Python爬虫:10行代码真正实现“可见即可爬”
为什么要写一篇关于爬虫的文章呢?
我是一名大二学生,本学期开设一门《机器学习》课,目前已经学了许多预测模型;我想把这些模型应用于实践,奈何一直没有数据集。几经周转,发现了爬取技术,五一假期简单研究了一下,发现其功能强大、奥妙奇趣。
爬取技术不仅可以爬取我想要的数据集,还可以爬取文字、图片、数据等。虽然网上有无数的爬取代码,但是通用的、简短的、高效的相关代码还有空白。结合这几天的学习,本文将用仅仅十行代码,实现文字、视频、数据、图片等的爬取工作。
因为关于爬虫知识的学习起源于想要获得《机器学习》预测模型的数据集;
从这个层面上说,本文将是后续大量数据预测文章等的开篇之作。感兴趣的小伙伴们点个关注,一起学习交流吖 ~ ~ ~

注:为符合平台审核规范,本文所有数据、网址已全部打码。
目录
Ⅰ 爬虫前的预备知识
Ⅱ python开发环境及第三方库的导入
Ⅲ 具体爬取模板实现
❶文字爬取
❷图片爬取
❸数据爬取
❹视频爬取
❺音乐爬取
Ⅳ 爬取心得
Ⅴ 文章声明
本文开篇,先说一下我对爬虫的理解:
爬虫的过程就好比拿一块磁铁在一堆小金属块(可能有铝、锡、铜等)中将金属铁吸引出来;
将爬取的数据存入电脑就好比将吸引出的铁块装入到指定容器中。

在大数据时代,海量的数据如何进行有效的整理、如何快速提取其中价值高的信息、如何解决“数据丰富而信息贫乏”等现象;
在此背景下,爬取技术应运而生。
本文将以最简单的例子、最常见的内容、最短的python代码阐释什么叫真正的“可见即可爬”。

Ⅰ 爬虫前的预备知识
就本文涉及的爬虫而言,并不需要懂得太高深的知识,知道相关的基础知识即可。
具体而言:
①基本的python编程知识
包括基本语法知识、python环境认知、编译器安装可编译运行以及安装第三方库的技巧等
②基本的HTML编程知识
最好是有HTML和CSS还有JavaScript的知识背景,并利用其进行编程实现简单地静、动态页面的经历
③对HTTP协议结构有初步认知

有哪点不知道也没有关系,后面会在实例中一 一讲解清楚哒。
还在等什么,接着和我一起看看吧^_^
Ⅱ python开发环境及第三方库的导入
本文全部实例由博主亲自编译完成,并在 python 3.8.2 环境下的 pycharm 编译器中测试通过。
本文的相关爬虫代码用到的库包有: requests 工具包、uuid 标示符、PyQuery 第三方库、time 库、json 库。
在第三方库安装方面还迷茫的小伙伴可以参考我的另一篇博文,三招教你安遍所有Python第三方库!
文章链接:https://blog.csdn.net/IT_charge/article/details/105586808
Ⅲ 具体爬取模板实现
前面铺垫了半天,正文终于要开始啦~~~

❶文字爬取
我们可能会遇到这样情况的页面:
这种页面的特点是图大且文字分布无规律,当我们要提取其中的全部或部分文字数据时,就非常耗时费力。
这时我们利用python仅仅10行代码,即可提取全部或指定的文字信息。
第一步:找寻爬取目标页面
本实例就参照上图给出的林肯汽车官网页面,提取其中的全部或部分文字信息。
目标页面 url 在词条中搜索 “林肯汽车” 即可获取
首先要知道,在python中,我们可以使用 requests 工具包来发送HTTP请求。
当然我们可以利用程序得到相应的HTML文件并将其保存到指定文件夹中。
像这样编译器执行如下代码,即可实现上述操作:
import requests
url = " “林肯汽车”官网 URL 填写到这里 "
response = requests.get(url)
with open("car.html",'a',encoding="utf-8") as f:
f.write(response.text)这样我们就可以得到目标页面所对应的 HTML 文件,并将其保存到与 .py 文件相同的根目录下。
HTML 文件(部分)如下截图所示:
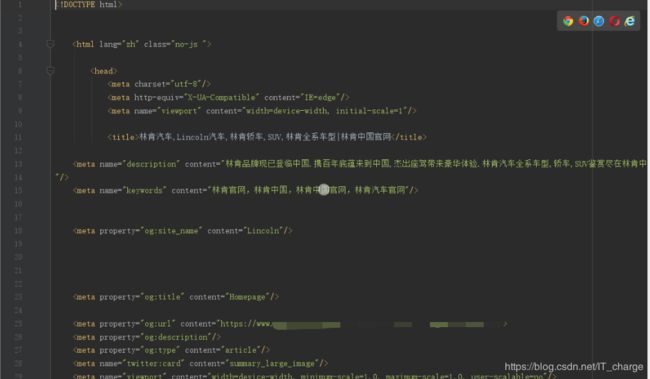
后面的步骤就是依靠得到的这个 HTML 文件进行的。
第二步:找寻爬取目标资源
PyQuery 的三方库的功能非常强大,所以市面上几乎所有的浏览器都可以完成相应操作,选一个你习惯使用的就好。
在目标页面点击 F12 键即可看到下图所示的内容,目标资源就是在这里的 Elements 中寻找。

这里假设我们想要得到有关于“林肯全新数字化购车旅程”的相关文字信息;
具体操作如下图,得到具体目标文字数据在HTML文件中的具体位置。
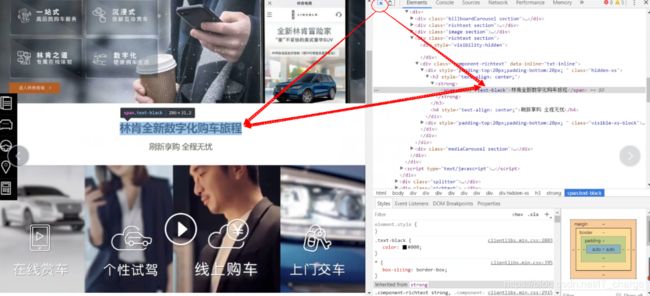
也就是说,我们爬取文字信息时只需注意到class值“text-black”即可。
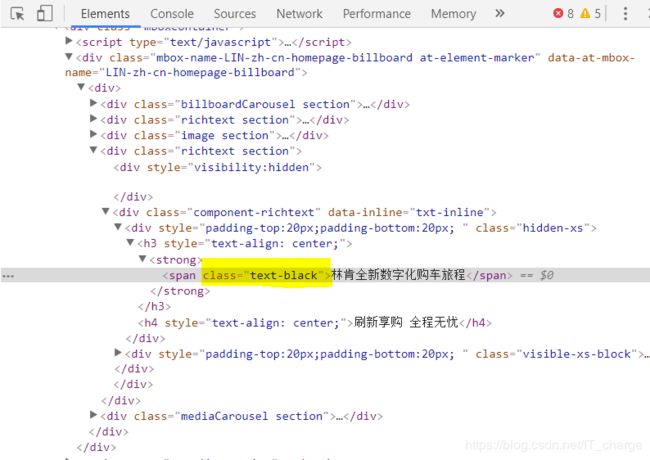
第三步:解析并存储目标资源数据
有了以上两步,通过页面解析我们就可以得到想要的目标文字信息;以我为例,还要将所有数据存储到F盘的文件夹下。
具体代码展示如下:
GetVehicleTextData.py
import requests
from pyquery import PyQuery as pq
carUrl = " “林肯汽车”官网 URL 填写到这里 "
response = requests.get(carUrl)
with open("car.html",'w',encoding="utf-8") as f:
f.write(response.text)
elements = pq(response.text)('.text-black')
file_handle = open("F:/buyCar.txt", mode='w')
file_handle.write(elements.text())
file_handle.close()爬取结果截图

至此,我们可以看到仅仅利用十行代码就实现了指定位置的文字爬取。
当然,如果想同时在 PyCharm 中展示文字结果,在上述代码后加 ![]() 语句即可实现。
语句即可实现。
如果想要爬取本页面全部文字,代码将会更短;有兴趣的小伙伴可以按照上述思路自行练习,这里不再赘述。
哦,对了,我们还可以对提取出来的 .txt 文件通过 wordcloud 库美化一下
相关代码参考如下
from wordcloud import WordCloud
import jieba
def cut(text):
wordlist_jieba = jieba.cut(text)
space_wordlist = " ".join(wordlist_jieba)
return space_wordlist
with open("F:/buyCar.txt")as file:
text = file.read()
text = cut(text)
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simfang.ttf",collocations=False,max_words=100,min_font_size=10,max_font_size=500,).generate(text)
image = wordcloud.to_image()
wordcloud.to_file('F:/burCar.png') 运行结果如下图所示

是不是很简单很有趣很炫酷呢,快动手跑下代码体验一下叭O(∩_∩)O~

❷图片爬取
在词条中输入“***图片”便会跳出大量的图片信息,多数情况下,我们对于相关图片的需求并不只是一张两张;一旦需求量大时,我们就只能将图片一张一张地另存为***,这是就会感叹在大数据面前,人为的一条一条地搜索存取是相当耗时费力的。于是乎,在这一部分我们将会了解到仅仅利用十行代码即可将我们所有想要得到的图片通通存入本地磁盘……
这时,你的苦恼是不是就迎刃而解了呢 (#^.^#)
第一步:找寻爬取目标页面
在这里图片爬取我们具体爬取的是王者荣耀游戏图片,当然你也可以爬取表情包等各种图库。
和文字爬取一样,首先通过一段程序可以将其对应的 HTML 文件读取并存入本地
import requests
url = " 这里填写目标页面URL "
response = requests.get(url)
with open("picture.html",'a',encoding="utf-8") as f:
f.write(response.text)与前面一样,这里给出得到的 HTML 文件具体内容(部分)截图

第二步:找寻爬取目标资源
事实上,对于图片和文字的爬取思路、做法是一致的,按照爬取文字的思路即可完成爬取图片,这里直接上图
这里具体是将下图展示的这一页面中的图片全部下载并保存到指定文件夹下(F12+箭头指示操作)
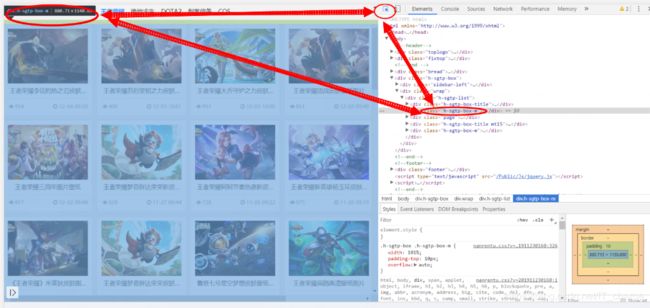
只要具体确定到指定图片在 HTML 文件中具体代码所指位置即可。
第三步:解析并存储目标资源数据
有了以上两步的操作,接下来也就水到渠成了
具体代码如下:
import requests
from pyquery import PyQuery as pq
import uuid
with open("jieguo.html",'w',encoding="utf-8") as f:
f.write(requests.get(" 目标页面的URL填写在这儿 ").text)
for i in pq(requests.get(" 目标页面的URL填写在这儿 ").text)('.h-piclist > li > a > img').items():
if requests.get(i.attr('src')).status_code == 200:
with open("F:/%s.jpg" % uuid.uuid1().hex, 'wb') as f:
f.write(requests.get(i.attr('src')).content)
f.close()爬取结果已全部存入指定文件夹,截图如下:
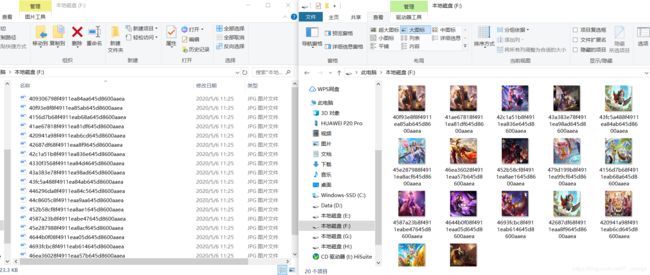 此时,你的成就感绝对是满满的(*^▽^*)
此时,你的成就感绝对是满满的(*^▽^*)
由于实例所示的图片不是很多,代码运行时间很短就能完成,但是如果要下载的图片很多,长时间等不到程序运行结束,而你想在代码运行时查看下载进度,这也很简单,直接在 ![]() 语句下加一条
语句下加一条 ![]() 语句将下载进度打印出来即可。
语句将下载进度打印出来即可。
具体下载进度查看截图: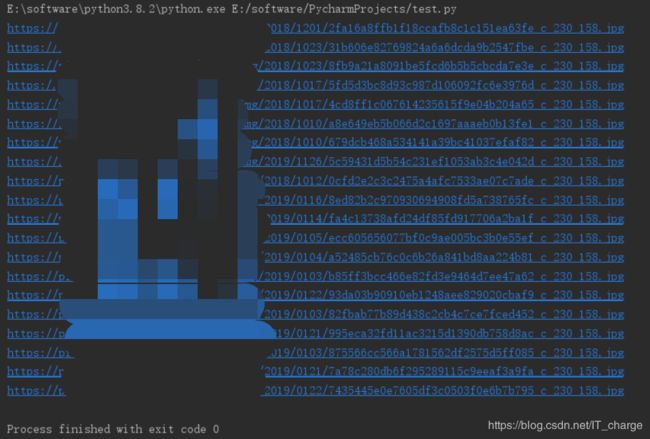
至此,图片爬取部分也已经讲解完毕,小伙伴们是不是也迫不及待想试一试呢?

❸数据爬取
在介绍完文字、图片爬取后,下面介绍另一种爬取方法,此方法适用于数据爬取。
数据爬取有别于上两种爬取方式,主要用到了 requests 工具包、time 库 以及 json 库。
找寻爬取目标页面及资源
在这里,我以 FireFox 浏览器为例详细介绍爬取数据方法。
在 FireFox 浏览器地址栏中输入目标网址并访问,打开目标页面。

在目标页面菜单栏中选择 web 开发者 -> 网络 。
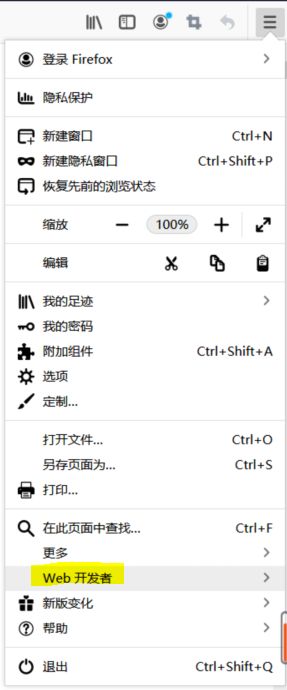

然后得到如下图所示的网络状态,点击刷新,点击刷新,点击刷新(不然什么都看不到)

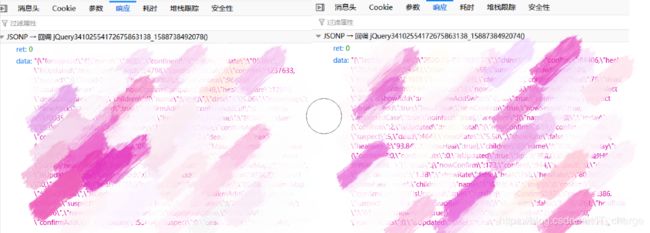
此时我们点击类型显示为 json 格式的一行,点击 响应 ;
通过下面显示的 data{ } 数据找寻我们感兴趣的东西。

在本实例中,我想要对两部分的数据做整合分析,于是乎,我把目标定在了这两个相应内容上:
解析并存储目标资源数据
找到了需要爬取的目标内容,我们就可以通过代码实现、分析咯
具体套用模板也是有必要做一讲解的:
以国外数据为例,通过 响应头 我们可以看到我们感兴趣的内容,通过 消息头 我们可知道对应目标的相关参数

在代码部分的 URL 中,将 请求网址 中的网址一直获取到 callback 复制粘贴后面加上 =&_=%d 即可。
代码部分的 for语句 中的目标获取比如国外数据这是下图中的 foreignList ,国内数据就是下图中的 areaTree 。
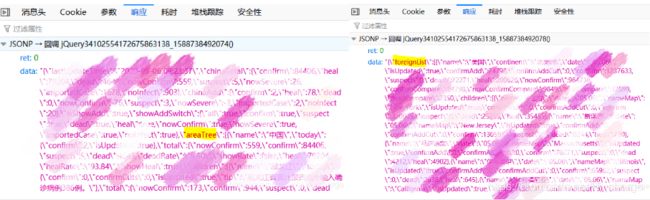
通过以上详细分析,我们就可以轻而易举地实现相关代码了。
其中一个数据
具体代码如下
import time, json, requests
url = ' 消息头代码直到callback结束 + =&_=%d' % int(time.time() * 1000)
print(json.loads(requests.get(url=url).json()['data']))
print(json.loads(requests.get(url=url).json()['data']).keys())
print(len(json.loads(requests.get(url=url).json()['data'])['foreignList'][0]['children']))
for item in json.loads(requests.get(url=url).json()['data'])['foreignList'][0]['children']:
print(item['name'], end=" ")
else:
print("\n")爬取结果截图

另一个数据
具体代码如下
import time, json, requests
url = ' 消息头代码直到callback结束 + =&_=%d' % int(time.time() * 1000)
data = json.loads(requests.get(url=url).json()['data'])
print(data)
print(data.keys())
yiqingArea = num = data['areaTree'][0]['children'][0]['children']
for item in yiqingArea:
print(item)
else:
print("\n")爬取结果截图

❹视频爬取
视频爬取原理与文字、图片爬取一样,思路做法一样,这里不再赘述,仅给出目标页面及目标资源等简短说明。
第一步:找寻爬取目标页面
首先我们确定爬取目标页面,我找的目标页面它具体长这个样子

第二步:找寻爬取目标资源
与文字、图片爬取不同的一点是,我们在HTML文件指定位置右键直接复制 css selector 选择器即可;
不用再逐步分析这一部分是包含在哪个div下面的,是不是方便很多了呢。
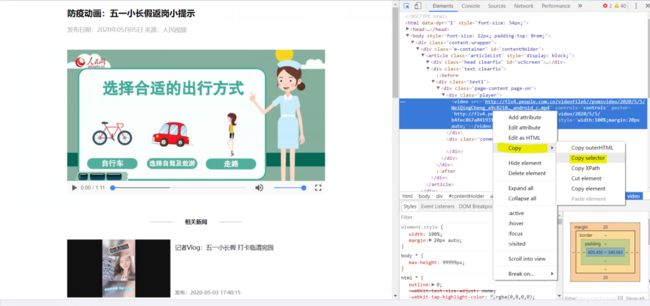
然后我们将复制好的选择器地址直接粘贴到代码中的 videoElement 中即可。
第三步:解析并存储目标资源数据
代码参考
import requests
from pyquery import PyQuery as pq
baseUrl = " 目标页面URL填写到这里 "
if requests.get(baseUrl).status_code == 200:
with open("renmingwang.html", 'w', encoding="utf-8") as f:
f.write(requests.get(baseUrl).text)
videoElement = pq(requests.get(baseUrl).text)('#contentHolder > article > div.text.clearfix > div > div > div.player > video')
fileName = "F:/shipin.mp4"
with open(fileName, 'wb') as f:
f.write(requests.get(videoElement.attr('src')).content)
f.close()爬取结果展示

❺音乐爬取
我们往往会遇到这样的情况:看到一段视频后,希望得到其音频部分而不要其视频部分。基于此,本部分将用仅仅十行代码展示成功将视频中的音频提取出来的效果。
在本实例中,我们将针对“千千音乐”中的某段视频做音频提取:
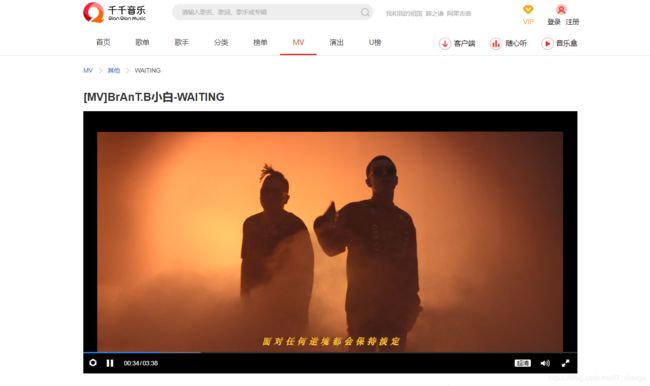
代码参考
import requests
url=' 目标页面URL '
headers={'referer':'http://music.baidu.com/mv',
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36',}
r=requests.session().get(url,headers=headers)
a=r.content.decode('UTF-8')
file_mp4=a.split('data.push')[1].split('file_link":"')[1].replace('"});','').replace(r"\\",r'').replace('\/','/').replace("\n",'').strip()
f=open('F:/music.mp3','wb')
f.write(requests.session().get(file_mp4).content)
f.close()运行结果展示
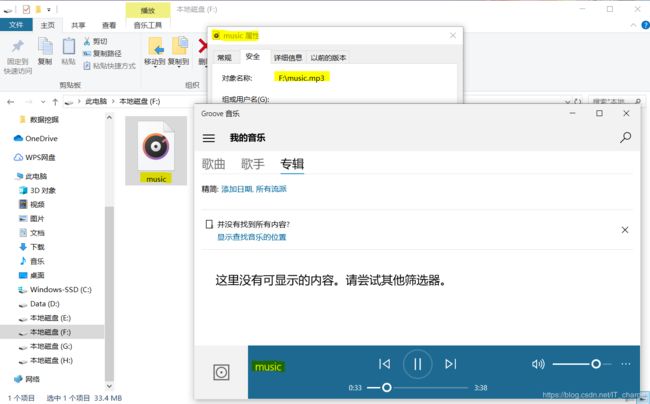
至此,文字、图片、数据、视频、音频等的爬取均用仅仅 10 行代码已经全部详细讲解完毕了 。
觉得还不错的话点个赞再走呗 (#^.^#)
Ⅳ 爬取心得
这一部分,就说一下我们遇到什么情况下就不能按照上述方法爬取咯
第一,在转 HTML 文件时本是汉字部分却出现乱码
这里列举一个比如“爱奇艺”网站,大家可以看到,解析出的 HTML 文件就会出现许多乱码,就不可以进行下一步操作了。
注:解析为 HTML 文件代码在第 I 部分有提到,可自行查阅

第二,有防爬系统的网站
事实上,爬取中我们会发现,许多网站是有防爬系统的,尤其是音乐等付费网站,因此但凡有防爬系统的网站是不允许我们只简单用10行代码爬取的,所以遇到这种情况就另寻他法叭。
从网上找了几个示例,这里简单说一下:
①猫眼电影
猫眼电影里,对于票房数据,展示的并不是纯粹的数字。
页面使用了font-face定义了字符集,并通过unicode去映射展示。
也就是说,除去图像识别,必须同时爬取字符集,才能识别出数字。
并且,每次刷新页面,字符集的url都是有变化的,无疑更大难度地增加了爬取成本。
②美团
与font的策略类似,美团里用到的是background拼凑。
数字其实是图片,根据不同的background偏移,显示出不同的字符。
③汽车之家
汽车之家里,把关键的厂商信息,做到了伪元素的content里。
想要爬取网页,必须得解析css,需要拿到伪元素的content,这就提升了爬虫的难度。
在写“音乐爬取”部分时,超级多的音乐网站都防爬,不过最后我还是找到了一种方法解决了这个问题,允许我自恋一波~

以上所有内容实质上是最简单、最基础的。后续我还会写一些相关文章。
正如文章开篇所述,我对于爬虫的认知起源于寻找“数据集”;
从这个层面上说,本文将是大量数据预测文章的开篇之作,大家多多关注我叭~~~
Ⅴ 文章声明
版权声明:本文为CSDN博主「IT_change」的原创文章,遵循CC 4.0 BY-SA版权协议。
转载请附上原文出处链接及本声明。
感谢阅读 ! 感谢支持 ! 感谢关注 !
希望本文能对读者学习和使用爬虫技术有所帮助,并请读者批评指正!
2020年5月于山西大同