深度之眼Pytorch框架训练营第四期——PyTorch中自动求导系统(torch.autograd)
文章目录
- `PyTorch`中自动求导系统(`torch.autograd`)
- 1、`torch.autograd`
- (1)`torch.autograd.backward`
- (2)`torch.autograd.grad`
- 2、实战:逻辑回归的`Pytorch`实现
- (1)逻辑回归理论
- (2)`Pytorch`实现
PyTorch中自动求导系统(torch.autograd)
训练深度学习模型本质上就是不断更新权值,而权值的更新需要求解梯度,因此求解梯度非常关键。然而求解梯度十分繁琐,pytorch提供自动求导系统,利用这个自动求导系统,我们不需要手动计算梯度,只需要搭建好前向传播的计算图,然后根据pytorch中的autograd方法就可以得到所有张量的梯度
1、torch.autograd
(1)torch.autograd.backward
- 功能:自动求取梯度
- 参数:
tensor:用于求导的张量,例如损失函数retain_graph:保存计算图,由于pytorch采用动态图机制,在每一次反向传播结束之后,计算图都会释放掉。如果想继续使用计算图,就需要设置参数retain_graph为Truecreate_graph:创建导数计算图,用于高阶求导grad_tensors:多梯度权重;当有多个损失函数需要去计算梯度的时候,就要设计各个损失函数之间的权重比例- 例子: y = ( x + w ) ∗ ( w + 1 ) y=(x+w) * (w+1) y=(x+w)∗(w+1),求 ∂ y ∂ w \frac{\partial y}{\partial w} ∂w∂y
- 计算图:

- 计算过程:
∂ y ∂ w = ∂ y ∂ a ∂ a ∂ w + ∂ y ∂ b ∂ b ∂ w = b ∗ 1 + a ∗ 1 = b + a = ( w + 1 ) + ( x + w ) = 2 ∗ w + x + 1 = 2 ∗ 1 + 2 + 1 = 5 \begin{aligned} \frac{\partial y}{\partial w} = & \frac{\partial y}{\partial a} \frac{\partial a}{\partial w}+\frac{\partial y}{\partial b} \frac{\partial b}{\partial w} \\ = & b * 1+a * 1\\ = & b + a \\ = & (w+1)+(x+w) \\ = & 2 * w+x+1 \\ = & 2 * 1+2+1 \\ = & 5 \end{aligned} ∂w∂y=======∂a∂y∂w∂a+∂b∂y∂w∂bb∗1+a∗1b+a(w+1)+(x+w)2∗w+x+12∗1+2+15
代码实现
w = torch.tensor([1.], requires_grad=True) # 创建叶子张量,并设定requires_grad为True,因为需要计算梯度;
x = torch.tensor([2.], requires_grad=True) # 创建叶子张量,并设定requires_grad为True,因为需要计算梯度;
a = torch.add(w, x) # 执行运算并搭建动态计算图
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward(retain_graph=True) # 对y执行backward方法就可以得到x和w两个叶子节点
print(w.grad)
# tensor([5.])
- 几点说明:
- 代码中用到的
y.backward()方法用于反向传播,如果不写这行代码,则w.grad = None,从底层代码看,.backward()方法调用了torch.autograd中的backward()方法 backward()中的retain_grad参数,如果设置为True,则表示保存计算图,如果还想执行一次反向传播 ,必须将retain_grad参数设置为retain_grad=True,因为如果没有设置retain_grad=True,则每进行一次backward之后,计算图都会被清空,没法再进行一次backward()操作backward()中的grad_tensors参数用于设置多梯度权重,以下面的代码为例说明:
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) # retain_grad()
b = torch.add(w, 1)
y0 = torch.mul(a, b) # y0 = (x+w) * (w+1)
y1 = torch.add(a, b) # y1 = (x+w) + (w+1) dy1/dw = 2
loss = torch.cat([y0, y1], dim=0) # [y0, y1]
grad_tensors = torch.tensor([1., 2.])
loss.backward(gradient=grad_tensors) # gradient 传入 torch.autograd.backward()中的grad_tensors
print(w.grad)
# tensor([9.])
上面的代码中有一行grad_tensors = torch.tensor([1., 2.])表示的意思是对y0的梯度乘1,对y1的梯度乘2,所以是 5 + 2 × 2 = 9 5+2\times2=9 5+2×2=9
(2)torch.autograd.grad
- 功能:求取梯度
- 参数:
outputs:用于求导的张量,如损失函数inputs:需要梯度的张量,如上面代码中的wcreate_graph:创建导数计算图,用于高阶求导retain_graph:保存计算图grad_outputs:多梯度权重- 代码(实现 y = x 2 y = x^2 y=x2二阶求导):
x = torch.tensor([3.], requires_grad=True)
y = torch.pow(x, 2) # y = x**2
grad_1 = torch.autograd.grad(y, x, create_graph=True) # grad_1 = dy/dx = 2x = 2 * 3 = 6
print(grad_1)
# (tensor([6.], grad_fn=),)
grad_2 = torch.autograd.grad(grad_1[0], x) # grad_2 = d(dy/dx)/dx = d(2x)/dx = 2
print(grad_2)
# (tensor([2.]),)
- 注意事项:
autograd的梯度不自动清零,如果重复调用,会不断累加,为了能够实现梯度清零,需要用方法.grad.zero_()(这里的下划线代表原地操作)进行梯度自动清零处理:- 依赖于叶子结点的结点,
requires_grad默认为True,不需要重复设置 - 叶子结点不可执行in-place(原位操作):在
pytorch中,经常用加后缀_的方法表示原位操作,例如.add_()等,表示在不改变数据内存地址的前提下,对数据的值进行修改,但是叶子结点不能进行原位操作,具体原因仍然通过下面的计算图说明:
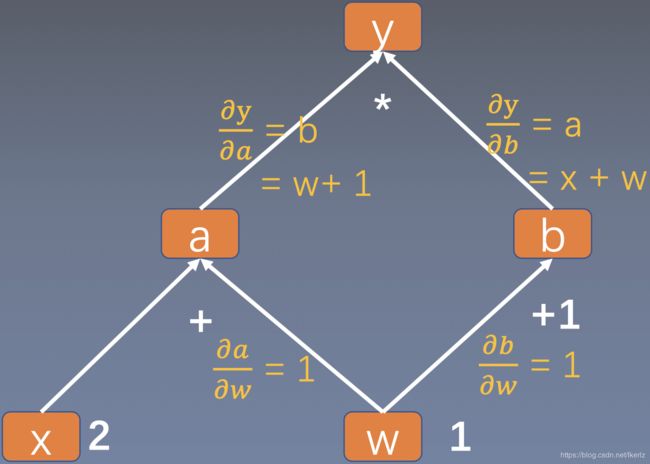
如果要求解w的梯度,需要用到 ∂ y ∂ a \frac{\partial y}{\partial a} ∂a∂y而 ∂ y ∂ a = w + 1 \frac{\partial y}{\partial a}=w+1 ∂a∂y=w+1,也就是在反向传播的时候是需要用到叶子张量 w w w的。而在前向传播的时候, y y y会记录 w w w的地址,到反向传播的时候,在用到 w + 1 w+1 w+1的时候根据地址去寻找 w w w的数据。如果在反向传播之前改变了 w w w的地址当中的数据,梯度求解就会出错,这就是叶子结点不能执行原位操作的原因
#################### 梯度不自动清零 ##########################
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
for i in range(4):
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
# w.grad.zero_()
# 不注释 w.grad.zero_() :
# tensor([5.])
# tensor([5.])
# tensor([5.])
# tensor([5.])
# 注释 w.grad.zero_():
# tensor([5.])
# tensor([10.])
# tensor([15.])
# tensor([20.])
################# 与叶子节点相关联requires_grad默认为True #########################
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
print(a.requires_grad, b.requires_grad, y.requires_grad)
# True True True
################# 与叶子节点无法in-place操作 #########################
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
w.add_(1)
y.backward()
# Traceback (most recent call last):
# File "/tmp/pytorch学习/WeekOne/lesson-5.py", line 99, in 2、实战:逻辑回归的Pytorch实现
(1)逻辑回归理论
- 逻辑回归是线性的二分类模型:
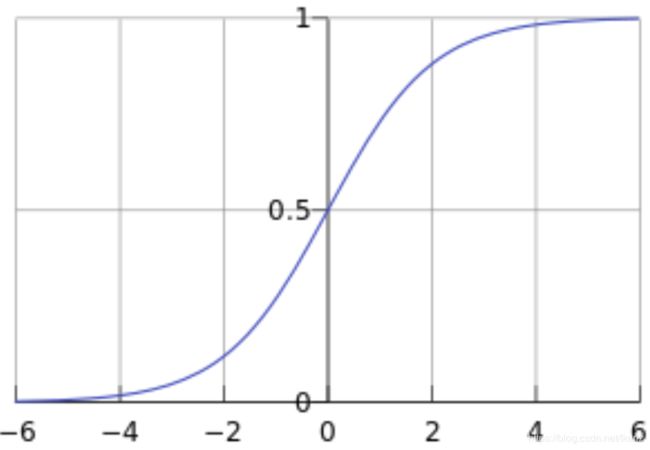
- 模型表达式: y = f ( W X + b ) y=f(W X+b) y=f(WX+b),其中 f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1,称之为Sigmod函数,也称为Logistic函数,大致图像为:
- 分类依据:
f ( x ) = { 0 , 0.5 > y 1 , 0.5 ⩽ y f(x)=\left\{\begin{array}{l} 0,0.5>y \\ 1,0.5 \leqslant y \end{array}\right. f(x)={0,0.5>y1,0.5⩽y - 逻辑回归与线性回归的关系:
- 线性回归是分析自变量 X X X与因变量 y y y(标量)之间关系的方法而逻辑回归是分析自变量 X X X与因变量 y y y(概率)之间关系的方法
- 线性回归模型中自变量为 X X X,因变量为 y y y,两者之间的关系为 y = W X + b y = WX + b y=WX+b,而逻辑回归相当于是在线性回归的基础上加了一个激活函数
sigmoid,从sigmoid函数的曲线图可以看出,基本没有激活函数sigmoid,逻辑回归模型仍然可以进行二分类的,将 W X + b > 0 WX+b>0 WX+b>0分类为类别1,当 W X + b < 0 WX+b<0 WX+b<0时判别为类别0,但是为了更好地描述分类置信度,所以采用sigmoid函数将输出映射到0-1,符合一个概率取值 - 逻辑回归还有一个别名是对数几率回归,几率是概率取值 y 1 − y \frac{y}{1-y} 1−yy,表示的是样本 x x x为正样本的可能性,对数几率回归公式为: ln y 1 − y = W X + b \ln \frac{y}{1-y}=W X+b ln1−yy=WX+b,下面推导该公式与之前的逻辑回归公式等价:
ln y 1 − y = W X + b ⇒ y 1 − y = e W X + b ⇒ y = e W X + b − y ∗ e W X + b ⇒ y ( 1 + e W X + b ) = e W X + b ⇒ y = e W X + b 1 + e W X + b = 1 1 + e − ( W X + b ) ⇒ y = f ( W X + b ) , f ( x ) = 1 1 + e − x \begin{aligned} & \ln \frac{y}{1-y}=W X+b \\ \Rightarrow&\frac{y}{1-y}=e^{W X+b}\\ \Rightarrow&y=e^{W X+b}-y * e^{W X+b}\\ \Rightarrow&y\left(1+e^{W X+b}\right)=e^{W X+b}\\ \Rightarrow&y=\frac{e^{W X+b}}{1+e^{W X+b}}=\frac{1}{1+e^{-(W X+b)}}\\ \Rightarrow& y = f(WX+b), \quad f(x) = \frac{1}{1+e^{-x}} \end{aligned} ⇒⇒⇒⇒⇒ln1−yy=WX+b1−yy=eWX+by=eWX+b−y∗eWX+by(1+eWX+b)=eWX+by=1+eWX+beWX+b=1+e−(WX+b)1y=f(WX+b),f(x)=1+e−x1
(2)Pytorch实现
# 第一步:生成数据
# 参数:
sample_nums = 100
mean_value = 1.7
bias = 1.5
# 生成二分类数据
n_data = torch.ones(sample_nums, 2)
x0 = torch.normal(mean_value * n_data, 1) + bias
y0 = torch.zeros(sample_nums)
x1 = torch.normal(-mean_value * n_data, 1) + bias
y1 = torch.ones(sample_nums)
train_x = torch.cat((x0, x1), 0)
train_y = torch.cat((y0, y1), 0)
# 第二步:选择模型
class LR(nn.Module):
def __init__(self):
super(LR, self).__init__()
self.features = nn.Linear(2, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x = self.features(x)
x = self.sigmoid(x)
return x
lr_net = LR() # 实例化逻辑回归模型
# 第三步:选择损失函数
loss_fn = nn.BCELoss()
# 第四步:选择优化器
lr = 0.01 # 学习率
optimizer = torch.optim.SGD(lr_net.parameters(), lr=lr, momentum=0.9)
# 第五步:训练模型
for iteration in range(1000):
# 前向传播
y_pred = lr_net(train_x)
# 计算 loss
loss = loss_fn(y_pred.squeeze(), train_y)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
# 清空梯度
optimizer.zero_grad()
# 绘图
if iteration % 20 == 0:
mask = y_pred.ge(0.5).float().squeeze() # 以0.5为阈值进行分类
correct = (mask == train_y).sum() # 计算正确预测的样本个数
acc = correct.item() / train_y.size(0) # 计算分类准确率
plt.scatter(x0.data.numpy()[:, 0], x0.data.numpy()[:, 1], c='r', label='class 0')
plt.scatter(x1.data.numpy()[:, 0], x1.data.numpy()[:, 1], c='b', label='class 1')
w0, w1 = lr_net.features.weight[0]
w0, w1 = float(w0.item()), float(w1.item())
plot_b = float(lr_net.features.bias[0].item())
plot_x = np.arange(-6, 6, 0.1)
plot_y = (-w0 * plot_x - plot_b) / w1
plt.xlim(-5, 7)
plt.ylim(-5, 7)
plt.plot(plot_x, plot_y)
plt.text(-8, 1, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.title("Iteration: {}\nw0:{:.2f} w1:{:.2f} b: {:.2f} accuracy:{:.2%}".format(iteration, w0, w1, plot_b, acc))
plt.legend()
#plt.show()
plt.pause(0.5)
if acc > 0.99:
plt.show()
break
最终结果:
