pytorch三层全连接层实现手写字母识别
先用最简单的三层全连接神经网络,然后添加激活层查看实验结果,最后加上批标准化验证是否有效
- 首先根据已有的模板定义网络结构SimpleNet,命名为net.py
import torch
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
from torch import nn,optim
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
#定义三层全连接神经网络
class simpleNet(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):#输入维度,第一层的神经元个数、第二层的神经元个数,以及第三层的神经元个数
super(simpleNet,self).__init__()
self.layer1=nn.Linear(in_dim,n_hidden_1)
self.layer2=nn.Linear(n_hidden_1,n_hidden_2)
self.layer3=nn.Linear(n_hidden_2,out_dim)
def forward(self,x):
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x
#添加激活函数
class Activation_Net(nn.Module):
def __init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(NeutalNetwork,self).__init__()
self.layer1=nn.Sequential(#Sequential组合结构
nn.Linear(in_dim,n_hidden_1),nn.ReLU(True))
self.layer2=nn.Sequential(
nn.Linear(n_hidden_1,n_hidden_2),nn.ReLU(True))
self.layer3=nn.Sequential(
nn.Linear(n_hidden_2,out_dim))
def forward(self,x):
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x
#添加批标准化处理模块,皮标准化放在全连接的后面,非线性的前面
class Batch_Net(nn.Module):
def _init__(self,in_dim,n_hidden_1,n_hidden_2,out_dim):
super(Batch_net,self).__init__()
self.layer1=nn.Sequential(nn.Linear(in_dim,n_hidden_1),nn.BatchNormld(n_hidden_1),nn.ReLU(True))
self.layer2=nn.Sequential(nn.Linear(n_hidden_1,n_hidden_2),nn.BatchNormld(n_hidden_2),nn.ReLU(True))
self.layer3=nn.Sequential(nn.Linear(n_hidden_2,out_dim))
def forword(self,x):
x=self.layer1(x)
x=self.layer2(x)
x=self.layer3(x)
return x
- 训练网络,
import torch
from torch.autograd import Variable
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from torch import nn,optim
from torch.utils.data import DataLoader
from torchvision import datasets,transforms
#定义一些超参数
import net
batch_size=64
learning_rate=1e-2
num_epoches=20
#预处理
data_tf=transforms.Compose(
[transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])#将图像转化成tensor,然后继续标准化,就是减均值,除以方差
#读取数据集
train_dataset=datasets.MNIST(root='./data',train=True,transform=data_tf,download=True)
test_dataset=datasets.MNIST(root='./data',train=False,transform=data_tf)
#使用内置的函数导入数据集
train_loader=DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
test_loader=DataLoader(test_dataset,batch_size=batch_size,shuffle=False)
#导入网络,定义损失函数和优化方法
model=net.simpleNet(28*28,300,100,10)
if torch.cuda.is_available():#是否使用cuda加速
model=model.cuda()
criterion=nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=learning_rate)
import net
n_epochs=5
for epoch in range(n_epochs):
running_loss=0.0
running_correct=0
print("epoch {}/{}".format(epoch,n_epochs))
print("-"*10)
for data in train_loader:
img,label=data
img=img.view(img.size(0),-1)
if torch.cuda.is_available():
img=img.cuda()
label=label.cuda()
else:
img=Variable(img)
label=Variable(label)
out=model(img)#得到前向传播的结果
loss=criterion(out,label)#得到损失函数
print_loss=loss.data.item()
optimizer.zero_grad()#归0梯度
loss.backward()#反向传播
optimizer.step()#优化
running_loss+=loss.item()
epoch+=1
if epoch%50==0:
print('epoch:{},loss:{:.4f}'.format(epoch,loss.data.item()))
训练的结果截图如下:

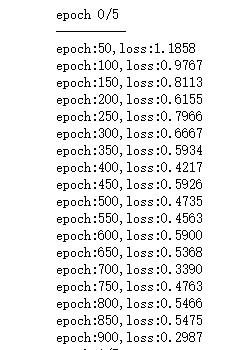
- 测试网络
#测试网络
model.eval()#将模型变成测试模式
eval_loss=0
eval_acc=0
for data in test_loader:
img,label=data
img=img.view(img.size(0),-1)#测试集不需要反向传播,所以可以在前项传播的时候释放内存,节约内存空间
if torch.cuda.is_available():
img=Variable(img,volatile=True).cuda()
label=Variable(label,volatile=True).cuda()
else:
img=Variable(img,volatile=True)
label=Variable(label,volatile=True)
out=model(img)
loss=criterion(out,label)
eval_loss+=loss.item()*label.size(0)
_,pred=torch.max(out,1)
num_correct=(pred==label).sum()
eval_acc+=num_correct.item()
print('test loss:{:.6f},ac:{:.6f}'.format(eval_loss/(len(test_dataset)),eval_acc/(len(test_dataset))))
![]()
训练的时候,还可以加入一些dropout,正则化,修改隐藏层神经元的个数,增加隐藏层数,可以自己添加。