「Python爬虫系列讲解」十三、用 Scrapy 技术爬取网络数据
本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
「Python爬虫系列讲解」四、BeautifulSoup 技术
「Python爬虫系列讲解」五、用 BeautifulSoup 爬取电影信息
「Python爬虫系列讲解」六、Python 数据库知识
「Python爬虫系列讲解」七、基于数据库存储的 BeautifulSoup 招聘爬取
「Python爬虫系列讲解」八、Selenium 技术
「Python爬虫系列讲解」九、用 Selenium 爬取在线百科知识
「Python爬虫系列讲解」十、基于数据库存储的 Selenium 博客爬虫
「Python爬虫系列讲解」十一、基于登录分析的 Selenium 微博爬虫
「Python爬虫系列讲解」十二、基于图片爬取的 Selenium 爬虫
目录
1 安装 Scrapy
2 快速了解 Scrapy
2.1 Scrapy 基础知识
2.2 Scrapy 组成详解及简单示例
2.2.1 新建项目
2.2.2 定义 Item
2.2.3 提取数据
2.2.4 保存数据
3 用 Scrapy 爬取农产品数据集
3.1 创建工程
3.2 设置 items.py 文件
3.3 浏览器审查元素
3.4 创建爬虫并执行
3.5 实现翻页爬取及多页爬取功能
3.6 设置 pipelines.py 文件保存数据至本地
3.7 设置 settings.py 文件
4 本文小结
如果您从爬虫系列讲解一直看到这里时,相信已经初步了解了 Python 爬取网络数据的知识,甚至能利用正则表达式、BeautifulSoup 或 Selenium 技术爬取所需的语料,但这些技术也存在一些问题,比如爬取效率较低。
本文将介绍 Scrapy 技术,其爬取效率较高,是一个爬取网络数据、提取结构性数据的应用框架,将从安装、基本用法和爬虫实例 3 个方面对其进行详细介绍。
1 安装 Scrapy
本爬虫专栏系列主要针对的是 Windows 环境下的 Python 编程,所以安装的 Scrapy 扩展库也是基于 Windows 环境下的。在 Python 的 Scripts 文件夹下输入 Python 的 pip 命令进行安装。
值得注意的是,因为scrapy框架基于Twisted,所以先要下载其whl包安装。
Twisted 下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/

搜索 twisted,根据自己的版本下载进行安装,之后在 cmd 中输入类似如下 pip 命令
pip install *****.whl
注:***.whl 是下载到本地的路径地址(可在属性→安全中查看)
之后安装 Scrapy,scrapy的whl包地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/

pip install *****.whl
注:***.whl 是下载到本地的路径地址(可在属性→安全中查看)
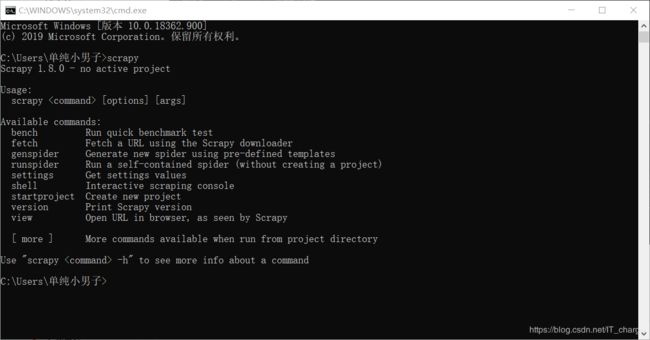
安装成功之后,通过 cmd 输入 “scrapy” 查看其所包含的指令,如下图所示。
2 快速了解 Scrapy
Scrapy 官网地址为:https://scrapy.org/,官方介绍为“An open source and collaborative framework for extracting the data you need from websites.In a fast, simple, yet extensible way.”。
Scrapy 是一个为了快速爬取网站数据、提取结构性数据而编写的应用框架,其最初是为了页面爬取或网络爬取设计的,也可用于获取 API 所返回的数据,如 Amazon Associates Web Services 或者通用的网络爬虫,现在被广泛应用于数据挖掘、信息爬取或 Python 爬虫等领域。
2.1 Scrapy 基础知识
下图所示的是 Scrapy 官网首页,推荐大家从官网学习该工具的用法并实行先相关爬虫案例,这里结合作者的相关经验和官网知识对 Scrapy 进行讲解。
 Scrapy 爬虫框架如下图所示,它使用 Twisted 异步网络库来处理网络通信,包含各种中间接口,可以灵活地完成各种需求,只需要定义几个模块,皆可以轻松地爬取所需要的数据集。
Scrapy 爬虫框架如下图所示,它使用 Twisted 异步网络库来处理网络通信,包含各种中间接口,可以灵活地完成各种需求,只需要定义几个模块,皆可以轻松地爬取所需要的数据集。

上图这种的基本组件介绍如下表所示:
| 组件 | 介绍 |
| Scrapy Engine | Scrapy 框架引擎,负责控制数据流在系统所有组件中的流动,并在相应动作发生时触发该事件 |
| Scheduler | 调度器,从引擎接受请求(Request)并将它们入队,以便之后引擎请求他们时提供给引擎 |
| Downloader | 下载器,负责提取页面数据并提供给引擎,而后提供给爬虫 |
| Spiders | 爬虫,它是 Scrapy 用户编写用于分析响应(Response)并提取项目或额外跟进 URL 的类。每个爬虫负责处理一个特定网站或一些网站 |
| Item Pipeline | 项目管道,负责处理被爬虫提取出来的项目。典型的处理包括清理、验证及存到数据库中 |
| Downloader Middlewares | 下载器中间件,它是 Scrapy 引擎和下载器之间的特定钩子,处理下载器传递给引擎的响应(也包括 Scrapy 引擎传递给下载器的请求),它提供了一个简便的机制,通过插入自定义代码来扩展 Scrapy 功能 |
| Spider Middlewares | 爬虫中间件,它是 Scrapy 引擎及 Spiders 之间的特定钩子,处理 Spiders 的输入响应与输出项目和要求 |
| Scheduler Middlewares | 调度器中间件,它是在 Scrapy 引擎和调度器之间的特定钩子,处理调度器引擎发送来的请求,以便提供给 Scrapy 引擎 |
- Scrapy 框架中的数据流(Data Flow)由执行引擎控制,根据上图中的虚线箭头表示的数据流向,Scrapy 框架的爬取步骤如下:
- Scrapy 引擎打开一个网站,并向该爬虫请求第一个要爬取的 URL(s);
- Scrapy 引擎从爬虫中获取到第一个要爬取的 URL 给引擎,引擎将 URL 通过下载器中间件以请求的方式转发给下载器;
- Scrapy 引擎向调度器请求下一个要爬取的 URL;
- 调度器返回下一个要爬取的 URL 引擎,引擎将 URL 通过下载器中间件以请求的方式转发给下载器;
- 下载器开展下载工作,当页面下载完毕时,下载器将生成该页面的一个响应,并通过下载器中间件返回响应并发送给引擎;
- Scrapy 引擎从下载器中接收到响应并通过爬虫中间件发送给爬虫处理;
- 爬虫处理响应并返回爬取到的项目内容及新的请求给引擎;
- 引擎将爬虫返回爬取到的项目发送到项目管道处,它将对数据进行后期处理(包括详细分析、过滤、存储等),并将爬虫返回的请求发送给调度器。
- 重复 2~9,直到调度器中没有更多的请求,Scrapy 引擎关闭该网站。
接下来通过简单示例体会下 Scrapy 爬虫工作原理及具体的使用方法。
2.2 Scrapy 组成详解及简单示例
编写一个 Scrapy 爬虫主要完成以下 4 个任务:
- 创建一个 Scrapy 项目;
- 定义提取的 Item,这时需爬取的栏目;
- 编写爬取网站的爬虫并提取 Item;
- 编写 Item Piprline 来存储提取的 Item 数据。
下面通过一个实例来讲解 Scrapy 的组成结构及调用过程,与上述任务对应地划分为 4 个部分。
2.2.1 新建项目
首先需要在一个自定义目录下新建一个工程,比如创建 test_scrapy 工程。注意,这里需要调用 cmd 命令行去创建工程,在 cmd 中输入如下指令:
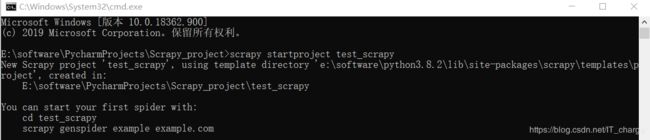
scrapy startproject test_scrapy该工程创建在作者常存的 Python 文件目录下,如下图所示,同时提示可以调用 “cd test_scrapy” 命令去该目录,调用 “scrapy genspider example example.com” 命令开始第一个爬虫。
该命令创建的 test_scrapy 工程所包含的目录如下,最外层是一个 test_scrapy 目录和一个 scrapy.cfg 文件,test_scrapy 文件夹中包含主要的爬虫文件,如 items.py、middlewares.py、pipelines.py、settings.py 等。

这些文件具体含义图下表所列,后续内容将对各文件进行详细介绍。
| 文 件 | 含 义 |
| scrapy.cfg | 项目的配置文件 |
| test_scrapy / items.py | 项目中的 item 文件,定义栏目 |
| test_scrapy / pipelines.py | 项目中的 piplines 文件,存储数据 |
| test_scrapy / settings.py | 项目的设置文件 |
| test_scrapy / spiders/ | 放置 spiders 代码的目录 |
下面将以 Scrapy 爬取作者的博客网站为入门示例。
2.2.2 定义 Item
Item 是保存爬取到数据的容器,其使用方法和 Python 字典类似,并且提供了相应的保护机制来避免拼写错误导致的未定义字段错误。
这里先创建一个 scrapy.item 类,并定义 scrapy.Field 类属性,然后利用该 scrapy.Field 类属性定义一个 Item 中定义相应的字段。例如,items.py 文件中的代码就定义了标题、超链接和摘要 3 个字段,如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class TestScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 标题
url = scrapy.Field() # 超链接
dedscription = scrapy.Field() # 摘要
通过该文件定义的 Item,读者可以很方便地使用 Scrapy 爬虫所提供的各种方法来爬取这 3 个字段的数据,即对应自己所定义的 Item。
2.2.3 提取数据
接下来需要编写爬虫程序,用于爬取网站数据的类。该类包含一个用于下载的初始 URL,能够跟进网页中的超链接并分析网页内容,提取生成 Item。scrapy.spider 类包含 3 个常用属性,如下:
- name:名称字段用于区别爬虫。需要注意的是,改名字必须是唯一的,不可以为不同的爬虫设定相同的名字。
- start_urls:该字段包含爬虫在启动时进行的 URL 列表。
- parse():爬虫的一个方法,被调用时,每个初始 URL 完成下载后生成的 Response 对象都将会作为唯一的参数传递给该方法。该方法负责解析返回的数据,提取数据以及生成需要进一步处理的 URL 的Request 对象。
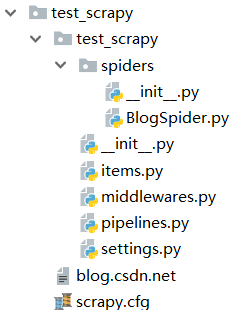
接着在 test_scrapy/spiders 目录下创建一个 BlogSpider.py 文件,此时工程目录如下图所示:
增加代码如下,注意类名和文件名一致,均为“BlogSpider”。
BlogSpiders.py
import scrapy
class BlogSpider(scrapy.Spider):
name = "IT_charge"
allowed_domains = ["https://blog.csdn.net/IT_charge"]
start_urls = [
"https://blog.csdn.net/IT_charge"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)接下来在 cmd 命令行执行下列命令启动爬虫:
cd test_scrapy
scrapy crawl IT_charge“scrapy crawl IT_charge” 启动爬虫,爬取博客网站,运行结果如下图所示:

此时,Scrapy 为爬虫的 start_urls 属性中的每个 URL 都创建了 scrapy.Request 对象,并将 parse() 方法作为回调函数赋值给了 Request 对象;另外,Request 对象经过调度,执行生成 scrapy.http.Response 对象返回给 spider parse() 方法。
Scrapy 提取 Item 时使用了一种基于 XPath 或 Selenium 技术分析方法,比如:
- /html/head/title:定位选择 HTML 文档中 标签下的
元素;</li> <li> <strong>/html/head/title/text()</strong>:定位 <title> 元素并获取该标题元素中的文字内容;</li> <li><strong>//td</strong>:选择所有的 <td> 元素;</li> <li><strong>//div[@class="price"]</strong>:选择所有 “class="price"” 属性的 div 元素。</li> </ul> <p>下表列出了 Selector 常用的 4 个方法:</p> <table border="1" style="width:600px;"> <caption> Selector 常用的方法 </caption> <tbody> <tr> <td>方法</td> <td>含义</td> </tr> <tr> <td>xpath()</td> <td>利用 XPath 技术进行分析,传入 XPath 表达式,返回对应节点的 list 列表</td> </tr> <tr> <td>css()</td> <td>传入 CSS 表达式,返回该表达式所对应的所有节点的 Selector list 列表</td> </tr> <tr> <td>extract()</td> <td>序列化该节点为 unicode 字符串并返回 list 列表</td> </tr> <tr> <td>re()</td> <td>根据传入的正则表达式对数据进行提取,返回 unicode 字符串的 list 列表</td> </tr> </tbody> </table> <p>假设现在需要爬取博客网站的标题内容,则修改 test_scrapy<strong>\</strong>spiders 目录下的 BlogSpider.py 文件,代码如下:</p> <p><strong>BlogSpiders.py</strong> </p> <pre><code class="language-python">import scrapy class BlogSpider(scrapy.Spider): name = "IT_charge" allowed_domains = ["https://blog.csdn.net/IT_charge"] start_urls = [ "https://blog.csdn.net/IT_charge" ] def parse(self, response): for t in response.xpath('//title'): title = t.extract() print(title) for t in response.xpath('//title/text()'): title = t.extract() print(title)</code></pre> <p>输入 “scrapy crawl IT_charge” 命令,将爬取网站的标题代码:“<title>荣仔的博客_荣仔!最靓的仔!_CSDN博客-在王者荣耀角度下分析面向对象程序设计B中23种设计模式,java,Python领域博主 ”,如果需要获取标题内容,则使用 text() 函数来获取 “荣仔的博客_荣仔!最靓的仔!_CSDN博客-在王者荣耀角度下分析面向对象程序设计B中23种设计模式,java,Python领域博主”。
接下来需要获取标题、超链接和摘要,通过浏览器分析源码,如下图所示。

可以看到文章位于
...标签之间,其 class 属性为 “article-item-box csdn-tracking-statistics”,分别定位节点下的 “h4” 标签可以获取标题,标签可以获取摘要。
对应爬取标题、超链接、摘要内容的 BlogSpider.py 文件修改如下:
BlogSpiders.py
import scrapy class BlogSpider(scrapy.Spider): name = "IT_charge" allowed_domains = ["https://blog.csdn.net/IT_charge"] start_urls = [ "https://blog.csdn.net/IT_charge" ] def parse(self, response): for sel in response.xpath('//*[@id="mainBox"]/main/div[2]/div[1]'): title = sel.xpath('h4/a/text()').extract()[0] url = sel.xpath('h4/a/@href').extract()[0] description = sel.xpath('p/a/text()').extract()[0] print(title) print(url) print(description)同样,在 cmd 命令行下输入 “输入 “scrapy crawl IT_charge” 命令”,运行结果如下图所示:

2.2.4 保存数据
保存数据需要利用 pipeline.py 文件,它主要对爬虫返回的 Item 列表进行保存以及写入文件或数据库操作,通过 process_item() 函数来实现。
首先,修改 BlogSpiders.py 文件,通过 Test13Item() 类产生一个 item 类型,用于存储标题、超链接和摘要,代码如下:
BlogSpiders.py
import scrapy from Scrapy_project.test_scrapy.test_scrapy.items import * class BlogSpider(scrapy.Spider): name = "IT_charge" allowed_domains = ["https://blog.csdn.net/IT_charge"] start_urls = [ "https://blog.csdn.net/IT_charge" ] def parse(self, response): for sel in response.xpath('//*[@id="mainBox"]/main/div[2]/div[1]'): item = TestScrapyItem() item['title'] = sel.xpath('h4/a/text()').extract()[0] item['url'] = sel.xpath('h4/a/@href').extract()[0] item['description'] = sel.xpath('p/a/text()').extract()[0] return item接下来,修改 pipelines.py 文件,具体修改内容代码如下所示:
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import json import codecs class TestScrapyPipeline(object): def __init__(self): self.file = codecs.open('F:/blog.json', 'w', encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item), ensure_ascii=False) + "\n" self.file.write(line) return item def spider_closed(self, spider): self.file.close()接着为了注册启动 Pipeline,需要找到 settings.py 文件,然后将要注册的类加入 “ITEM_PIPELINES” 的配置中,在 settings.py 中加入下述代码,其中,“Scrapy_project.test_scrapy.pipelines.TestScrapyPipeline” 是用户要注册的类,右侧的 “1” 表示 Pipeline 的优先级,其中,优先级的范围为 1~1000,越小优先级越高。
settings.py
# Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'Scrapy_project.test_scrapy.pipelines.TestScrapyPipeline': 1 }同样,cmd 输入 “scrapy crawl IT_charge” 命令执行即可。
若出现中文乱码或显示的是 Unicode 编码,则修改 BlogSpider.py 或 pipelines.py 文件转换 unicode 编码即可。
下面给出一个项目实例,讲解如何使用 Scrapy 框架迅速爬取网站数据。
3 用 Scrapy 爬取农产品数据集
再做数据分析时,通常会遇到预测商品价格的情况,而在预测价格之前就需要爬取海量的商品价格信息,比如淘宝、京东商品等,这里采用 Scrapy 技术爬取贵州农产品数据集。
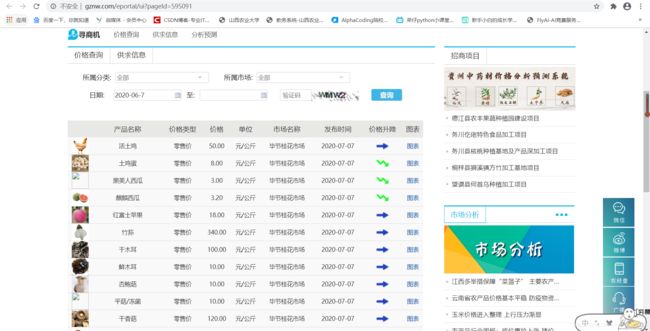
输入 “http://www.gznw.com/eportal/ui?pageId=595091” 网址,打开贵州农经网,可以查看贵州各个地区农产品每天价格的波动情况,如下图所示,主要包括 6 个字段:品种名称、价格类型、价格、单位、市场名称和发布时间。
Scrapy 框架自定义爬虫的主要步骤如下:
- 在 cmd 命令行模型下创建爬虫工程,即创建 SZProject 工程爬取贵州农经网。
- 在 items.py 文件中定义要抓取的数据栏目,对应品种名称、价格类型、价格、单位、市场名称和发布时间 6 个字段。
- 通过浏览器审查元素功能分析所需爬取内容的 DOM 结构并进行定位 HTML 节点。
- 创建爬虫文件,定位并爬取所需内容。
- 分析网页翻页方法,并发送多页面跳转爬取请求,不断执行爬虫直到结束。
- 设置 pipelines.py 文件,将爬取的数据集存储至本地 JSON 文件或 CSV 文件中。
- 设置 settings.py 文件,设置爬虫的执行优先级。
下面是完整的实现过程,重点是如何实现翻页爬取及多页面爬取。
3.1 创建工程
在 Windows 环境下,按 Ctrl + R 快捷键打开运行对话框,然后输入 cmd 命令打开命令行模式,接着调用 “cd” 命令到某个目录下,再调用 “scrapy startproject GZProject” 命令创建爬取贵州农经网产品信息的爬虫工程。

创建 Scrapy 爬虫的命令如下:
scrapy startproject GZProject
3.2 设置 items.py 文件
接着在 items.py 文件中定义需要爬去的字段,这里主要是 6 字段。调用 scrapy.Item 子类的 Field() 函数创建字段,代码如下:
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class GzprojectItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() num1 = scrapy.Field() # 品种名称 num2 = scrapy.Field() # 价格类型 num3 = scrapy.Field() # 价格 num4 = scrapy.Field() # 单位 num5 = scrapy.Field() # 市场名称 num6 = scrapy.Field() # 发布时间接下来就是核心内容,分析网页 DOM 结构并编写对应爬虫代码。
3.3 浏览器审查元素
打开浏览器,键盘按下 F12 键,用 “元素选择器” 定位具体目标查看其对应的 HTML 源码,如下图所示:

观察发现,每行数据都位于
节点下;接着调用 scrapy 框架的 XPath、css 等功能进行爬取。 3.4 创建爬虫并执行
在 Spider 文件夹下创建一个 Python 文件——GZSpider.py 文件,主要用于实现爬虫代码。具体代码如下所示:
import scrapy from scrapy import Request from scrapy.selector import Selector # from GZProject.items import * class GZSpider(scrapy.Spider): name = "gznw" # 贵州农产品爬虫 allowed_domains = ["gznw.gov.vn"] start_urls = [ "http://www.gznw.com/eportal/ui?pageId=595091" ] def parse(self, response): print('----------------------Start-----------------------') print(response.url) for t in response.xpath('//title'): title = t.extract() print(title)接下来执行下列命令启动爬虫:
cd GZProject scrapy crawl gznw
接下来爬取商品信息,编写完整代码如下:
import scrapy import os import time from selenium import webdriver from scrapy import Request from scrapy.selector import Selector from GZProject.items import * class GZSpider(scrapy.Spider): name = "gznw" # 贵州农产品爬虫 # allowed_domains = ["http://www.gznw.com/eportal/ui?pageId=595091"] start_urls = [ "http://www.gznw.com/eportal/ui?pageId=595091" ] def parse(self, response): print('----------------------Start-----------------------') print(response.url) # 打开 Chrome 浏览器,这顶等待加载时间 chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe' os.environ["webdriver.chrome.driver"] = chromedriver driver = webdriver.Chrome(chromedriver) # 模拟登录 163 邮箱 url = 'http://www.gznw.com/eportal/ui?pageId=595091' driver.get(url) time.sleep(5) # 用户名、密码 for i in driver.find_elements_by_xpath( '//*[@id="5c96d136291949729295e25ea7e708b7"]/div[2]/div[2]/table/tbody/tr'): print(i.text)
3.5 实现翻页爬取及多页爬取功能
这里列出 3 中翻页方法,具体细节请读者自行研究:
方法一:定义 URL 超链接列表分别爬取
start_urls = [ "地址 1" "地址 2" "地址 3" ]方法二:拼接不同的网页的 URL 并发送请求爬取
next_url = "前半段URL地址" + str(i)方法三:获取下一页超链接并请求爬取其内容
i = 0 next_url = response.xpath('//a[@class="page=link next"]/@href').extract() if next_(url is not None) and i < 20: i = i + 1 next_url = '前半段网址' + next_url[0] yield.Request(next_url, callback=self.parse)3.6 设置 pipelines.py 文件保存数据至本地
import codecs import json class GzprojectPipline(object): def __init__(self): self.file = codecs.open('guizhou.json', 'w', encoding='utf-8') def process_item(self, item, spider): line = json.dumps(dict(item), ensure_ascii=False) + "\n" self.file.write(line) return item def spider_closed(self, spider): self.file.close()3.7 设置 settings.py 文件
ITEM_PIPELINES = { 'GZProject.piplines.GzprojectPipeline':1 }至此,一个完整的 Scrapy 爬虫实例思路已经讲解完了,希望本文对您有所帮助,也相信大家都有所收获。
4 本文小结
我们可以基于 BeautifulSoup 或 Selenium 技术的网络爬虫获取各种网站的信息,但其爬取效率太低,而 Scrapy 技术就很好地解决了这个难题。Scrapy 是一个爬取网络数据、提取结构性数据的高效率应用框架,其底层是异步框架 Twisted。Scrapy 最受欢迎的地方是他的性能,良好的并发性,较高的吞吐量提升了其爬取和解析的速度,而且下载器也是多线程的。同时,Scrapy 还拥有良好的存储功能,可以设置规则爬取具有一定规律的网址,尤其是在需要爬取大量真实的数据时,Scrapy 更是一个令人信服的好框架。
欢迎留言,一起学习交流~
感谢阅读
END
你可能感兴趣的:(「Python爬虫系列讲解」十三、用 Scrapy 技术爬取网络数据)