IntentGC:融合异构信息用于推荐的可伸缩图卷积框架
论文地址:https://arxiv.org/pdf/1907.12377.pdf
论文题目:IntentGC: a Scalable Graph Convolution Framework Fusing Heterogeneous Information for Recommendation
简介:这是阿里提出了一种利用多种辅助节点(brand品牌、shop商户、queryword搜索词)来生成多种邻域节点,从而训练user item的向量,达到推荐的目录,具体的重点描述可以参考:brand品牌、shop商户、queryword搜索词这些辅助信息如果利用图卷积来进行推荐
网络嵌入的显著进步已导致是推荐行业最先进的算法。 但是,user-item交互数据的稀疏性(即明确的偏好)仍然是预测用户行为的一大挑战。 虽然在利用一些辅助信息(例如,用户之间的社会关系)来解决该问题方面已经进行了研究,现有丰富的异构辅助关系仍然没有被充分利用。 此外,以前的工作依赖于线性组合的正则化器,并且需要进行参数调整
在这项工作中,我们收集了丰富的用户行为和商品信息,并提出一个名为IntentGC(内容图网络)的新颖框架,以利用显式用户偏好和图卷积网络的异构关系。 除了能够建模异质性之外,IntentGC还可以在一个非线性的感知网络上,自动了解不同关系的重要性。 为了将IntentGC应用于Webscale应用程序,我们设计了一个更快的图卷积模型,可以避免不必要的特征之间的交互,并将其命名为IntentNet。 在阿里巴巴上对两个大规模的真实数据集进行的实验和在线A / B测试证明了我们方法的优越性先进的算法。
1引言
随着在线信息的不断增长,推荐系统已成为各种网站(例如,亚马逊,Youtube,阿里巴巴)上有效的关键解决方案,可帮助用户发现有趣的产品或内容。 由于近年来深度学习和网络嵌入的成功,这些推荐系统的功能通常基于以下想法:通过神经学习用户的喜好、item的语义低维表示,可以通过寻找Item的最相似的几个item来进行推荐。
在可以从网站上获得不同信息,用户与项目的交互(点击等)是用来表明用户喜好的最常见、最有效的数据。许多算法通过利用这些显式行为来预测用户的首选商品[12,21]。但是,主要的缺点是这些明确的偏好非常稀疏,这严重限制了推荐模型的能力。另一方面,那里通常是丰富的辅助关系,暗示用户的偏好和item的语义,可以帮助克服稀疏性问题。一些研究工作已经探索了这种辅助关系并证明了它们的有效性[6,7,20]。仅举几例,王等 [6]提出了一种保留user-user社交关系,user-item交互关系的跨域解决方案。 [20]中的作者,利用只用item的同构图,采用DeepWalk方法来保留项目共现(在同一会话中单击)。这些辅助关系广泛存在,可用于改善推荐执行
但是,我们发现所有以前的作品都一种信息,也就是同构图,而忽略了图中的许多其他异构关系。 我们提供了一个说明性的例子,但是,我们发现所有以前的作品都只利用了一种用户辅助信息的类型,或者item的一种属性(参见图1),而忽略了图中的许多其他异构关系。 我们提供说明在图2的电子商务网站上的示例。我们可以看到,用户除了在item上有明确的交互外,还有丰富的辅助信息,例如用户提交的查询词,访问过的商店,首选品牌和属性。 这些辅助关系在捕获更多语义和相关性方面可能很有用。 例如,查询词包含用户需求的内容信息,该信息有效地链接具有相似兴趣的用户以及查找内容相似的商品。 同样,品牌意味着相似的时尚品味,将具有相似的时尚品味的用户链接起来,并为内容相似性提供补充信息。 但是,系统中没有充分考虑这些异构的辅助关系。 在这项工作中,我们关注的是研究统一捕获明确的偏好以及用户和项目的所有异构辅助关系的框架
explicit Preference 显式偏好
Auxiliary RelationsShip 辅助关系

为此,我们扩展了图卷积网络(GCN)实现目标。 GCN的核心思想是概括图结构数据上的卷积神经网络[11,13],其中介绍了内容传播、高水平的表现力,并在结点分类任务上取得了巨大的成功。 最近,Pinterest的研究人员发现项目图采用了GraphSage(最新的GCN模型)推荐相关项目[22]。 但是,他们的问题和解决方案与我们的工作本质上有所不同,原因是:
1)他们的模型只考虑商品信息,而忽略了用户和辅助对象。
2)为了扩大规模,GraphSage需要收集到item的很多clustered minigraphs以重复使用嵌入向量。 但是,很难找到这样的既包含user又包含item的clustered minigraphs上面提到的稀疏问题。 minigraph采样算法很可能以很大的子图结尾(或甚至整个图)。 因此,GraphSage的想法在我们场景中不适合,我们场景中包括大型分布式 user-item 图。
3)他们的方法是针对同构网络提出的,而在这项工作中研究的用户项目图是异构的。
我们的工作。 在这项工作中,我们为大规模推荐提出了一个新颖的基于GCN的框架,称为IntentGC,该框架通过图形卷积捕获了明确的用户偏好和辅助信息的异构关系。 有IntentGC的三个创新点:
- 充分利用辅助信息:我们捕获了大量异构关系以提高推荐的效果。为了促进建模并提高鲁棒性,我们将一阶接近度的辅助关系转换为二阶接近度的更鲁棒的加权关系。例如,如果user1提交查询词“ Spiderman”,则我们认为user1和“ Spiderman”(一阶接近度)之间存在联系。如果user1和user2都提交查询词“ Spiderman”,“ Ironman”,“雷神”,我们认为user1之间存在更牢固的关系和user2(二阶接近度),因为他们可能都是漫威的影迷。使用不同类型的辅助对象,我们可以生成二阶接近度的异构关系。在训练中,IntentGC自动确定不同类型辅助信息的权重关系。我们发现这些异类关系在实践中是有用的并且彼此互补,并且可以大大提高性能。
考虑下时间的业务特征,我们通常都是以user、item、query这些为key,提取很多个特征,然后复杂的可能会做很多处理,不复杂的就直接concat放在第一层,这可能不太好,因为权重是直接把所有特征进行互相交叉到第二层
- 更快的图卷积:为消除在大型分布式图上需要用 clustered mini-graphs 的限制,我们提出了名为IntentNet的新型卷积网络比GraphSage更快、更有效。 IntentNet采用了更快的图卷积机制的关键思想是:IntentNet通过将图卷积的功能,分为两个组件来避免不必要的特征交互:一个带有vector-wise的卷积组件来聚合邻域信息、一个MLP组件来表达节点特征。 受益于这种机制,我们部署了一个分布式架构,用于简单的mini-batch训练(采样节点)。
- 异构网络中的双重图卷积:为了保持用户和项目的异构性,我们设计了双重图网络表示学习的卷积模型。 首先,我们利用两个独立的IntentNet,它们分别在用户节点和项目节点上运行。 非线性投影后通过各自的IntentNet中的完全连接的网络,获得的用户和项目的嵌入可以视为已形成一个公共空间。 然后,在明确偏好的指导下进行训练,可以评估用户与项目中的项目之间的相关性空间。
值得注意的是,与以前使用正则化器[6,7]在目标函数中捕获辅助关系的工作不同,前者是线性的并且在很大程度上取决于手工参数的调整,我们的方法可以通过以下方法通过一个非线性神经网络自动了解不同辅助特征的重要性。 我们注意,辅助信息也可以设计为节点输入特征。 但是,由于复杂神经网络的投影能力,node输入特征不在高阶embedding向量空间附近。 通过将辅助信息进一步建模为转换后的图中的关系,IntentGC可以直接从节点关系中学习这些以提高性能。 实验也证实了这一点。
这项工作的主要贡献总结如下:
1)我们提出了IntentGC,一种有效且高效的图卷积框架。 据我们所知,这是第一项工作在一个模型中统一建立显式偏好、异构关系的模型的推荐框架。
2)我们设计了一种新颖的图卷积网络IntentNet,它具有更快的图卷积机制。 它导致MRR增加22.1%,运行时间减少75.6%。
3)我们在两个大型规模上进行了广泛的离线实验数据集并部署具有生产A / B测试的在线系统在阿里巴巴。 在离线评估中,我们将MRR提高了95.1%,并且在在线A / B测试中,与最佳基准相比,IntentGC显示点击率(CTR)提高了65.4%。
2相关工作
2.1网络嵌入
网络嵌入旨在用低维向量表达图节点,训练的网络结构和属性会保留下来,就像编码器一样。 它可以使各种任务受益,包括推荐。 已经提出了许多有效的网络嵌入算法[10、15、17、19、25]。 我们简要回顾一下其中一些方法这里。 读者可以参考[4,9]进行全面的调查。 DeepWalk [15]在节点上部署了截断的随机游走,以把随机游走经过的数据(eg:node)看做是这个节点的潜在表达。 在这项开创性工作之后,node2vec [10]通过更复杂的随机游走和广度优先搜索扩展了DeepWalk。 SDNE [19]通过联合方法利用一阶接近度和二阶接近度来捕获局部和局部结构。 DVNE [25]学习Wasserstein空间中每个节点的高斯分布,以保留更多属性,例如传递性和不确定性。
尽管已经为同构网络中的表示学习进行了广泛的研究,但实际应用中的图形更可能是异构信息网络(HIN)。 为了利用HIN中的丰富信息,还提出了一些算法来处理异构性[3,5,16,24]。 Metapath2vec ++根据人类的专业知识[5],利用元路径来随机游走,以便最大化偏向转移概率。 HEER通过附加的边缘(节点相连关系)来表示嵌入HIN,以把节点之间的连接关系表达的更充分一点[16]。对于一般的HIN,尽管可以使用这些方法,但是在模型中的重要性,他们将每种关系同等对待,这不适用于增强推荐系统,因为用户与项目之间的关系是预测的主要目标。 当前,很少关注利用异构信息来增强性能推荐。
2.2 Graph Convolutional Networks
近年来,更多地关注卷积的应用图结构数据的神经网络[2,11,13,18]。布鲁纳等人定义傅里叶域中的卷积运算,计算的时候会计算图拉普拉斯算子的特征分解[2]。为了降低卷积的复杂度,Kipf和Welling提出通过局部图过滤器上的一阶相似来简化以前的方法,名为GCN模型[13]。具体来说,他们把每个节点的卷积运算看做所有相邻特征向量的mean-aggregation,再通过MLP层和非线性激活函数进行变换。但是,在他们的模型中,中心节点和邻居节点聚合在一起而不进行训练。最近,汉密尔顿等。提议的GraphSage在归纳法中进一步扩展了GCN方法方式[11]。此技术对固定大小的邻域进行了采样,避免对整个图中的每个节点进行拉普拉斯运算。他们会concat(每个节点的表达向量,这个节点邻域的综合表达向量),取得了显著进步,但先前的研究GCN中的工作主要集中在同构图(图里面只有一种类型的节点)上。在这在工作中,我们提出了一种新颖的算法,该算法将GCN扩展到异构信息网络,并显着提高了推荐的有效性和效率。
2.3 Recommendation
最近,基于深度学习的算法取得了显著成就推荐文献中的成功[23]。 根据是否在模型中捕获用户信息,主要有两个方法类型:1)item-item推荐和2)user-item推荐。 item-item推荐的动机是查找与用户的历史交互项相似的item。 在这类工作中,Wang and Huang等人 [20]采用了DeepWalk附带信息的方法以获得向量表示在项目图上的表达。 Ying等。 [22]提出了一种基于随机游走的方法GraphSage算法(名为PinSage)。
与上述工作不同,我们的方法属于用户项目推荐组[12、14、21]。这组方法旨在直接预测用户的首选商品,这通常与用户的满意度相关,并且由于稀疏性问题而更具挑战性。为了减轻稀疏性的问题,一些作品试图利用其他辅助关系。例如,Gao等人 [7]设计了一种有偏向的随机游走法,利用user-item二部图来推导user-user和item-item直接的关系。 Wang等人 [6]在跨域环境中纳入了社会关系。但是,现有方法仅考虑一种类型的user/item辅助关系,而忽略了图中丰富的异构辅助关系。而且,以前的方法通常会利用正则化器捕获辅助关系,这限制了模型的功能,并且在很大程度上还取决于手工参数调整。在这项工作中,我们提出了一个新颖的IntentGC框架来利用显式偏好和丰富的异构辅助关系。 它可以通过图卷积自动确定各种辅助关系的重要性
3问题定义
我们在数学上提出了推荐问题。 第一,让我们考虑一下电子商务网站上的典型场景:最后一周,杰克查询了一些有一些要求的关键字。 从返回的项目列表中,他单击了一些有吸引力的项目以获取详细信息。 在这一周中,他还参观了一些在线商店以检查新书。 终于在星期六,他购买了几本畅销书以及他最喜欢的品牌的T恤。 根据杰克的行为,平台已收集了丰富的信息(提交的查询词,点击的商品,逛过的商店,首选的属性和品牌),以个性化的方式向他推荐潜在的有趣物品方式。
这种推荐场景也可以在其他网站上观察到。 通常,网站上的多种对象和历史用户行为会形成异构信息网络,如下所示:

HIN网络是一个无向图,g = (v,e),v是一系列的节点(包括各种类型的节点,比如user节点,item节点,品牌节点等,具体可以看上面的图2),e属于v*v,是节点相连边。g和节点类型map-φ有关,这个map的key是v,value是这个v的节点类型T(v),节点类型如果拿上面图2举例的话,那就是user节点,item节点,品牌节点… ;g也和边类型map-ψ 有关,这个map的key是e,value是这个e的边类型T(e),边类型如果拿上面图2举例的话,那就是is has belong buys这种类型的节点,按理说类型不应该取模,但是论文中对他进行了取模,取模我们可以理解为,求节点类型或者边类型的总个数,T(v) 或者 T(e)大于1的话(大于1就说明是异构图,有多种节点),v就可以写成 v =v1 U v2 U…U vr U…U vR,其中vr是r节点类型的集合,R的取值是T(v)(节点类型总数量,要取unique),v就代表是所有类型的节点的集合

User_Item推荐:在当前论文中,我们把v1看做user-noded,v2看做item-nodes,v3 … vR代表了其他object的节点(eg:query brand …),我们把e = e(label) U e(unlabel),就是说边集合是由有label的边和无label的边组成的,e(label)属于v1*v2,代表了user和item直接的连接关系,e(unlabel) = e - e(label)。因为在现实生活中,一个典型的推荐算法是预测用户更喜欢哪个item,我们用g = (v,e) + 历史信息来构建一个图结构,g(p) = (v(p),e(p))来代表真实世界信息的图结构。然后我们把user-item推荐问题看成是一个图结构中的边连接预测问题
Input: 一个hin,基于历史数据g = (v,e)
Output: e(p)(label) 是在g(p)这个真实世界的图上预测出来一个有label关系的边集合,这个label关系,可以是0 1,也可以是浮点型
4 METHODOLOGY
在本节中,我们提出了一个关于HIN user-item 推荐的新颖框架。 我们的方法具有三个关键特征:
i)网络翻译,它将原始图转换为一种特殊的HIN
ii)更快的卷积网络,基于 vector-wise 向量级卷积在最佳意义上放大和合成异构关系的优势;
iii)双重图卷积,可以在翻译后的异构图HIN上学习到user item的向量表示。 最后,我们总结了解决方案的框架。
4.1 Network Translation
如图2所示中的异构节点和关系,为我们不仅提供丰富的信息,而且不相交的语义和更多挑战。尽管对每种类型中,使用特定类型的边缘来进行建模是一种可能的解决方案[16],但是在计算多种类型的节点、边时,高复杂度和计算成本对于大数据是不可行的。幸运的是推荐系统中,我们只关心user、item的表达。因此,我们采用了一种类似于[7,24]的方法将原始辅助信息,转换为user-user关系或item-item关系。直观地,如果用户u1和u2是两者都通过Vr(r> 2)中的辅助节点连接,u1和u2之间肯定也有间接关系。在本文中,我们利用二阶接近度[9]来捕获两个用户(或项目)之间的相似性,由他们共享的相同类型的公共辅助邻居的数量来衡量。在这方式下,我们可以编码辅助节点带来的语义信息,成为user-user或者item-item的异构关系,并相应地翻译HIN。其他基于元路径的随机游走等生成方法也适用于网络翻译,但是我们的方法具有鲁棒性和简单的实现。

为了清楚和易于推导,我们首先考虑这样一种case, V = V1∪V2∪V3, 我们只有一种类型的辅助节点(V1 V2分别是user和item节点,V3就是辅助节点,比如是上面Figure2中的Brand这种辅助节点,用户可以购买某种Brand,item也可以属于某种Brand,这样Brand这种辅助节点就造成了user-user之间或者item-item之间可以有边相连)。 通过向HIN G添加新的二阶关系并从中移除原始辅助关系和节点。we obtained a new and simplified HIN G = (U,V , EU , EV , Elabel),其中U V是用户节点、item节点的集合,这个图关系中就只有user item两种节点,Elabel ⊆ U × V,就和网络翻译前的e(label)一样,因为是user和item直接的关系,自然这个连接边的所属最多就是 U*V。
******EU ⊆ U × U and EV ⊆ V × V 分别是user和item内部的相连关系。为了简单可见,我们假定在每类节点相互之间只有1种类型的edge,不过我们的框架是允许不同类型节点之间有多种连接关系。
******eu(i,j) ∈ EU 是用户节点的相连edge,edge还有一个相似度权重属性su(i,j),代表了原始图中的二阶关系。ev(i,j) sv(i,j)和前面定义一样,相似度权重可以看做上面的由他们共享的相同类型的公共辅助邻居的数量来衡量这块来计算
******因此,我们可以使用SU=[su(i,j)] 和 SV=[sv(i,j)] 来代表EU 和 EV间的权重矩阵关系。
******我们还定义N(ui)是节点ui的邻域节点,长度是p,这p个邻域节点是根据SU SV这个矩阵得来的
有了上面的一些操作,我们可以考虑V = {V1, V2, . . . , VR }有R中类型节点的情况,对于每种辅助节点,我们按照上面的步骤生成 user-user / item-item各自内部的连接边。我们最后可以得到 2*(R-2)种异构关系,为什么是2*,以为上面说过了,我们把user-user item-item拆开来看,这样每种都是 R-2 种异构关系(每种类型的节点内部的连接edge属于1种异构关系),每种异构关系都可以写成EU(r)或者EV(r),代表每类节点中的edge相连关系,并且每类都有一个相似度矩阵,SU(r) SV(r),相应的每个user或者item的邻域节点也可以用N(ui)(r) N(vi)(r)来代表
我们把翻译好的图G叫做user-item HIN,然后整个问题就变成了给定 user-item的HIN G这个图,来预测里面的user和item的连接关系
4.2 Faster Convolutional Network: IntentNet
动机。 GCN的核心思想是通过本地过滤器迭代地聚合邻域中的特征信息。但是,它的主要缺点是计算的高度复杂性。对于例如,一个3层的GCN模型,每个节点会进行100多次卷积运算,对于通常有数亿个节点的大型网络应用来说,这是不可接受的。在以前的作品中,常见方法是使用 mini-subgraph 采样策略[22]。他们开发了生产者-消费者分布式训练方法。在每次迭代中,producer会采样一个聚集的子图M,并在M上执行前向传播,以通过consumer得到所有节点的表达。集群子图是在项目上以广度优先搜索方式生成的图形。这样,GCN在每个采样的子图上只会执行一次,在更新时node-embedding也会被复用(所有训练对都应包含在子图中)。然而,对于用user-item HIN G,很难生成此类聚类的子图用于embedding重用。这是因为user-item之间的edge关系非常稀疏。如果我们用这种办法的话,我们会得到一个非常大的子图,甚至整个图。因此,为了将我们的方法应用于大规模图,我们开发了一种更快的卷积运算,该运算允许普通节点采样。
Vector-wise convolution operation
为了简单起见,我们首先考虑一种类型的辅助关系,然后再扩展到多种辅助关系。我们仅仅使用用户节点来进行解释做法,因为user-node和item-node在G上是相同的结构。一层图卷积包括两个部分,1)聚合邻域节点,2)卷积函数。聚合是一个pooling层,会把邻域的特征信息聚合在一起,可以用下面的公式体现
![]()
其中ha(k-1)代表的是用户a在经过(k-1)词卷积后的向量(假设为128维,这个128维也是比较合适的,毕竟是我们最终求的user的向量),里面的AGGREGATE是一个取平均函数,hN(u)(k-1)代表了u节点的邻居汇总在一起的信息,a是N(u)中的每一个节点,前面已经在 4.1 Network Translation 第2段中说到了,求u的邻域节点是根据相似度矩阵 SU来进行求取,长度是p。
经过聚合,我们需要利用节点本身向量hu(k-1)、邻居信息hN(u)(k-1)(每一个邻居都是一个用户,邻居信息并不是用户和brand prop这些辅助节点的信息 – 即把每个用户有相交的brand prop求embedding向量的平均,然后再concat,并不是这样,而是很简单也是128维度的向量表达,第一次迭代时取正态分布,后面每次就依次迭代即可),所以就将这两个embedding向量聚合起来(128+128=256维度),再过一个MLP层,没有非线性激活函数(relu),以便能学到特征交互信息。我们把这种方法称为“bitwise”
![]()
--------------------上面都是在讲述“bitwise”方法,下面是讲述论文新提出来的vector-wise方法

然而,我们观察到用户节点的128维向量和128维辅助节点的向量在进行交互,然而没有必要学到所有的特征对交互。在表达学习期间,在卷积操作中主要有两个任务:第一个是学习node self和邻居信息的交互,这决定了每种邻居信息能怎么程度的来影响最终的结果;第二个是学习embedding空间中不同维度之间的交互,这会找到一些有用的特征组合。例如,用户的年龄和职业(同一节点中的特征交互)可能会建议一些首选类别。 结合了用户的邻居信息到他的表示中,可能有助于推荐相关items。 但是,结合用户的年龄和评分特征可能毫无意义。 基于此观察结果,我们在以下方面设计了向量级卷积函数:
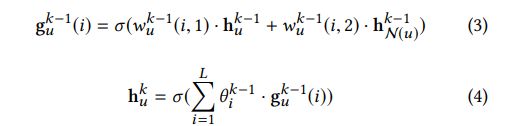
wu(k-1)(i,1)和wu(k-1)(i,2) 分别代表着node-self的权重、第i个局部滤波器的权重,也就是用户节点本身、和、一个辅助信息 进行交互的各自权重,上面公式3中的每一个本地滤波器可以看做是 节点本身和邻居信息的交互。在所有的局部滤波器(所有的辅助信息)都被学习后,我们利用公式4中的办法来把他们聚合到huk中,以便下一次卷积操作。
多个局部卷积层确保了信息直接可以有效的进行交互,这种思路是借鉴了cnn。这些权重是共享的。Bitwise和vector-wise的区别可以用图3表名,不管是Bitwise还是vector-wise,我可以看做是在 XK = R(N*M*C)上操作,N是节点数,M是邻居数,V是节点的表达维度。
可以这样理解:若只有一个节点,有M个邻居,自身是C维的表达,那么就是M*C的空间,有N个节点,那就是N*M*C的空间,对比bit-wise来说,因为把self-node和邻域信息concat在一起,所以就是 一维CNN卷积,vector-wise可以看做是多个一维CNN卷积
IntentNet
通过提出的卷积运算,我们可以建立堆叠的卷积层以形成网络,这很高效且能够从中学习有用的邻域交互关系。但是,这只能完成一种维度下(低维、高维的区别)的卷积,因此我们通过三个附加的全连接层进一步提供最后一个卷积层的输出表示,以学习向量空间中不同维度下各层之间的特征交互。我们称这种方法作为IntentNet,其核心思想是将图卷积的工作分为两个部分:vector-wise用于学习邻域的作用,mlp层用于学习节点级别的特征组合。实际上,IntentGC不仅比传统的GCN更高效,而且更有效。一个可能的原因是IntentGC可以避免无用的要素交互,并且对过度拟合做了限制。更多细节将在5.3节中介绍。
Complexity
我们在每层的表达中,都使用m维,因为固定维度的向量在顺序上的大小有一定的相似性。首先,我们分析下卷积的复杂度。如果用户A有p个邻居,每一个卷积层首先需要聚合(pooling层,可以取平均),因为每个邻居有各自的p个邻居,所以每个邻居都要把各自的p个邻居的辅助信息(每个邻居就是128维向量)给聚合在一起,这样就会有p次聚合,每次聚合的维度是m,所以复杂度是O(p*m);vector-wise中,共L次局部卷积(公式3),每次卷积都是在m维度上操作,所以复杂度是O(m*L),所以总复杂度是O(m*(p+L)),因为p<
假设一次图卷积有q次迭代,第r次迭代需要这么多次卷积操作
(1+ρ+· · ·+ρ(q−r) ) =(ρ(q-r+1) – ρ) / (ρ -1),这里要注意两点
1:数学公式,x0 + x1 + x2 + … + xn = x(1-xn) / (1-x) = x(xn-1) / (x-1)=(x(n+1) – x) / (x-1)
2:论文中说的第r次迭代,应该是说总共有r次迭代的话,会有多少次卷积,具体我会在笔记中画图说明,那么如果有q次迭代的话,论文中提到的算法 / GraphSage 都有 ρ+ρ 2+···+ρ q−ρ / (ρ-1) ≈ρ(q – 1)次图卷积操作。总的来说,IntentNet花费时间复杂度是 O(ρ q−1 ∗m+m2 ),其中m2是q词卷积后的多个mlp层,GraphSage就需要花费O(ρ q−1 ∗ m2 ),明显看到IntentNet就高效多了,具体的推导会在笔记中画图说明
Heterogeneous relationships
我们现在把 IntentNet扩展到多种异构信息,考虑到 EU = E (1) U ∪E (2) U ∪· · ·∪E (R−2)U,也就是有R-2中用户关系,在这种情况下,公式3可以被写成下面这样
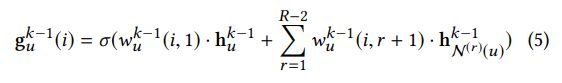
前面没有对公式3进行解释,现在结合公式5一起说下:公式3中,hu(k-1)是128维度的用户向量,hNu(k-1)是这个用户的10个邻域节点取平均组成的128维度的向量,公式3中,i的取值是1~L,也就是说 wu(k-1)(i,1)也只有L个,这L次相乘中,每一次hu(k-1)、hNu(k-1)都是不变的变的只有 两个权重向量 wu(k-1) (i,1)和wu(k-1)(i,2),我暂时还没想明白,这样做是出于什么目的,前面论文有说明因为不想node-self和邻域信息一股脑的进行交互,想要把特征之间有区别的分开交互,使得每种特征之间有不同权重的交互,公式3中进行L次,每一次给node-self和邻域信息先乘以个权重,这个权重到底是什么样子?wu(k-1) (i,1)是一个浮点型数字、还是一个128维度的向量,在论文中公式3下面有说wu(k-1) (i,1)是第i个局部卷积核(过滤器),我想应该是128维度的向量
wu(k-1)(i,1)这个128维度的向量 与 hu(k-1)这个128维度的向量相乘,我们将hu(k-1)这128个数字每个数字都看做是一个特征(从某种意义上可以这样看),每个数字都乘以一个数字后,相当于对每个特征的不同打压;wu(k-1)(i,2)和hNu(k-1)类似;然后再相加,是论文中Figure 3 前面那一段中说到的卷积的两个目的的之一:学习selfnode和邻居信息的交互,后面紧接着的公式4
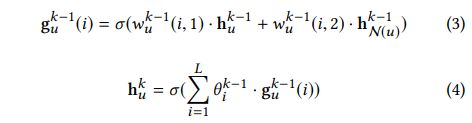
是 selfnode和邻居信息的交互完毕后,θi(k-1)意在将前面L次学习的结果再次学习不同特征之间的交互,维度也是128维(具体可以参考Figure 3中的Vector-wise)
从公式3转到5,公式3中,因为只有一个邻域信息(因为只有一个辅助节点,一个辅助节点对应一个EU,一个EU对应一个SU,就只能求出来一种邻域节点),到了公式5,因为有了好几种邻域信息(brand shop queryword)等,所以辅助节点就对应了好几个EU,自然有好几个SU,也就好几种邻域节点,公式3中在对hNu(k-1)乘以权重向量 到了公式5就变成了对(R-2)种hNu(k-1)分别乘以权重向量再sum,这个很好理解

前面所说的所有信息可以汇集成上面的Figure-4,先看layer1中的每一个小块,其中每一个小块就对应的是公式3,总共有(R-2)个小块,一起加起来就对应着公式5;再看layer2,前面部分就对应的是公式4,把公式5输出的每一个gu (i)(k-1)给混合在一起,但是公式4只体现了直接混在一起,并没说是几个MLP,Layer2中说明了是3个MLP层,最后输出用户的向量
4.3 HINDI中的双图卷积
为了处理用户和项目之间的异质性,我们提出双图卷积模型以同时学习user和item的嵌入。 我们用xu和xv代表用户u和item的输入特征向量v。 此外,我们还为每个正样本抽取了负样本以形成完整的训练集,例如(xu,xv,xneg),负样本会用作训练过程中的对照。
我们为用户使用了两个IntentNet,IntentNet(u)和IntentNet(v)。 通过像等式(1),等式(5)和等式(4)还有后面的dense层迭代后,我们可以通过以下方式获得最终user和item表示形式zu,zv:IntentNetu和IntentNetv分别。 尽管user空间和item空间之间存在语义鸿沟,但另外三个IntentNet的MLP层可以在投射user和item时,使得两者在同一嵌入空间。 此外,我们还获得在IntentNet(v)的训练元组中对采样的负样本的zneg
Loss函数是

这种三重态损失被称为最大边距方法,其中δ表示边距超参数,并且使用内积来表示测量用户节点和项目节点之间的相似性得分。核心思想是用户与有链接关系的item之间的内积应该高于用户与负样本之间的内积。 最小化公式(6)实际上可以使得用户与有链接关系的item之间的内积越来越高,与负样本越来越低,从而形成一个模型,如果有高分数代表用户和item可能有边相连。
此外,为了训练一个健壮的模型来区分正项目与相似的负项目,我们在采样负样本的时候,会采个和正样本同一属性的Item,来确保模型能够区分开user在很相似的Items之间的关系
4.4 IntentGC框架
我们总结一些上面提到的算法

整个框架可以分成三个步骤,1)网络翻译 2)训练 3)预测,我们下面会提供一些细节
- 网络翻译
我们算法的输入是一个异构信息网络G,它是由历史数据构建的。 按照第4.1节中描述的方法,我们通过辅助节点生成二阶关系,并将原始的HIN G变换成用户项HIN G(第2行)
- Training
给额定翻译好的图G,我们用下面4步训练模型,
1 初始化,我们初始化所有的参数,获得user和item的特征向量(4~5行),为了简单起见,IntentNet(u)网络中的权重用Ωu代替,Xu = [xu]代表了用户的特征矩阵
2采样,在一个batch中我们生成
3 前向传播,我们输入IntentNetu and IntentNetv的一个Batch后,并且获得了输出向量(line8 ~11)。每一个IntentNet都包含q个图卷积层(用于内容传播),和3个MLP层来计算特征交互
4 参数更新,我们使用梯度下降来最小话loss函数(line 12)
第2 到 4步是不断迭代的,知道遇到停止条件
- Inference
经过训练,我们可以获得所有用户和item的Z维度的向量(line 14~15),并且找到每个user的K个最近邻来用于推荐