iOS底层探索三(内存对齐与calloc分析)
前言
相关文章:
iOS底层探索一(底层探索方法)
iOS底层探索二(OC 中 alloc 方法 初探)
iOS底层探索四(isa初探-联合体,位域,内存优化)
iOS底层探索五(isa与类的关系)
iOS底层探索六(类的分析上)
iOS底层探索七(类的分析下)
iOS底层探索八(方法本质上)
iOS底层探索九(方法的本质下objc_msgSend慢速及方法转发初探)
iOS底层探索十(方法的本质下-消息转发流程)
相关代码:
libmalloc源码 objc4_752源码 编译器优化(这份代码只是配合文章使用)
前两篇文章对alloc方法进行了初步探究但是到calloc方法发现,这个方法在另一个库中,这边文章描述下内存对齐,并对calloc进行继续探究
内存对齐原则进行说明
首先我们需要知道为什么系统要进行内存对齐,CPU每次从内存中取出数据或者指令时,并非想象中的一个一个字节取出拼接的,而是根据自己的字长,也就是CPU一次能够处理的数据长度取出内存块,也就是说如果不尽兴内存对齐的话,我们存数据可能长度为2,3,5,6,8,3,这种长度存储的话,CPU每次获取都需要进行识别数据长度,这样来看,效率一定会变低,如果CPU每次都读取相同长度,那就不用不用考虑数据长度这个因素,这样肯定会读取速度会提升,这里就是使用空间来换取时间(以下内容为百度内容):
内存对齐原则:
-
1、数据成员对⻬规则:结构体(struct)(或联合体(union))的数据成员,第一个数据成员放在offset为0的地方,以后每个数据成员存储的起始位置要从该成员大小或者成员的子成员大小(只要该成员有子成员,比如说是数组,结构体等)的整数倍开始(比如int为4字节,则要从4的整数倍地址开始存储。
-
2、结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储.(struct a里存有struct b,b里有char,int,double等元素,那b应该从8的整数倍开始存储.)
-
3、收尾工作:结构体的总大小,也就是sizeof的结果,.必须是其内部最大成员的整数倍.不足的要补⻬。
内存对齐原则注意点
-
1、对象的属性需要的内存空间是8位倍数,如果不以8的倍数,CPU读起来很a耗性能高,所以以8字节为倍数,提高读取效率,以空间换时间
-
2、开辟的对象的空间如果小于16字节的分配16个字节,防止越界
这里我们用比较经典面试题进行分析下,如下
struct XZStruct1 {
char a;
double b;
int c;
short d;
} MyStruct1;
struct XZStruct2 {
double b;
char a;
short d;
int c;
} MyStruct2;
int main(int argc, const char * argv[]) {
@autoreleasepool {
NSLog(@"\nMyStruct1 ==%lu\nMyStruct2==%lu",sizeof(MyStruct1),sizeof(MyStruct2));
}
return 0;
}
首先我们来看下打印结果:

两个相同的结构体,因为内部包含属性的排列顺序不同,而导致需要开辟的空间不同;下图是我分析的内存对齐后排列
我们看到打印结果为

从这里我们可以看出,当我们声明结构体的时候属性排列也是需要仔细看看的,因为会影响内存情况
iOS开发中的内存排布
作为iOS开发我们关心的是我们自己声明一个Model,它在内存中会怎样进行排布,其实我们声明的model在底层也是结构体方式存储的!(这个后续会详细描述)
这里我们创建一个模型,内部包含以下属性
#import
NS_ASSUME_NONNULL_BEGIN
@interface XZTearcher : NSObject
/**
* name
*/
@property (copy, nonatomic) NSString *name;
/**
* age
*/
@property (assign,nonatomic) int age;
/**
height
*/
@property (assign,nonatomic) long height;
/**
* course
*/
@property (copy, nonatomic) NSString *course;
/**
sex
*/
@property (assign, nonatomic) int sex;
@property (nonatomic) char ch1;
@property (nonatomic) char ch2;
@end
我们在main函数,创建对象并给属性进行赋值这里我们在LLDB调试使用:
x t //以16进制打印内存指针
x/4xg t 每4位进行读取4段
x/5xg t 每4位进行读取5段
因为iOS为小端模式地址需要倒着读
第一端为isa地址:0x001d8001000026e9
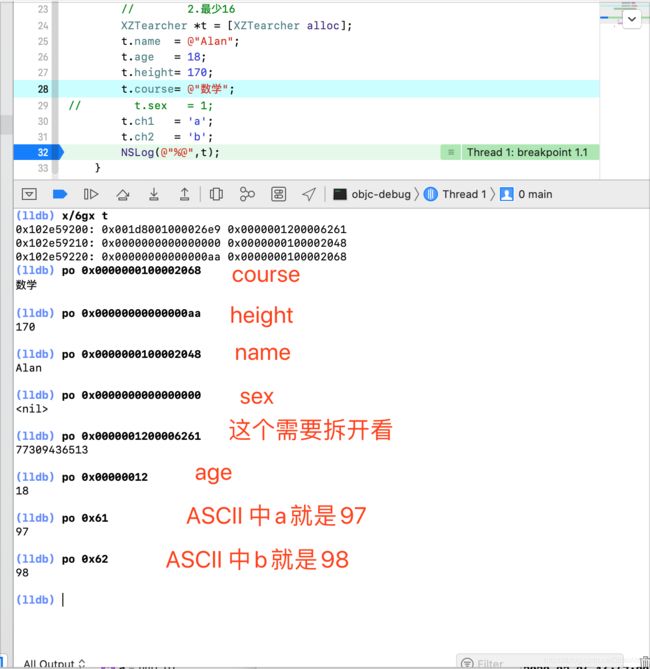
从0x0000001200006261这个地址我们可以看出,系统对我们自己声明的模型有进行优化排序,这个具体是在哪里进行优化排序属性的后续我们在进行详细说明这里稍微提一下,系统是在DYLD过程中进行操作的;
我们可以通过两种方式对内存开辟大小进行观察:
这里我们将XZTearch类中sex,ch1,ch2,先去掉,然后通过class_getInstanceSize,malloc_size这两个方法来观察一下系统开辟类需要多大内存,和系统开辟了多大内存,这个也经常会出现一个面试题;
@interface XZTearcher : NSObject
/**
* name
*/
@property (copy, nonatomic) NSString *name;
/**
* age
*/
@property (assign,nonatomic) int age;
/**
height
*/
@property (assign,nonatomic) long height;
/**
* course
*/
@property (copy, nonatomic) NSString *course;
/**
sex
*/
//@property (assign, nonatomic) int sex;
//@property (nonatomic) char ch1;
//@property (nonatomic) char ch2;
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
XZTearcher *t = [XZTearcher alloc];
// isa ---默认加载的 //8
t.name = @"Alan"; // 8
t.age = 18; //4 +4 内存对齐
t.height= 170; //8
t.course= @"数学"; //8
// 这里进行内存对齐后应该是40
NSLog(@"%@",t);
/***
8字节对齐
*/
NSLog(@"%lu ----%lu",class_getInstanceSize([t class]),malloc_size(t));
}
return 0;
}
我们看到打印结果为:
![]()
按照8字节对齐应该是40,40才对啊,这里我们就需要对源码进行分析
我们先看class_getInstanceSize方法源码
size_t class_getInstanceSize(Class cls)
{
if (!cls) return 0;
return cls->alignedInstanceSize();
}
uint32_t alignedInstanceSize() {
//字节对齐
return word_align(unalignedInstanceSize());
}
# define WORD_MASK 7UL
static inline uint32_t word_align(uint32_t x) {
//WORD_MASK 7
//7+8 = 15
//0000 0111 2进制表示7
//0000 1111 2进制表示15
//1111 1000 2进制表示~7
//0000 1000 15 & ~7 值 16
//这里主要就是做8进制对齐,这里相当于8倍数
//x + 7
//x=1 8
//x=2 16
//(x + 7) >> 3 << 3 这个也相当于8字节对齐
return (x + WORD_MASK) & ~WORD_MASK;
}经过源码分析,确实是8字节对齐,输出40,没有问题!
上篇文章(iOS底层探索二(OC 中 alloc 方法 初探))中主要描述了alloc方法底层走向问题,其中我们看到calloc方法
if (fastpath(cls->canAllocFast())) {
// No ctors, raw isa, etc. Go straight to the metal.
bool dtor = cls->hasCxxDtor();
//底层进行开辟控件
/*
其中calloc函数意思是开辟一个内存空间,cls->bits.fastInstanceSize()意思是开辟一个cls类的内存空间的大小,前面__count意思是倍数,其中cls->bits.fastInstanceSize()大小是遵循内存对齐原则开辟内存的
*/
id obj = (id)calloc(1, cls->bits.fastInstanceSize());
if (slowpath(!obj)) return callBadAllocHandler(cls);
//对象与内存进行关联
obj->initInstanceIsa(cls, dtor);
return obj;
}
这个的源码在malloc库中
void *calloc(size_t __count, size_t __size) __result_use_check __alloc_size(1,2);我们可以看到calloc是在malloc库中(malloc库源码)void *calloc(size_t __count, size_t __size) __result_use_check __alloc_size(1,2);
要运行这个库的时候注意这两处设置
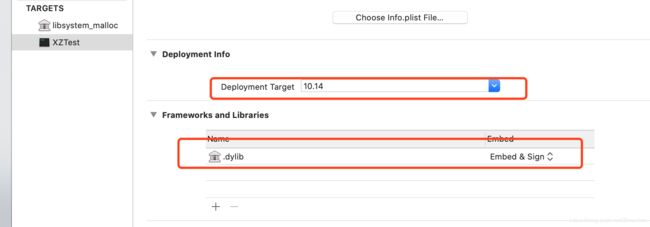
我们直接使用objc中的calloc调用方式传值就可以了
#import
int main(int argc, const char * argv[]) {
@autoreleasepool {
void *p = calloc(1, 40);
NSLog(@"%lu",malloc_size(p));
}
return 0;
}
void *
calloc(size_t num_items, size_t size)
{
void *retval;
retval = malloc_zone_calloc(default_zone, num_items, size);
if (retval == NULL) {
errno = ENOMEM;
}
return retval;
}
这个主要方法就是malloc_zone_calloc
void *
malloc_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size)
{
MALLOC_TRACE(TRACE_calloc | DBG_FUNC_START, (uintptr_t)zone, num_items, size, 0);
void *ptr;
if (malloc_check_start && (malloc_check_counter++ >= malloc_check_start)) {
internal_check();
}
//这里是zone中的属性函数
ptr = zone->calloc(zone, num_items, size);
if (malloc_logger) {
malloc_logger(MALLOC_LOG_TYPE_ALLOCATE | MALLOC_LOG_TYPE_HAS_ZONE | MALLOC_LOG_TYPE_CLEARED, (uintptr_t)zone,
(uintptr_t)(num_items * size), 0, (uintptr_t)ptr, 0);
}
MALLOC_TRACE(TRACE_calloc | DBG_FUNC_END, (uintptr_t)zone, num_items, size, (uintptr_t)ptr);
return ptr;
}这里我们能看到calloc肯定是主要方法,但是肯定不会是这里的calloc不然会造成递归,所以我们需要使用LLDB进行
打印zone->calloc
![]()
根据打印结果我们可以看出是dylib库中的default_zone_calloc 方法,找到这个函数,
static void *
default_zone_calloc(malloc_zone_t *zone, size_t num_items, size_t size)
{
zone = runtime_default_zone();
// .dylib`nano_calloc
return zone->calloc(zone, num_items, size);
}
使用同样的方法,我们可以看出下一个方法是nano_calloc;
static void *
nano_calloc(nanozone_t *nanozone, size_t num_items, size_t size)
{
size_t total_bytes;
if (calloc_get_size(num_items, size, 0, &total_bytes)) {
return NULL;
}
if (total_bytes <= NANO_MAX_SIZE) {
void *p = _nano_malloc_check_clear(nanozone, total_bytes, 1);
if (p) {
return p;
} else {
/* FALLTHROUGH to helper zone */
}
}
malloc_zone_t *zone = (malloc_zone_t *)(nanozone->helper_zone);
return zone->calloc(zone, 1, total_bytes);
}这里进入_nano_malloc_check_clear方法
static void *
_nano_malloc_check_clear(nanozone_t *nanozone, size_t size, boolean_t cleared_requested)
{
MALLOC_TRACE(TRACE_nano_malloc, (uintptr_t)nanozone, size, cleared_requested, 0);
void *ptr;
size_t slot_key;
// 这里是要开辟的控件大小
size_t slot_bytes = segregated_size_to_fit(nanozone, size, &slot_key); // Note slot_key is set here
mag_index_t mag_index = nano_mag_index(nanozone);
nano_meta_admin_t pMeta = &(nanozone->meta_data[mag_index][slot_key]);
//这里是重点代码,这里又是另一部分库代码了
ptr = OSAtomicDequeue(&(pMeta->slot_LIFO), offsetof(struct chained_block_s, next));
//此处进入为部分容错处理
if (ptr) {...}
else {
ptr = segregated_next_block(nanozone, pMeta, slot_bytes, mag_index);
}
if (cleared_requested && ptr) {
memset(ptr, 0, slot_bytes); // TODO: Needs a memory barrier after memset to ensure zeroes land first?
}
return ptr;
我们看下开辟空间大小方法可以看到这里面做了个16字节对齐方法
static MALLOC_INLINE size_t
segregated_size_to_fit(nanozone_t *nanozone, size_t size, size_t *pKey)
{
// size = 40
size_t k, slot_bytes;
if (0 == size) {
// #define SHIFT_NANO_QUANTUM 4
// #define NANO_REGIME_QUANTA_SIZE (1 << SHIFT_NANO_QUANTUM) 这里是1往左4位 16
size = NANO_REGIME_QUANTA_SIZE; // Historical behavior
}
// 40 + 16-1 >> 4 << 4
// 40 - 16*3 = 48
// 16 4
// 这里其实就是做了一个16字节对齐
k = (size + NANO_REGIME_QUANTA_SIZE - 1) >> SHIFT_NANO_QUANTUM; // round up and shift for number of quanta
slot_bytes = k << SHIFT_NANO_QUANTUM; // multiply by power of two quanta size
*pKey = k - 1; // Zero-based!
return slot_bytes;
}
这篇文章中 iOS底层探索二(OC 中 alloc 方法 初探) 有对字节对齐算法进行解释,所以我么就能够理解,为什么malloc_size(t)的结果是48了;
内存优化总结:
有时候我们会思考为什么系统开辟的内存大小会大于我们申请的内存大小呢?按照8字节对齐的方式,申请的内存就可能已经存在多余的了。
- 按照8字节对齐方式,对象内部里面的成员内存地址是绝对安全的。
- 我们无法确定申请多余的字节就在对象与对象之间,有可能会出现在对象内存段的内部某个位置,这个时候就可能会出现两个对象内存段是挨着的情况,没有那么的安全。系统开辟空间采取16字节方式,保证对象的内存空间会更大,对象与对象之间更加的安全。
这里系统开辟为16字节对齐,是为了给类中,留部分空间进行容错的,其实这里也给了我们进行动态生成属性留下了一点空间!
说道内存优化了,顺带提一下,其实iOS系统还对我们编译器也有优化,例如我们在debug和release两种情况下,编译出来是有区别的,这里我们先通过简单的方法进行描述下:
如下代码:
//MARK: - 测试函数
int xzSum(int a, int b){
return a+b;
}
int main(int argc, const char * argv[]) {
int a = 10; //
int b = 20;
int c = a+b;
int d = xzSum(a,b);
NSLog(@"查看编译器优化情况:%d - %d",c,d);
return 0;
// @autoreleasepool {
// // Setup code that might create autoreleased objects goes here.
// }
// return NSApplicationMain(argc, argv);
}
我们首先打开汇编查看,Debug->DebugWorkflow->Always Show Disassembly,
我们修改下环境: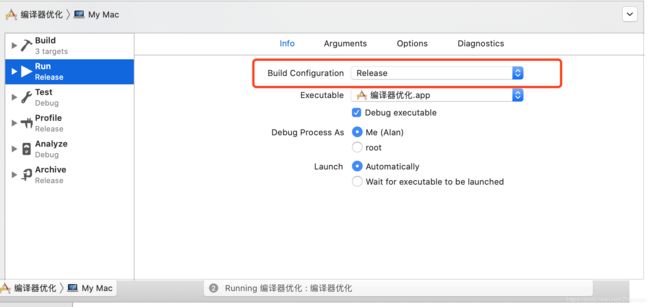
继续编译下:
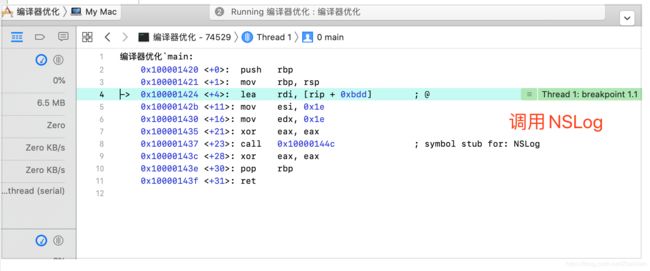
同样的代码,在release情况下和debug状态下,汇编代码少了很多,至少这个Demo中是直接缺少了xzSum方法的汇编,
我们可以在bulidsetting中查看到
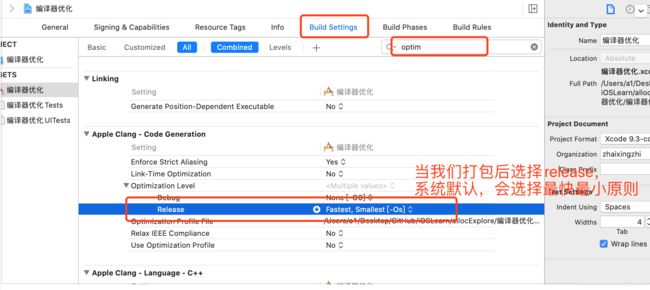
在编译的时候我们Release黄积极系统规模人会使用最快,最小原则,而Debug模式没有选择,这里我们也可以进行手动修改这几个模式!调试release中的部分问题;

总结
以上便是我对内存对齐,以及calloc代码的分析,如果有错误的地方还请指正,大家一起讨论,开发水平一般,还望大家体谅,
欢迎大家点赞,关注我的CSDN,我会定期做一些技术分享!
写给自己:
学如逆水行舟,不进则退,坚持到底,胜不胜利的不重要,但肯定不后悔!