支持向量机(SVM)理解以及在sklearn库中的简单应用
1. 什么是支持向量机
- 英文Support Vector Machines,简写SVM . 主要是基于支持向量来命名的,什么是支持向量后面会讲到…….最简单的SVM是用来二分类的,在深度学习崛起之前被誉为最好的现成分类器,”现成”指的是数据处理好,SVM可以直接拿来使用 …
2. 名词解释
2.1线性(不)可分 , 超平面
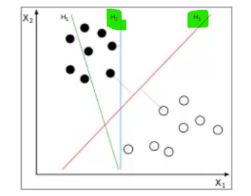
上图 线性可分(绿色荧光笔直线),即一条直线完美分类,虽然有不同的分割法,这条分割线就叫做”分割超平面”,二维中直线就是一个超平面,扩展到n维中n-1维也就是超平面
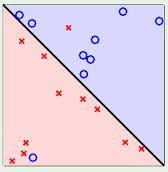 左面这张图很明显,所谓线性不可分,则是一条直线不能完美分类
左面这张图很明显,所谓线性不可分,则是一条直线不能完美分类
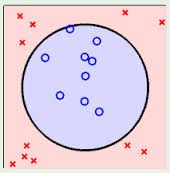 左面这张图也是线性不可分 但是 有一个圆形区域很好的进行了分类
左面这张图也是线性不可分 但是 有一个圆形区域很好的进行了分类
这时候就可以映射到高维,见下例
面 到 体 : 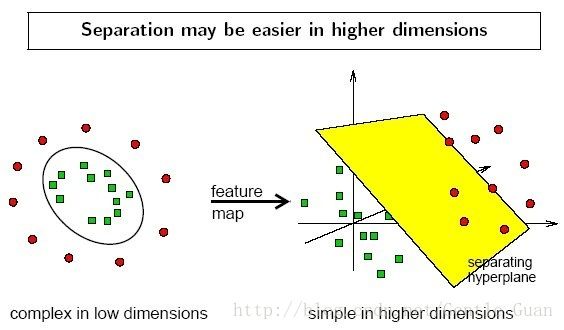
线 到 面 : 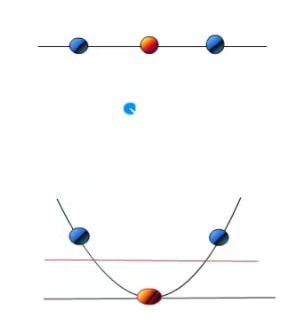 这个例子就比较好理解了,主要是怎么映射? 见下内容….
这个例子就比较好理解了,主要是怎么映射? 见下内容….
2.2 支持向量
支持向量在SVM中很重要,名字就看得出来, 在上例中红线为分割超平面,红色的*点就是支持向量点,即离分割超平面最近的点。
3. SVM理解
在二分类问题中,SVM需要的就是寻得一个分割超平面,使margin最大化,见下图,margin就是切割超平面离最近点的距离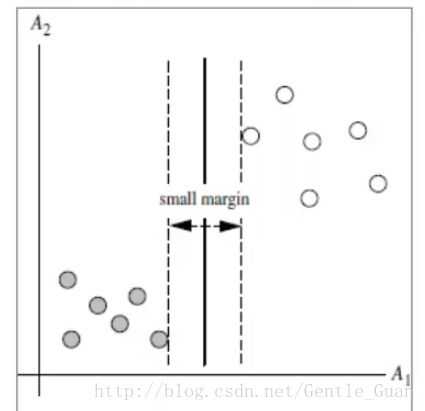
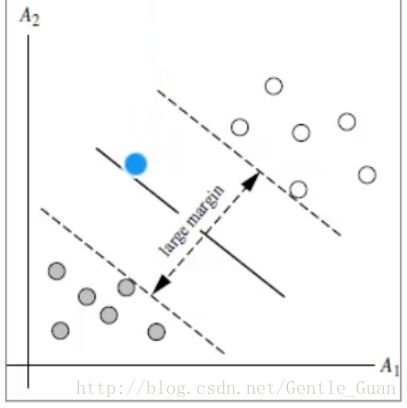
最近的点就是支持向量点,这里的超平面可以定义为 w^X+b=0
假设2维特征向量X=(x1,x2) , 把b想象虚拟的w0 ,
那么超平面方程就变成了 : w0+w1x1+w2x2=0
右上方点满足 : w0+w1x1+w2x2>0
同理,左下点满足 : w0+w1x1+w2x2<0
经过对weight参数的调整,使得
H1:w0+w1x1+w2x2>=1 for y = +1
H2:w0+w1x1+w2x2<=1 for y = - 1 (用y的+1代表一类,-1代表另一类)
综上两式
yi(w0+w1x1+w2x2)>=1,∀i
那么如果线行不可分呢,那就需要映射到高维,例如X=(x1,x2,x3) 那么映射到6维Z函数就可以是 θ1(x)=x1,θ2(x)=x2,θ3(x)=x3θ4(x)=x21,θ5(x)=x1x2,θ6(x)=x1x3,取而代之的方程变为Y=w1z1+w2z2+...+w6z6那么怎么映射呢,(回答:用到的是内积)内积很耗时,所以使用核函数来计算这个内积,使得高维化时间变短,主要的核函数有
- linear : 线性核函数(linear kernel)
- poly : 多项式核函数(ploynomial kernel)
- rbf : 径向机核函数(radical basis function)
- sigmoid : 神经元的非线性作用函数核函数(Sigmoid tanh)
具体介绍还是看看文档吧…..
然后根据核函数就可以进行分类或者回归了…..
4. SVM优缺点
优点
- 支持向量决定时间复杂,而不是取决于数据集的大小
- 结果易于理解
缺点
- 对于参数以及核函数有依赖,原始算法不加修改只用于二分类
- 算法实现比较困难 (依赖sklearn库的话就算了,打脸)
5. sklearn库简单应用实例
# coding:utf-8
from sklearn import svm
from numpy import *
import pylab as pl
# 加载数据集
def loadData(fileName):
dataMat = []
labelMat = []
with open(fileName) as txtFile:
for line in txtFile.readlines():
dataMat.append(map(float, line.split())[0:-1])
labelMat.append(map(float, line.split())[-1])
return dataMat, labelMat
#
if __name__ == '__main__':
x, y = loadData("train.txt")
X, Y = loadData("test.txt")
#'使用线性方法分类'
clf = svm.SVR(kernel='linear')
clf.fit(x, y)
res = clf.predict(X)
print "kernel is linear", corrcoef(Y, res, rowvar=0)[0, 1]
#'使用径向机方法分类'
clf = svm.SVR(kernel='rbf')
clf.fit(x, y)
res = clf.predict(X)
print "kernel is rbf", corrcoef(Y, res, rowvar=0)[0, 1]
#'使用线性最小二乘法进行分类'
x = mat(x)
X = mat(X)
y = mat(y).T
Y = mat(Y).T
temp = x.T * x
ws = temp.I * (x.T * y)
yPre = X * ws
print "linear", corrcoef(yPre, Y, rowvar=0)[0, 1]
''' SVR 支持向量回归 '''
# w^T * x + bias
# weight is .coef_
# bias is .intercept_
random.seed(0)
x = r_[random.randn(20, 2) - [2, 2], random.randn(20, 2) + [2, 2]]
y = [0] * 20 + [1] * 20
clf = svm.SVC(kernel='linear')
clf.fit(x, y)
w = clf.coef_[0]
# print "coef",clf.coef_
a = -w[0] / w[1]
xx = arange(-4, 4)
yy = a * xx - (clf.intercept_[0]) / w[1] # intercept_ bias
# print "bias",clf.intercept_
b = clf.support_vectors_[0]
yy1 = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1]
yy2 = a * xx + (b[1] - a * b[0])
pl.plot(xx, yy, 'k-', color='red')
pl.plot(xx, yy1, 'k--', color='green')
pl.plot(xx, yy2, 'k--', color='green')
pl.plot(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], '*', color='red')
# print clf.support_vectors_
pl.scatter(x[:, 0], x[:, 1], marker='.', s=60)
pl.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
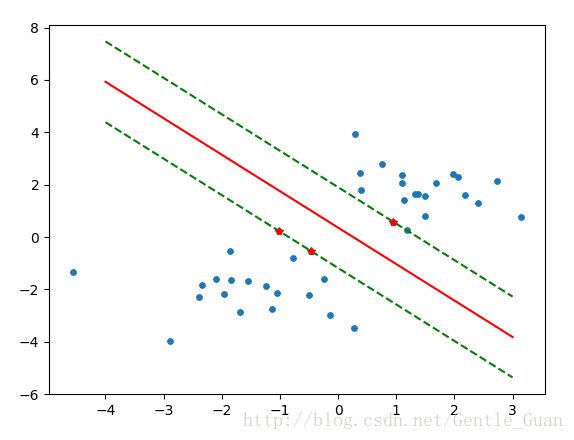
6. 图像结果 以及 分析
# kernel is linear 0.989824485227
# kernel is rbf 0.990336373871
# linear 0.989824485227
'对比发现,简单调用中rbf函数分类效果最好,内核函数linear就是利用了最小二乘法'- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
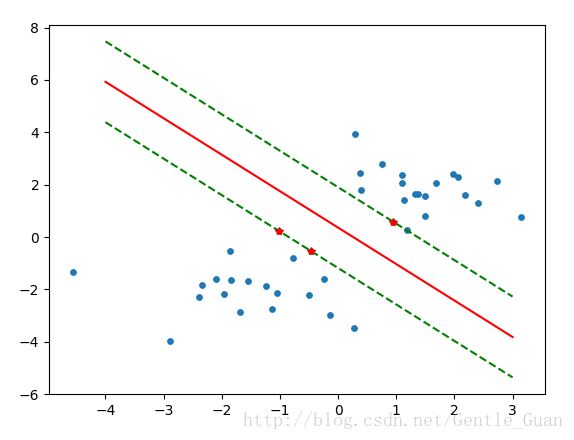
红色为支持向量,红线为切割超平面,绿色虚线为边际超平面,用来’阻挡’两类的超平面