支持向量机SVM原理以及sklearn的实现(以及sklearn.svm.SVC参数说明)
一)支持向量机历史
1995年Cortes和Vapnik于首先提出了支持向量机(Support Vector Machine)。因为其可以适应小样本的分类。分类速度快等特点,性能不差于人工神经网络,所以在这之后,人们将SVM应用于各个领域。
二)支持向量机原理
SVM是一种有监督的机器学习算法,解决的是二元分类问题,即分两类的问题,多元分类问题可以通过构造多个SVM分类器的方法来解决。
SVM有两大主要特点,后面我会详细解释。
- 寻求最优的分类边界
正确:对大部分样本可以正确的划分类别。
泛化:最大化支持向量间距。
公平:类别与支持向量等距。
简单:线性,直线或平面。 - 支持基于核函数的升维变换
通过核函数的特征变换,增加新的特征,使得低维度空间中的线性不可分割问题变为高维度空间中的线性可分问题。
三)
现在,我们以一个具体例子来说明SVM的运行原理
图1

如上图所示,有C,P两类点,我需要寻找一条直线,将这些点他们划分。划分方式有很多,上图中,红,绿,蓝三条线,都可以将他们划分出来。那究竟哪一条才是最优的分类边界呢?我们根据最优的分类边界的四大特点一一来分析.
第一,正确:对大部分样本可以正确的划分类别。很显然,上图中,红,绿,蓝三条线都符合。
第二,泛化:最大化支持向量间距。
在SVM中,选择支持向量的时候,会选择间距最大的向量作为支持向量。通过观察,L1,L2两条线上的向量,它们的间距最大,所以把它们选为支持向量。
第三,公平:类别与支持向量等距。
也就是说,分类边界必须在两条支持向量L1,L2正中间。
第四,简单:线性,直线或平面。分类边界必须是直线或者平面。
通过以上分析来看,唯有红色的那条线,才是我们要找的那条线。
四)
如果遇到行线不可分的样本时,又改如何划分呢?
图二

如上图所示,你无法找到一条直线将样本完全分开。
此时,就要用到SVM的第二大特点了,支持基于核函数的升维变换。
在低维空间中不可分的样本通过合适的映射投影到更高维的空间时,很可能在高维空间变得可分。我们将上面的样点,从二维升到三维,如下图所示。
图三

映射到三维空间后的样本点变得可分了,我们可以找到无数个平面(三维空间中的线性函数)将两类训练样本完美分开。但根据寻求最优的分类边界的四大原则,我们最终会求出一个最优的分类超平面。
以上就是非线性SVM算法的运行原理。
五)在使用非线性SVM算法时,我个人觉得最重要的就是核函数的选择。
常用核函数如下:
1.多项式核函数:poly,通过多项式函数增加原始样本特征的高次方程幂,作为新特征。
2.径向基核函数:rbf,通过高斯分布函数增加原始样本特征的分布概率作为新的特征。
3.线性核函数:linear. 该参数不会通过核函数进行维度的提升,仅在原始维度空间中寻求线性分类边界。
六)SVM算法的sklearn实现,以及参数说明
import sklearn.svm as svm
model = svm.SVC(C=1.0,
kernel='rbf',
degree=3,
gamma='auto',
coef0=0.0,
shrinking=True,
probability=False,
tol=0.001,
cache_size=200, c
lass_weight=None,
verbose=False,
max_iter=-1,
decision_function_shape=None,
random_state=None)
参数:
C:SVC的惩罚参数,默认值是1.0
C越大,对误分类的惩罚增大,希望松弛变量接近0,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
关于松弛变量,我这边要解释下:
在大多数情况下,数据并不是完美的线性可分数据,可能会存在少量的点出现在分类超平面的另外一侧。我们希望尽量保证将这些点进行正确分类,同时又保证分类面与两类样本点有足够大的几何间隔。在这种情况下,我们为每一个样本点加上一个松弛变量,允许有小的误差存在。在加入松弛变量后,我们还要在目标函数中加入相应的惩罚参数C,对这个松弛变量起到一个监督克制的作用。两者的关系,有点类似道家的阴阳制衡的关系,此消彼长。
kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’。 如果gamma是’auto’,那么实际系数是1 / n_features。
coef0 :核函数中的独立项。 它只在’poly’和’sigmoid’中很重要。probability :是否启用概率估计。 必须在调用fit之前启用它,并且会减慢该方法的速度。默认为False
shrinking :是否采用shrinking heuristic方法(收缩启发式),默认为true
tol :停止训练的误差值大小,默认为1e-3
cache_size :核函数cache缓存大小,默认为200
class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose :允许冗余输出
max_iter :最大迭代次数。-1为无限制。
decision_function_shape :‘ovo’, ‘ovr’ or None, default=ovr
关于‘ovo’, ‘ovr’的解释:
一对多法(one-versus-rest,简称OVR SVMs)
训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
一对一法(one-versus-one,简称OVO SVMs或者pairwise)
其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。
当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。
详细讲解,可以参考这篇博客:
https://blog.csdn.net/xfchen2/article/details/79621396
random_state :数据洗牌时的种子值,int值,default=None
在随机数据混洗时使用的伪随机数生成器的种子。 如果是int,则random_state是随机数生成器使用的种子; 如果是RandomState实例,则random_state是随机数生成器; 如果为None,则随机数生成器是np.random使用的RandomState实例。
个人认为最重要的参数有:C、kernel、degree、gamma、coef0。
七) 项目实践
原理讲完了,现在,我就用sklearn自带的鸢尾花数据集进行SVM演示。
import numpy as np
import sklearn.svm as svm #导入svm函数
import matplotlib.pyplot as mp
from sklearn.datasets import load_iris #导入鸢尾花数据
iris = load_iris()
x = iris.data[:,:2] # 因为四维特征无法用散点图展示,所以只取前两维特征
y = iris.target
# 可以看到样本大概分为三类
print(x[:5])
print(y)
[out]:
[[5.1 3.5]
[4.9 3. ]
[4.7 3.2]
[4.6 3.1]
[5. 3.6]]
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
# 基于svm 实现分类
model = svm.SVC(C=1,kernel='rbf',gamma=0.1)
model.fit(x,y)
# 绘制散点图
# 绘制类别背景 pcolormesh
# 把整个空间进行网格化拆分,通过拆分出来的
# 每个点根据分类模型预测每个点类别名,填充相应的颜色值。
l, r = x[:,0].min()-1, x[:,0].max()+1
b, t = x[:,1].min()-1, x[:,1].max()+1
n = 500
grid_x, grid_y = np.meshgrid(
np.linspace(l, r, n),
np.linspace(b, t, n))
# 整理结构变为 25万行2列的二维数组
grid_xy = np.column_stack(
(grid_x.ravel(), grid_y.ravel()))
grid_z = model.predict(grid_xy)
# 整列输出,变维:500*500
grid_z = grid_z.reshape(grid_x.shape)
# 绘图
mp.figure('SVM RBF', facecolor='lightgray')
mp.title('SVM RBF', fontsize=14)
mp.xlabel('x', fontsize=12)
mp.ylabel('y', fontsize=12)
mp.tick_params(labelsize=10)
mp.grid(linestyle=':')
mp.pcolormesh(grid_x, grid_y, grid_z,
cmap='gray')
mp.scatter(x[:, 0], x[:, 1], s=60, marker='o',
alpha=0.7, label='Sample Points',
c=y, cmap='brg')
mp.legend()
mp.show()
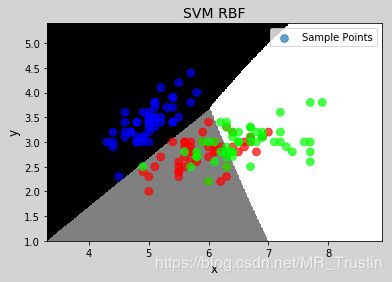
图上,黑,白,灰三个区域,是根据分类模型,把整个网格点分成了三个区域。
图中的三种颜色的圆点,是实际样本点。我们可以看到,蓝色的样本点分类还比较准确,但红色和绿色的较为混乱。之所以,会出现这种情况,是因为,鸢尾花原数据有四个特征,但我为了用散点图进行演示,只选取了其中的两项特征进行分类,所以才出现了这种情况。
在实际项目,模型参数的选择该如何选择,也是一项很重要的工作,下一篇,我将用网格搜索来寻求模型的最优参数。