今天介绍raw hammer攻击的原理;这次有点“标题党”了。事实上,raw hammer是基于DRAM内存的攻击;所以理论上,只要是用了DRAM内存的设备,不论是什么cpu(intel、amd,或则x86、arm架构),也不论是什么操作系统(windows、linux、ios、arm等),都可能受到攻击;常见的raw hanmmer攻击效果:
- 提权+宕机,却无需利用软件层面的任何漏洞
- 打破进程间隔离、user-kernel隔离、VM间隔离以及VM-VMM间隔离,对内存地址的内容进行读+写,却无需访问该内存地址
1、DRAM 原理

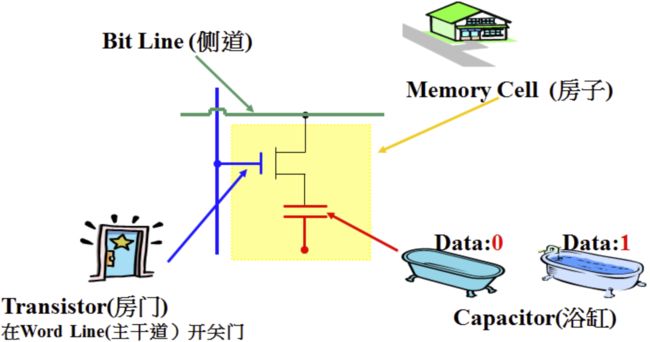
如右上图:
(1)内存最基本的存储单元是cell。cell里面最核心的两个模块:电容和晶体管;电容充满电,cell就是1;电容放完电,cell就是0;晶体管用来控制电容充放电;DRAM的D代表dynamic,中文叫动态,说的就是这个;
(2)DRAM的每一组存储单元行与列组成的矩阵称之为bank,如图中示例row 0 –row 4组成的矩阵为一个bank;
(3)每一个DRAM芯片都包含多个bank, 每一个bank都有自己的一块row-buffer,这个row-buffer其实是一排灵敏放大器(Sense Amplifier)。在每次访问内存时,一个存储单元行会被激活,将整个row的数据保存在row-buffer之中,同时cell放电,然后将row-buffer的上下文写入原来的存储单元行之中,cell充电;即使是读内存,也会导致cell充放电!
(4)每个cell不停的充放电,组成010101的二进制串,这就是最底层数据存储的基本原理;磁盘上的任何文件在内存都会被编码成010101的二进制串;
2、row hanmmer原理
(1) 近年来,消费者IT设备的要求越来越高;设备厂商在不改变内存电路板面积大小的前提下,为了让其能够存储更多的数据,只能将cell的设计越做越多,排列越来越近,密度大幅度增加。虽然制作工艺有所提升,但还是会存在一种假设,那就是相邻的cell在运行中可能会受到干扰,如果频繁“轰炸”某两行(行话称之为row),就可能会造成中间一排腹背受敌、上下夹击,从而出现比特位翻转,也就是0变成1,1变成0..........
业内把这种上下敲击的疯狂操作,称为double-sided Rowhammer test,而导致比特位翻转的这个攻击方式就叫做Rowhammer攻击;Row是行,Hammer是反复敲击,如此简洁明了,一针见血;如下图:第1、3行是aggressor行,这两行中间夹了victim行;两行aggressor不停地充放电,中间victim行大概率会0~1反转;
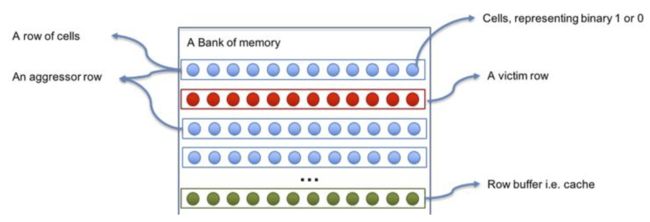
上面的图再细化一下:比如下面9个cell,只有中间是0,周围全是1,由于cell之间间隔很小,中间的0大概率会反转成1。如果周围全是0,只有中间是1,那么中间的1大概率会反转成0;

为了避免这种反转带来的数据错误,x86计算机使用内存控制器定期刷新电容电量,即指定一个电量阈值0
(2) 知道了物理地址,怎么确认该地址映射到那行row、哪列colume、哪个bank了?
百度安全实验室发明基于timing channel的方法(https://cloud.tencent.com/developer/article/1620354 ),大概的思路是:从物理地址高位开始,选择某个bit不同的两个地址分别读取数据;如果这两个地址属于同一个bank、同一个row,那么第一个地址在row buffer会有缓存,第二个地址读的时间会较快,时间差异较大;如果在不同的bank,或在同一bank但不同row,那么读第二个物理地址数据的时候row buffer没有,前后两次读取时间差距不大,由此确认该bit是否是row bit;用类似的思路进一步确认colume bit、bank bit,其最终测试结果如下:
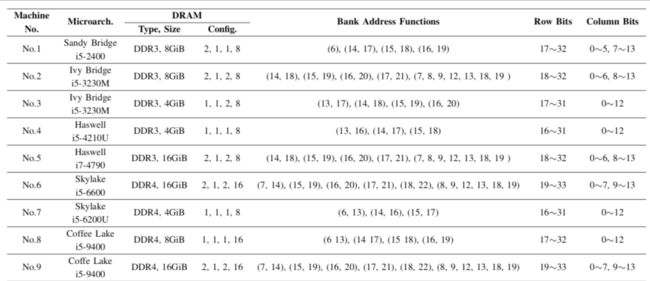
Config表示如下参数:#channel,#DIMM/channel,#rank/DIMM,#bank/rank;
bank address function:比如No.8,bank 地址有4bit组成,一共有2^4=16个bank;每位是括号的这两个bit异或得到的,比如第1位就是物理地址中的6和13位异或的结果;
由上表可知:不同类型的cpu、不同内存大小都有各自的row bit、colume bit、bank bit,情况比较复杂;官方暂未开放DRAMDig工具下载使用,也未开源,实际效果暂时无法评测;
3、row hammer利用方法
- 缓存刷新
在64ms的窗口期间,反复读取x、y两行内存地址的数据到寄存器,然后通过cflush清空缓存(保证cpu下次从内存读),再通过mfence指令保证cflush指令执行完毕;如果x、y两行地址中间夹了一行V(X\Y\V必须在同一个bank中),那么V的数据大概率会被反转;试想:如果V中的某些位是权限控制位了?比如goole project zero自称成功反转了PTE的某一位,成功获得了内核权限;
code1a: mov (X), %eax // Read from address X mov (Y), %ebx // Read from address Y clflush (X) // Flush cache for address X clflush (Y) // Flush cache for address Y
mfence jmp code1a
- 缓存驱逐(cache eviction)
上面的缓存刷新方法需要反复调用cflush指令,如果把cflush禁止(比如google 沙箱)后该怎么办了?
先介绍一下L3 cache:L3 Cache又被称为Last Level Cache(LLC),L1是通过虚拟地址来索引的,而L3是通过物理地址进行索引的,下面以典型的Intel core i7 4790处理器为例介绍L3的结构。i7 4790 L3 Cache由2048个cache set组成,每个cache set又分为4个slice(slice和cpu core数量相同,意义对应,比如这里有4个slice,那么cpu有4个core),每个slice由16个cache line组成,因此缓存关联度为16(英语称为16 way associative);每个cache line 有64byte,因此缓存总容量为: 64×16×4×2048=8MiB;(https://bbs.pediy.com/thread-256190.htm 有详细的介绍)

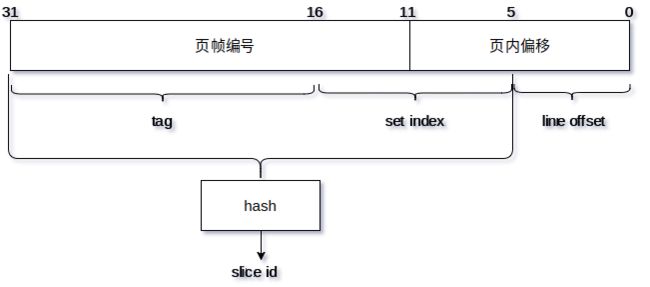
从物理地址映射关系来看,L3的基本存储单元是64字节的缓存行,物理地址0~5表示cache line内偏移,6~16位表示set index,一共有2048个set,6~31位经过一个未公开的哈希函数被映射为slice id,17~31位为tag位用来标记slice里面的缓存行;
slice和core的数量一一对应,但core可通过ring bus读写每个slice;换句话说:slice并不是某个core独有的,是所有core共享的;如果core读取的slice编号不同,需要通过ring bus传输(准从interl quickpath interconnect协议),耗时会增加1~2 hops;

详细的物理地址cache mapping方式:(1)根据0~5bit定位到cache line内部的byte偏移,名为offset; (2) 根据6~16(不同cpu的cache size、way等不同,这里会有略微差异)定位cache set,名为index;以本人intel core-i7 8750为例, 用cpu-z查是coffee lake架构,L3=9M,12way, cahe line=64byte(0~5位是offset); cache line总数=9M/64byte=147456个;cache set数量=cache line总数/way = 12288,需要17bit, 所以物理地址的6~23bit是index(2)根据tag和set index定位slice id(index未公开hash算法);(4)根据tag定位cache sets里面的某个cache line(遍历某个set,取出每个line的tag挨个对比,和物理地址的tag一样就是cache hit);这个cache mapping的很重要,后续好多基于时间差的侧信道攻击(prime+probe、flush+reload、flush+flush、evict+reload等等)都要用到这个cache mapping的思路;
当L3 Cache发生cache miss时需要从内存中调取数据进入L3的某个slice,而此时如果slice已满则会导致某个缓存被写回(write back)内存,进而腾出空间给新进入的缓存行,这个替换策略就是缓存替换算法。Intel的第二代SandyBridge架构使用的是LRU替换策略,然而从第三代IvyBridge架构开始引入了自适应缓存替换策略(Adaptive Replacement Policies),该策略可以动态调整缓存替换算法使得L3的动态负载性能最优化。 由以上分析可知,物理地址被映射到某个set的某个slice,如果能够找到其他16个映射到相同slice的物理地址,使用适当的遍历策略访问这16个地址就可以将这些物理地址驱逐出整个缓存,这种方法可以达到与clflush指令的相同效果,我们将这16个地址(一共64byte,刚好是一个cache line)组成的集合称为最小驱逐集(Eviction Set);由此引申出了新的攻击方法:cache eviction;https://github.com/IAIK/rowhammerjs 这里有利用eviction的js代码(相比 clflush 指令更具一般性,它适用于任意系统架构、编程语言及运行环境),感兴趣的可以自行尝试;
- 内存重复数据删除
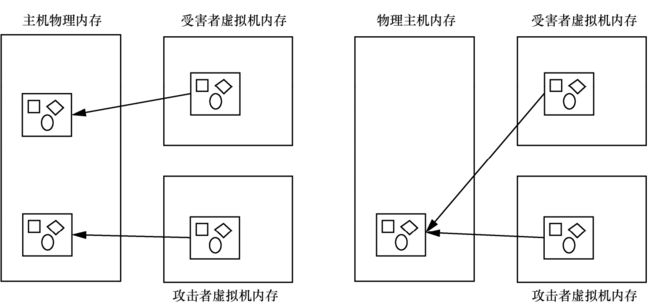
物理内存总是有限的,不可能无限制分配和使用。为了节约物理内存,操作系统会合并多个相同的物理页,只保留一份,其余的删除(32位的windows,每个进程有4GB的虚拟地址空间,高2GB的内核空间在各个进程都是共享的。一旦修改内核数据,会先拷贝一份,然后修改拷贝的这个页,这就是所谓的copy-on-write),以节约大量物理内存;该原理衍射了新的攻击:flip fan shui — 利用内存重复数据删除实施受控的row hammer攻击;
如下图,在云主机中,一般会有多个虚拟机在同时运行。attacker伪造一个victim内存空间一样的页面,底层的操作系统会合并,那么attacker和victim都指向了同一页面;attacker再通过row hammer修改victim的内存数据;
- 内存伏击
如下:空白方格代表空闲页面,灰色方格代表已分配给页缓存的页面,图 5(a)表示刚开始内存的使用情况,内存中还有部分空闲页面,图 5(b)将 所有的空闲页面分配给页缓存,同时将目标页 B 从内存中驱逐出去,图 5(c)是将目标页 B 重新 加载到内存中,这时目标页 B 会被加载到不同 位置的物理内存中,重复图 5(b)和图 5(c),直到目标页B被加载到能够发生位反转的物理内存位置 X 上;利用该技术,可实现云端的DDoS 攻击和本地的提权攻击;

参考:https://cloud.tencent.com/developer/article/1620354 逆向DRAM地址映射
https://bbs.pediy.com/thread-256190.htm Intel处理器L3 Cache侧信道分析研究
https://www.youtube.com/watch?v=rGaF15-ko5w Rowhammer attacks explained simply


