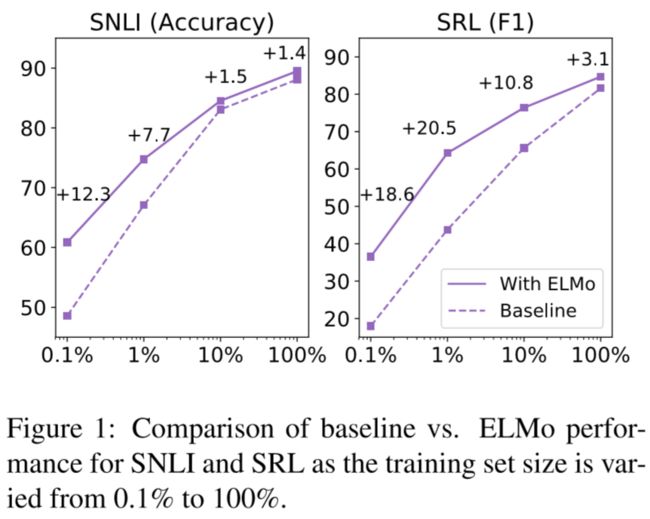
论文简述: 我们引入了一种新型的深层上下文词表示形式,该模型既可以建模(1)我们使用单词的复杂特征(例如语法和语义),又可以建模(2)这些用法如何在不同的语言语境中变化(即用于建模多义性)。我们的词向量是深度双向语言模型(biLM)内部状态的学习函数,其中biLM模型是在大型文本语料库上预先训练的。实验表明,这些表示可以很容易地添加到现有的模型中,并在六个具有挑战性的NLP问题(包括问题回答、文本蕴涵和情绪分析)中表现显著提高。经过分析表明,暴露出预先训练过的网络的深层内在是至关重要的,这将可以允许下游模型混合不同类型的半监督信号。

7、TILE: Key-Value Memory Networks for Directly Reading Documents
Author: Alexander Miller • Adam Fisch • Jesse Dodge
Paper: https://arxiv.org/pdf/1606.03126v2.pdf
Code: https://github.com/jojonki/key-value-memory-networks
论文简述: 阅读文档并能够直接回答文档中的问题是一项的挑战。为解决该问题,当前很多人将问题回答(QA)定向为使用知识库(KB),并且事实证明这是有效的。但是因为架构无法支持某些类型的答案并且过于稀疏,KB会受到很多限制。在这项工作中,我们介绍了一种新的方法,即键值存储网络,该方法在内存读取操作寻址和输出阶段利用不同的编码,来使文档阅读更为可行。 为了在单个框架中直接使用KBs、信息提取或Wikipedia文档进行比较,我们构造了一个分析工具WikiMovies,这是一个QA数据集,在电影领域中包含原始文本和预处理知识库。实验证明本文的方法缩小了所有三种设置之间的差距。它还在现有的WikiQA基准测试中获得了最先进的结果。


8、TILE: Large-scale Simple Question Answering with Memory Networks
Author: Antoine Bordes • Nicolas Usunier • Sumit Chopra
Paper: https://arxiv.org/pdf/1506.02075v1.pdf
Code: https://github.com/aukhanee/FactQA
论文简述: 训练大规模问答系统非常复杂,因为训练资源通常只覆盖一小部分可能的问题。 本文研究了多任务和迁移学习对简单问题回答的影响: 只要可以在给定问题的情况下检索正确的证据,就可以轻松地回答所需的推理,但是这在大规模条件下可能是困难的。 为此,我们引入与现有基准共用且包含10万个问题的新数据集, 我们在内存网络的框架内进行研究,实验结果表明可以成功地训练内存网络以实现出色的性能。

Attention
更多自然语言处理相关知识,还请关注**AINLPer公众号**,极品干货即刻送达。