参考资料:
CS224n异闻录(二)
单词(word)、词性(pos)、指向的单词(head)、关系(label)
-
用tensorflow搭建一个简单的线性分类器
主要还是要熟悉tensorflow的编程,其他的很简单。
sigmoid softmax
import numpy as np
import tensorflow as tf
from utils.general_utils import test_all_close
def softmax(x):
"""
Compute the softmax function in tensorflow.
You might find the tensorflow functions tf.exp, tf.reduce_max,
tf.reduce_sum, tf.expand_dims useful. (Many solutions are possible, so you may
not need to use all of these functions). Recall also that many common
tensorflow operations are sugared (e.g. x + y does elementwise addition
if x and y are both tensors). Make sure to implement the numerical stability
fixes as in the previous homework!
Args:
x: tf.Tensor with shape (n_samples, n_features). Note feature vectors are
represented by row-vectors. (For simplicity, no need to handle 1-d
input as in the previous homework)
Returns:
out: tf.Tensor with shape (n_sample, n_features). You need to construct this
tensor in this problem.
"""
### YOUR CODE HERE
max = tf.reduce_max(x,axis=1,keep_dims=True)
reduced_x =x - max
reduced_exped_x = tf.exp(reduced_x)
reduced_exped_sumed_x = tf.reduce_sum(reduced_exped_x,axis=1,keep_dims=True)
out = reduced_exped_x / reduced_exped_sumed_x
# exp = tf.exp(x)
# out = exp / tf.reduce_sum(exp,axis=1,keepdims=True)
### END YOUR CODE
return out
def cross_entropy_loss(y, yhat):
"""
Compute the cross entropy loss in tensorflow.
The loss should be summed over the current minibatch.
y is a one-hot tensor of shape (n_samples, n_classes) and yhat is a tensor
of shape (n_samples, n_classes). y should be of dtype tf.int32, and yhat should
be of dtype tf.float32.
The functions tf.to_float, tf.reduce_sum, and tf.log might prove useful. (Many
solutions are possible, so you may not need to use all of these functions).
Note: You are NOT allowed to use the tensorflow built-in cross-entropy
functions.
Args:
y: tf.Tensor with shape (n_samples, n_classes). One-hot encoded.
yhat: tf.Tensorwith shape (n_sample, n_classes). Each row encodes a
probability distribution and should sum to 1.
Returns:
out: tf.Tensor with shape (1,) (Scalar output). You need to construct this
tensor in the problem.
"""
### YOUR CODE HERE
out = -tf.reduce_sum(tf.to_float(y)*tf.log(yhat))
### END YOUR CODE
return out
def test_softmax_basic():
"""
Some simple tests of softmax to get you started.
Warning: these are not exhaustive.
"""
test1 = softmax(tf.constant(np.array([[1001, 1002], [3, 4]]), dtype=tf.float32))
with tf.Session() as sess:
test1 = sess.run(test1)
test_all_close("Softmax test 1", test1, np.array([[0.26894142, 0.73105858],
[0.26894142, 0.73105858]]))
test2 = softmax(tf.constant(np.array([[-1001, -1002]]), dtype=tf.float32))
with tf.Session() as sess:
test2 = sess.run(test2)
test_all_close("Softmax test 2", test2, np.array([[0.73105858, 0.26894142]]))
print("Basic (non-exhaustive) softmax tests pass\n")
def test_cross_entropy_loss_basic():
"""
Some simple tests of cross_entropy_loss to get you started.
Warning: these are not exhaustive.
"""
y = np.array([[0, 1], [1, 0], [1, 0]])
yhat = np.array([[.5, .5], [.5, .5], [.5, .5]])
test1 = cross_entropy_loss(tf.constant(y, dtype=tf.int32), tf.constant(yhat, dtype=tf.float32))
with tf.Session() as sess:
test1 = sess.run(test1)
expected = -3 * np.log(.5)
test_all_close("Cross-entropy test 1", test1, expected)
print("Basic (non-exhaustive) cross-entropy tests pass")
if __name__ == "__main__":
test_softmax_basic()
test_cross_entropy_loss_basic()
模型
又一次测试案例做的很巧妙,随意生成一些样本及其分类,然后迭代n次后,看loss是否是个很小的数,如果是说明梯度下降有效果。
class Model(object):
"""Abstracts a Tensorflow graph for a learning task.
We use various Model classes as usual abstractions to encapsulate tensorflow
computational graphs. Each algorithm you will construct in this homework will
inherit from a Model object.
"""
def add_placeholders(self):
"""Adds placeholder variables to tensorflow computational graph.
Tensorflow uses placeholder variables to represent locations in a
computational graph where data is inserted. These placeholders are used as
inputs by the rest of the model building and will be fed data during
training.
See for more information:
https://www.tensorflow.org/versions/r0.7/api_docs/python/io_ops.html#placeholders
"""
raise NotImplementedError("Each Model must re-implement this method.")
def create_feed_dict(self, inputs_batch, labels_batch=None):
"""Creates the feed_dict for one step of training.
A feed_dict takes the form of:
feed_dict = {
: ,
....
}
If labels_batch is None, then no labels are added to feed_dict.
Hint: The keys for the feed_dict should be a subset of the placeholder
tensors created in add_placeholders.
Args:
inputs_batch: A batch of input data.
labels_batch: A batch of label data.
Returns:
feed_dict: The feed dictionary mapping from placeholders to values.
"""
raise NotImplementedError("Each Model must re-implement this method.")
def add_prediction_op(self):
"""Implements the core of the model that transforms a batch of input data into predictions.
Returns:
pred: A tensor of shape (batch_size, n_classes)
"""
raise NotImplementedError("Each Model must re-implement this method.")
def add_loss_op(self, pred):
"""Adds Ops for the loss function to the computational graph.
Args:
pred: A tensor of shape (batch_size, n_classes)
Returns:
loss: A 0-d tensor (scalar) output
"""
raise NotImplementedError("Each Model must re-implement this method.")
def add_training_op(self, loss):
"""Sets up the training Ops.
Creates an optimizer and applies the gradients to all trainable variables.
The Op returned by this function is what must be passed to the
sess.run() to train the model. See
https://www.tensorflow.org/versions/r0.7/api_docs/python/train.html#Optimizer
for more information.
Args:
loss: Loss tensor (a scalar).
Returns:
train_op: The Op for training.
"""
raise NotImplementedError("Each Model must re-implement this method.")
def train_on_batch(self, sess, inputs_batch, labels_batch):
"""Perform one step of gradient descent on the provided batch of data.
Args:
sess: tf.Session()
input_batch: np.ndarray of shape (n_samples, n_features)
labels_batch: np.ndarray of shape (n_samples, n_classes)
Returns:
loss: loss over the batch (a scalar)
"""
feed = self.create_feed_dict(inputs_batch, labels_batch=labels_batch)
_, loss = sess.run([self.train_op, self.loss], feed_dict=feed)
return loss
def predict_on_batch(self, sess, inputs_batch):
"""Make predictions for the provided batch of data
Args:
sess: tf.Session()
input_batch: np.ndarray of shape (n_samples, n_features)
Returns:
predictions: np.ndarray of shape (n_samples, n_classes)
"""
feed = self.create_feed_dict(inputs_batch)
predictions = sess.run(self.pred, feed_dict=feed)
return predictions
def build(self):
self.add_placeholders()
self.pred = self.add_prediction_op()
self.loss = self.add_loss_op(self.pred)
self.train_op = self.add_training_op(self.loss)
import time
import numpy as np
import tensorflow as tf
from q1_softmax import softmax
from q1_softmax import cross_entropy_loss
from model import Model
from utils.general_utils import get_minibatches
class Config(object):
"""Holds model hyperparams and data information.
The config class is used to store various hyperparameters and dataset
information parameters. Model objects are passed a Config() object at
instantiation. They can then call self.config. to
get the hyperparameter settings.
"""
n_samples = 1024
n_features = 100
n_classes = 5
batch_size = 64
n_epochs = 50
lr = 1e-4
class SoftmaxModel(Model):
"""Implements a Softmax classifier with cross-entropy loss."""
def add_placeholders(self):
"""Generates placeholder variables to represent the input tensors.
These placeholders are used as inputs by the rest of the model building
and will be fed data during training.
Adds following nodes to the computational graph
input_placeholder: Input placeholder tensor of shape
(batch_size, n_features), type tf.float32
labels_placeholder: Labels placeholder tensor of shape
(batch_size, n_classes), type tf.int32
Add these placeholders to self as the instance variables
self.input_placeholder
self.labels_placeholder
"""
### YOUR CODE HERE
self.input_placeholder = tf.placeholder(tf.float32, (Config.batch_size, Config.n_features), 'input_placeholder')
self.labels_placeholder = tf.placeholder(tf.float32, (Config.batch_size, Config.n_classes), 'labels_placeholder')
### END YOUR CODE
def create_feed_dict(self, inputs_batch, labels_batch=None):
"""Creates the feed_dict for training the given step.
A feed_dict takes the form of:
feed_dict = {
: ,
....
}
If label_batch is None, then no labels are added to feed_dict.
Hint: The keys for the feed_dict should be the placeholder
tensors created in add_placeholders.
Args:
inputs_batch: A batch of input data.
labels_batch: A batch of label data.
Returns:
feed_dict: The feed dictionary mapping from placeholders to values.
"""
### YOUR CODE HERE
feed_dict = {self.input_placeholder:inputs_batch,self.labels_placeholder:labels_batch}
### END YOUR CODE
return feed_dict
def add_prediction_op(self):
"""Adds the core transformation for this model which transforms a batch of input
data into a batch of predictions. In this case, the transformation is a linear layer plus a
softmax transformation:
yhat = softmax(xW + b)
Hint: The input x will be passed in through self.input_placeholder. Each ROW of
self.input_placeholder is a single example. This is usually best-practice for
tensorflow code.
Hint: Make sure to create tf.Variables as needed.
Hint: For this simple use-case, it's sufficient to initialize both weights W
and biases b with zeros.
Returns:
pred: A tensor of shape (batch_size, n_classes)
"""
### YOUR CODE HERE
with tf.variable_scope('transform',reuse=True):
W = tf.Variable(tf.zeros((self.config.n_features,self.config.n_classes)))
b = tf.Variable(tf.zeros((self.config.n_classes)))
pred = softmax(tf.matmul(self.input_placeholder,W)+b)
### END YOUR CODE
return pred
def add_loss_op(self, pred):
"""Adds cross_entropy_loss ops to the computational graph.
Hint: Use the cross_entropy_loss function we defined. This should be a very
short function.
Args:
pred: A tensor of shape (batch_size, n_classes)
Returns:
loss: A 0-d tensor (scalar)
"""
### YOUR CODE HERE
loss = cross_entropy_loss(self.labels_placeholder,pred)
### END YOUR CODE
return loss
def add_training_op(self, loss):
"""Sets up the training Ops.
Creates an optimizer and applies the gradients to all trainable variables.
The Op returned by this function is what must be passed to the
`sess.run()` call to cause the model to train. See
https://www.tensorflow.org/api_docs/python/tf/train/Optimizer
for more information. Use the learning rate from self.config.
Hint: Use tf.train.GradientDescentOptimizer to get an optimizer object.
Calling optimizer.minimize() will return a train_op object.
Args:
loss: Loss tensor, from cross_entropy_loss.
Returns:
train_op: The Op for training.
"""
### YOUR CODE HERE
train_op = tf.train.GradientDescentOptimizer(self.config.lr).minimize(loss)
### END YOUR CODE
return train_op
def run_epoch(self, sess, inputs, labels):
"""Runs an epoch of training.
Args:
sess: tf.Session() object
inputs: np.ndarray of shape (n_samples, n_features)
labels: np.ndarray of shape (n_samples, n_classes)
Returns:
average_loss: scalar. Average minibatch loss of model on epoch.
"""
n_minibatches, total_loss = 0, 0
for input_batch, labels_batch in get_minibatches([inputs, labels], self.config.batch_size):
n_minibatches += 1
total_loss += self.train_on_batch(sess, input_batch, labels_batch)
return total_loss / n_minibatches
def fit(self, sess, inputs, labels):
"""Fit model on provided data.
Args:
sess: tf.Session()
inputs: np.ndarray of shape (n_samples, n_features)
labels: np.ndarray of shape (n_samples, n_classes)
Returns:
losses: list of loss per epoch
"""
losses = []
for epoch in range(self.config.n_epochs):
start_time = time.time()
average_loss = self.run_epoch(sess, inputs, labels)
duration = time.time() - start_time
print('Epoch {:}: loss = {:.2f} ({:.3f} sec)'.format(epoch, average_loss, duration))
losses.append(average_loss)
return losses
def __init__(self, config):
"""Initializes the model.
Args:
config: A model configuration object of type Config
"""
self.config = config
self.build()
def test_softmax_model():
"""Train softmax model for a number of steps."""
config = Config()
# Generate random data to train the model on
np.random.seed(1234)
inputs = np.random.rand(config.n_samples, config.n_features)
labels = np.zeros((config.n_samples, config.n_classes), dtype=np.int32)
labels[:, 0] = 1
# Tell TensorFlow that the model will be built into the default Graph.
# (not required but good practice)
with tf.Graph().as_default() as graph:
# Build the model and add the variable initializer op
model = SoftmaxModel(config)
init_op = tf.global_variables_initializer()
# Finalizing the graph causes tensorflow to raise an exception if you try to modify the graph
# further. This is good practice because it makes explicit the distinction between building and
# running the graph.
graph.finalize()
# Create a session for running ops in the graph
with tf.Session(graph=graph) as sess:
# Run the op to initialize the variables.
sess.run(init_op)
# Fit the model
losses = model.fit(sess, inputs, labels)
# If ops are implemented correctly, the average loss should fall close to zero
# rapidly.
assert losses[-1] < .5
print("Basic (non-exhaustive) classifier tests pass")
if __name__ == "__main__":
test_softmax_model()
Neural Transition-Based Dependency Parsing
下面的分析有一个规律,就是除去ROOT,其他单词只能被箭头指向一次,因为该单词只能修饰别人一次,所以一个句子有多少个单词就有多少个箭头。假设单词个数是N,那么SHIFT的次数也是N,至少有1次RIGHT-ARC,其他的RIGHT-ARC和LEFT_ARC加起来N-1次。
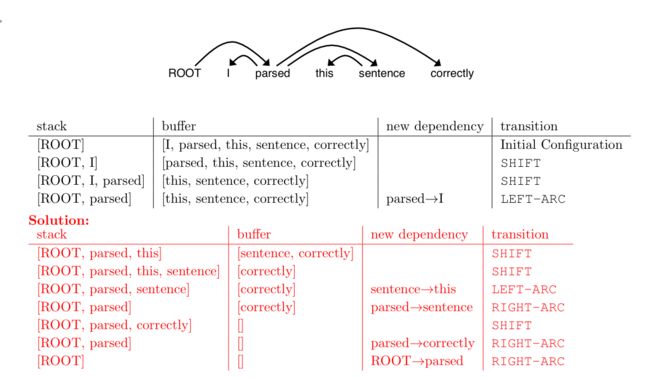
一个句子的分析过程:
初始化后如第一行所示
首先将buffer的一个单词入栈,查看:
1、栈顶有弧线指向左边,如果有,执行LEFT-ARC,也就是创建新的dependency,然后将左边被指向的单词出栈。
2、再看看是否有左边的弧线指向栈顶,如果有,执行RIGHT-ARC,也就是创建新的 dependency,然后将栈顶(被指向的单词)出栈。
3、如果以上都没有,执行SHIFT操作
注意,ROOT指向栈顶的时候不用执行RIGHT-ARC